背景
随着Android阵营的各大手机厂商对于续航的高度重视,两三年前的手机发布会更是把反保活作为一个系统的卖点,不断提出了各种反保活的方案,导致现在想实现应用保活简直难于上青天,甚至都需要一个团队来专门研究这个事情。
随着Android系统的不断升级,即时通讯网技术群和社区里的IM和推送开发的程序员们,对于进程保活这件事是越来越悲观,必竟系统对各种保活黑科技的限制越来越多了,想超越系统的挚肘,难度越来越大。
但保活这件事就像“激情”之后的余味,总是让人欲罢不能,想放弃又不甘心。那么,除了像《2020年了,Android后台保活还有戏吗?看我如何优雅的实现!》这样的正经白名单方式,不正经的“黑科技”是否还有发挥的余地?
答案是肯定的,“黑科技”仍发挥的余地。不是“黑科技”不行,而是技术没到位。
研究TIM的保活是一次偶然机会,发现在安全中心关闭了它的自启动功能的情况下, 一键清理、强力清理等各大招都无法彻底杀掉TIM,系统的自启动拦截也没能阻止TIM的永生。
一直以来,App 进程保活都是各大厂商,特别是头部应用开发商永恒的追求。毕竟App 进程死了,就什么也干不了了;一旦 App 进程死亡,那就再也无法在用户的手机上开展任何业务,所有的商业模型在用户侧都没有立足之地了。
早期的 Android 系统不完善,导致 App 侧有很多空子可以钻,因此它们有着有着各种各样的姿势进行保活。
譬如说在 Android 5.0 以前,App 内部通过 native 方式 fork 出来的进程是不受系统管控的,系统在杀 App 进程的时候,只会去杀 App 启动的 Java 进程;因此诞生了一大批“毒瘤”,他们通过 fork native 进程,在 App 的 Java 进程被杀死的时候通过 am命令拉起自己从而实现永生。
那时候的 Android 可谓是魑魅横行,群魔乱舞;系统根本管不住应用,因此长期以来被人诟病耗电、卡顿。同时,系统的软弱导致了 Xposed 框架、阻止运行、绿色守护、黑域、冰箱等一系列管制系统后台进程的框架和 App 出现。
不过,随着 Android 系统的发展,这一切都在往好的方向演变。Android 5.0 以上,系统杀进程以 uid 为标识,通过杀死整个进程组来杀进程,因此 native 进程也躲不过系统的法眼。
Android 6.0 引入了待机模式(doze),一旦用户拔下设备的电源插头,并在屏幕关闭后的一段时间内使其保持不活动状态,设备会进入低电耗模式,在该模式下设备会尝试让系统保持休眠状态。
Android 7.0 加强了之前鸡肋的待机模式(不再要求设备静止状态),同时对开启了 Project Svelte,Project Svelte 是专门用来优化 Android 系统后台的项目,在 Android 7.0 上直接移除了一些隐式广播,App 无法再通过监听这些广播拉起自己。
Android 8.0 进一步加强了应用后台执行限制:一旦应用进入已缓存状态时,如果没有活动的组件,系统将解除应用具有的所有唤醒锁。
Android 9.0 新增Adaptive Battery(电量自适应)可以最大限度的降低后台占用,从而提升电池续航能力
当你的麦克风、摄像头或传感器空闲时,应用程序将不再能够访问它们
JobScheduler可以使用运营商提供的网络状态信号来改善网络相关作业的处理
进一步改进了省电模式的功能并加入了应用待机分组,长时间不用的 App 会被打入冷宫;另外,系统监测到应用消耗过多资源时,系统会通知并询问用户是否需要限制该应用的后台活动。
Android 10.0 更严格的权限,并限制了数据应用程序的使用。有关如何在应用程序中支持这些功能的详细信息
另外,系统会限制未在前台运行的应用的某些行为,比如说应用的后台服务的访问受到限制,也无法使用 Mainifest 注册大部分隐式广播。
然而,道高一尺,魔高一丈。系统在不断演进,保活方法也在不断发展。
大约在 4 年前出现过一个 MarsDaemon,这个库通过双进程守护的方式实现保活,一时间风头无两。不过好景不长,进入 Android 8.0 时代之后,这个库就逐渐消亡。
一般来说,Android 进程保活分为两个方面:保持进程不被系统杀死。进程被系统杀死之后,可以重新复活。
随着 Android 系统变得越来越完善,单单通过自己拉活自己逐渐变得不可能了;因此后面的所谓「保活」基本上是两条路:1. 提升自己进程的优先级,让系统不要轻易弄死自己;2. App 之间互相结盟,一个兄弟死了其他兄弟把它拉起来。
当然,还有一种终极方法,那就是跟各大系统厂商建立 PY 关系,把自己加入系统内存清理的白名单;比如说国民应用微信。当然这条路一般人是没有资格走的。
大约一年以前,大神 gityuan 在其博客上公布了 TIM 使用的一种可以称之为「终极永生术」的保活方法;这种方法在当前 Android 内核的实现上可以大大提升进程的存活率。
这种保活思路的实现原理,并且提供了一个参考实现 Leoric。
接下来就给大家分享一下这个终极保活黑科技的实现原理。保活的底层技术原理知己知彼,百战不殆。既然我们想要保活,那么首先得知道我们是怎么死的。
一般来说,系统杀进程有两种方法,这两个方法都通过 ActivityManagerService 提供:killBackgroundProcessesforceStopPackage在原生系统上,很多时候杀进程是通过第一种方式,除非用户主动在 App 的设置界面点击「强制停止」。
不过国内各厂商以及一加三星等 ROM 现在一般使用第二种方法。第一种方法太过温柔,根本治不住想要搞事情的应用。第二种方法就比较强力了,一般来说被 force-stop 之后,App 就只能乖乖等死了。因此,要实现保活,我们就得知道 force-stop 到底是如何运作的,可以跟踪一下系统的 forceStopPackage 这个方法的执行流程
连微信这种超级APP,也要拜倒在反保活的石榴裙下,允许后台启动太费电,不允许后台启动就收不到消息。
Android发现了一个保活野路子就堵一条,然而很多场景是有保活的强需求的,有木有考虑过我们开发者的感受,自己人何必为难自己人😭。
这是一个Android设计的不合理的地方,路子可以堵,但还是有必要留一个统一的保活接口的。这个接口由Google实现也好,厂商来实现也好,总好过现在很笨拙的系统自启动管理或者是JobScheduler。
从本质上来说,让应用开发者想尽各种办法去做保活,这个事情是没有意义的,保活的路子被封了,但保活还是需要做,保活的成本也提高了,简直浪费生命。Android的锅。
保活是”应用的蜜罐,系统的肿瘤“,应用高保活率给自己赢得在线时长,甚至做各种应用想做而用户不期望的行为,给系统带来的是不必要的耗电,以及系统额外的性能负担。
保活技术阶段回顾
Android保活技术的进化,可以分为几个阶段。
第一个阶段:
也就是各种“黑科技”盛行的时代,比如某Q搞出来的1像素、后台无声音乐(某运动计步APP就干过)等等。
这个阶段的一些典型主要技术手段,可以看以下这几篇文章:
- 《应用保活终极总结(一):Android6.0以下的双进程守护保活实践》
- 《Android进程保活详解:一篇文章解决你的所有疑问》
- 《微信团队原创分享:Android版微信后台保活实战分享(进程保活篇)》
第二个阶段:
到了Android 6.0时代以后,Android保活就开始有点技术难度了,之前的各种无脑保活方法开始慢慢失效。
这个阶段的一些典型技术手段,可以读读以下这几篇文章:
第三个阶段:
进入Android 8.0时代,Android直接在系统层面进行了各种越来越严格的管控,可以用的保活手段越来越少,保活技术的发展方向已发分化为两个方向——要么用白名单的方式走正经的保活路径、要么越来越“黑”一“黑”到底(比如本文将要介绍的TIM的保活手段)。
这个阶段可以用的保活已经手段不多了,以下几篇盘点了目前的一些技术可行性现状等:
- 《Android P正式版即将到来:后台应用保活、消息推送的真正噩梦》
- 《全面盘点当前Android后台保活方案的真实运行效果(截止2019年前)》
- 《2020年了,Android后台保活还有戏吗?看我如何优雅的实现!》
什么是保活?
保活就是在用户主动杀进程,或者系统基于当前内存不足状态而触发清理进程后,该进程设法让自己免于被杀的命运或者被杀后能立刻重生的手段。
保活是”应用的蜜罐,系统的肿瘤“,应用高保活率给自己赢得在线时长,甚至做各种应用想做而用户不期望的行为,给系统带来的是不必要的耗电,以及系统额外的性能负担。
保活方案一直就层出不穷,APP开发们不断地绞尽脑汁让自己的应用能存活得时间更长, 主要思路有以下两个。
提升进程优先级,降低被杀概率:
- 1)比如监听SCREEN_ON/OFF广播,启动一像素的透明Activity;
- 2)启动空通知,提升fg-service;
- … …
进程被杀后,重新拉起进程:
- 1)监听系统或者第3方广播拉起进程。但目前安全中心/Whetstone已拦截;
- 2)Native fork进程相互监听,监听到父进程被杀,则通过am命令启动进程。force-stop会杀整个进程组,所以这个方法几乎很难生效了。
规纳如下
- 提升进程优先级,降低被杀概率
- 比如监听SCREEN_ON/OFF广播 启动一像素的透明Activity
- 启动空通知,提升fg-service
- 进程被杀后,重新拉起进程
- 监听系统或者第3方广播拉起进程。目前安全中心/Whetstone已拦截
- Native fork进程相互监听,监听到父进程被杀,则通过am命令启动进程。force-stop会杀整个进程组,几乎很难生效
如何实现
通过ioctl跟binder驱动交互,实现以最快的方式唤醒新的保活服务,最大程度防止保活失败。
关于binder
如果从Android层开始,一层套一层,会让我们迷茫不知所措。而ioctl才是驱动整个binder运行的引擎。
我们可以不用binder,可以实现另外一种类似binder的机制,通过ioctl可以觉察到整个的数据流向,本来进程通信表面意思就是进程间传递数据,不围绕数据的流向,常常会迷失在大量的接口类中不知所措。
使用binder
ioctl 根据第二个参数,确定BINDER WRITE READ,然后阅读相关的linux驱动源码,解析参数。
进程间传递数据发送方要把指针放在其中。binder_transaction_data,如果A进程要发送数据给B,那么填充方式就是在write_buffer中写入数据的指针。
看上去binder是双工的,每一个进程通过调用ioctl既可以发送数据也可以收到数据,在ioctl执行前hook只能得到发送的数据,执行后即可得到接收的数据。所以binder的read_buffer就相当于socket的recvfrom write_buffer相当于socket的sendto*
进程之间的通信和进程服务之间的通信好像并不完全一样,而大部分资料介绍的几乎都是进程和服务之间的通信。这里通过A向B发送数据来看下binder底层是如何工作的。*
首先A生成write_buffer:binder_transaction_data,标记为BC_TRANSACTION,数据指针中保存实际的数据。调用ioctl,binder驱动保存数据后填充read_buffer为BR_TRANSACTION_COMPLETE,虽然数据还没有到B,但是已经到了驱动中,就算是成功了。*
然后通过某些方法告诉B可以接收数据了,测试发现,B填充的read_buffer中填充了BR_TRANSACTION_COMPLETE write_buffer中填充了BC_FREE_BUFFER是否有意义*?然后B调用ioctl,binder驱动填充read_buffer* ,标记为BR_REPLY 表示成功接收到了数据*
进程保活原理
Gityuan大佬曾放出了一份分析TIM的黑科技保活的博客 史上最强Android保活思路:深入剖析腾讯TIM的进程永生技术
(后来不知道什么原因又删除了),顿时间掀起了一阵波澜,仿佛让开发者们又看到了应用保活的一丝希望。
Gityuan大佬通过超强的专业技术分析,为我们解开了TIM保活方案的终极奥义。
后来,为数不多的维术大佬在Gityuan大佬的基础上,发布了博客 Android 黑科技保活实现原理揭秘
又进行了系统进程查杀相关的源码分析。为我们带来的结论是,Android系统杀应用的时候,会去杀进程组,循环 40 遍不停地杀进程,每次杀完之后等 5ms。
引用维术的话语,原理如下:
- 利用Linux文件锁的原理,使用2个进程互相监听各自的文件锁,来感知彼此的死亡。
- 通过 fork 产生子进程,fork 的进程同属一个进程组,一个被杀之后会触发另外一个进程被杀,从而被文件锁感知。
具体来说
创建 2 个进程 p1, p2,这两个进程通过文件锁互相关联,一个被杀之后拉起另外一个;同时 p1 经过 2 次 fork 产生孤儿进程 c1,p2 经过 2 次 fork 产生孤儿进程 c2,c1 和 c2 之间建立文件锁关联。这样假设 p1 被杀,那么 p2 会立马感知到,然后 p1 和 c1 同属一个进程组,p1 被杀会触发 c1 被杀,c1 死后 c2 立马感受到从而拉起 p1,因此这四个进程三三之间形成了铁三角,从而保证了存活率。
按照维术大佬的理论:
** 只要进程我复活的足够快,系统它就杀不死我 **
维术大佬写了一个简单的实现: github.com/tiann/Leoric 这个方案是当检测到进程被杀时,会通过JNI的方式,调用Java层的方法来复活进程。为了实现稳定的保活,尤其是系统杀进程只给了5ms复活的机会,使用JNI这种方式复活进程现在达不到最优的效果。
分析TIM
执行命令adb shell ps | grep tencent.tim,可见TIM共有4个进程, 其父进程都是Zygote
1 | ps | grep tencent.tim |
一键清理看现象,排查初步怀疑
以下是对TIM执行一键清理后的日志:
1 | 12-21 21:12:20.265 1053 1075 I am_kill : [0,4892,com.tencent.tim:Daemon,5,stop com.tencent.tim: from pid 4617] |
1 | MIUI |
Force-stop是系统提供的杀进程最为彻底的方式,详见文章Android进程绝杀技–forceStop。从日志可以发现一键清理后TIM的4个进程全部都已被Force-stop。但进程com.tencent.tim:MSF立刻就被DaemonMsfService服务启动过程而拉起。
问题1:安全中心已配置了禁止TIM的自启动, 并且安全中心和系统都有对进程自启动以及级联启动的严格限制,为何会有漏网之鱼?
怀疑1: 是否安全中心自启动没能有效限制,以及微信/QQ跟TIM有所级联,比如com.tencent.mobileqq.app.DaemonMsfService服务名中以com.tencent.mobileqq(QQ的包名)开头,经过dumpsys以及反复验证后排除了这种可能性,如下:
1 | 12-21 21:12:20.266 1053 1075 I AutoStartManagerService: MIUILOG- Reject RestartService packageName :com.tencent.tim uid : 10146 |
怀疑2: 是否在TIM进程被杀后, 收到BinderDied后的死亡回调过程中将Service再次拉起,这个情况也很快就被排除, 因为force-stop这种冷面强力杀手, 并不会等到死亡回调再去清理进程相关信息,而是直接连根拔起,并不会走到AMS的死亡回调。
怀疑3: TIM设置了alarm机制,在callApp为空符合特征, 但经过分析这里就是普通的startService, 非startServiceInPackage(), 也排除了这种可能性
1 | //启动DaemonAssistService时,callApp为空,只有通过PendingIntent方式才可能出现这种情况 |
既然排除以上3种可能,直接上断点来看看吧
Android Studio断点分析
一上断点就发现了意外的一幕:
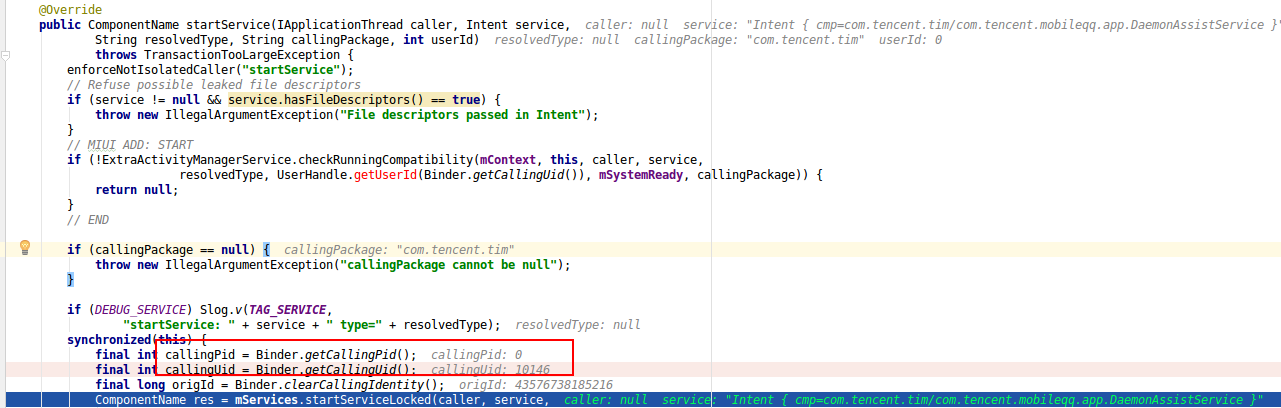
问题2:startService()的callingPid怎么可能等于0?
分析callingPid=0
为什么说上面是意外的一幕呢?这需要对binder底层原理有一定深入理解,才能看出一些端倪,那就是此处callingPid=0是不合理逻辑的。很多人可能不太理解为何就不合乎逻辑, 这要从Binder原理说起, startService()这个Binder call是属于同步binder调用, 对于binder调用过程,只有异步Binder调用的情况下callingPid=0才会为空, 因为不需要reply应答数据给发送binder请求的那一端。 但如果是同步的,则必须要给出callingPid,否则无法将应答数据回传给发送方。 这是由Binder Driver所决定的,见如下Binder Driver核心代码:
(1)Binder发起端:根据当前ONE_WAY来决定是否设置from线程
1 | binder_transaction(...) { |
(2)Binder接收端: 根据from线程是否为空, 来决定sender_pid是否为0. 这便是Java层所说的callingPid
1 | binder_thread_read(...) { |
上述代码表明: 同步的Binder调用的情况下则callingPid必定不等于0
下面告诉大家如何看一个Binder调用是否同步, 如下图最后一个参数代表的是FLAG_ONEWAY值,等于0则代表的是同步, 等于1则代表的是异步。
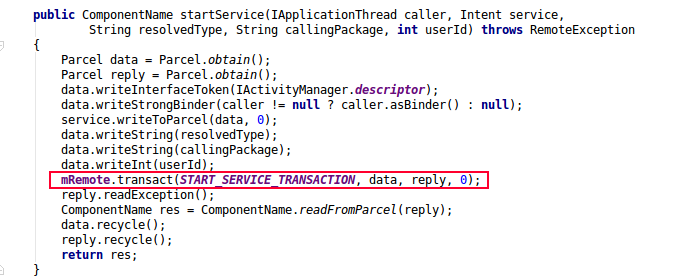
以上代码是framework的框架代码,startService最终都会调用到这里来,所以callingPid必然是不可能出现为0的情况,让我们看不透到底哪个进程把com.tencent.tim:Daemon拉起的。
揭秘
从前面的分析来看callingPid是不可能为0的, 但从结果来看的确是0, 出现矛盾就一定有反常规存在,难道是存在同步的Binder调用,也存在同时callingPid=0的case?答案是No.
从源码角度来看是没有这种可能性存在,后面再进一步追踪flags值的变化,从如下的flags=17,可以确定的是此处的startService的binder call是ONE_WAY的,这就可以确定的确是发起了异步的Binder调用,代码如下:
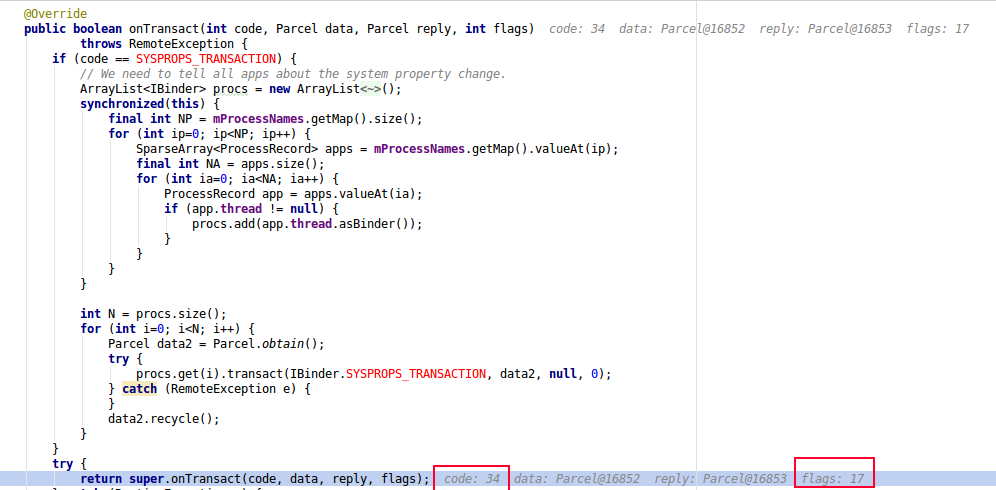
虽然callingPid=0,但从callUid=10146可以确定的一点是com.tencent.tim:Daemon进程是被来自TIM应用自身的某个进程所拉起的。
小结
通过前面的初步分析,先整理一下思路,有以下初步结论:
- TIM至少有4个进程,且都是由Zygote进程fork, 保活是通过startService被拉起
- 排除 安全中心的对TIM限制自启动功能失效的情况
- 排除 TIM进程被杀后的Binder死亡回调过程通过Service重新拉起进程
- 排除 alarm机制 拉起进程
- 从callingPid=0,可以得出TIM没有走常规的系统框架中提供的startService()接口来启动服务,而是自定义的方式
- 从callingUid=10146, 可以得出TIM救活自己的方式,是通过TIM自身,而非系统或者第三方应用拉起
到此不难得出一个猜想: 首先TIM应用能做到监听应用进程被杀的情况, 其次是TIM应用自身替换掉或者自定义一套Binder调用,主动跟Binder驱动进行数据交互。
深入分析
寻求规律
TIM应用有4个进程,不断反复地尝试杀TIM每一个进程后,观察自启动的情况后。 发现了一个规律:com.tencent.tim:Daemon和com.tencent.tim:MSF进程任一被杀,都会先把对方进程拉起,然后跟着自杀后,再重启。
接下来就把范围锁定在这两个进程,然后来tracing信号处理情况。
从signal角度来分析
打开signal开关
1 | echo 1 > /d/tracing/events/signal/enable |
执行如下命令抓取tracing log
1 | cat /d/tracing/trace_pipe |
日志如下:
1 | //通过adb shell kill -9 10649, 将com.tencent.tim:Daemon进程杀掉 |
从这里,可以发现com.tencent.tim:Daemon进程是由于其中一个线程Thread-89所杀,但从名字来看Thread-xxx,很明显是系统自动生成的编号。
问题3:进程内的名叫“Thread-89”的线程具有什么特点,如何做到把进程杀掉?
从下面的截图,可以看出MSF进程的这个特殊的线程当前在执行flock_lock操作,这个明显是一个文件加锁的操作, 这个方法很快就引起了我的注意。同理Daemon进程也有一个这样的线程, 离真相有近了一步。
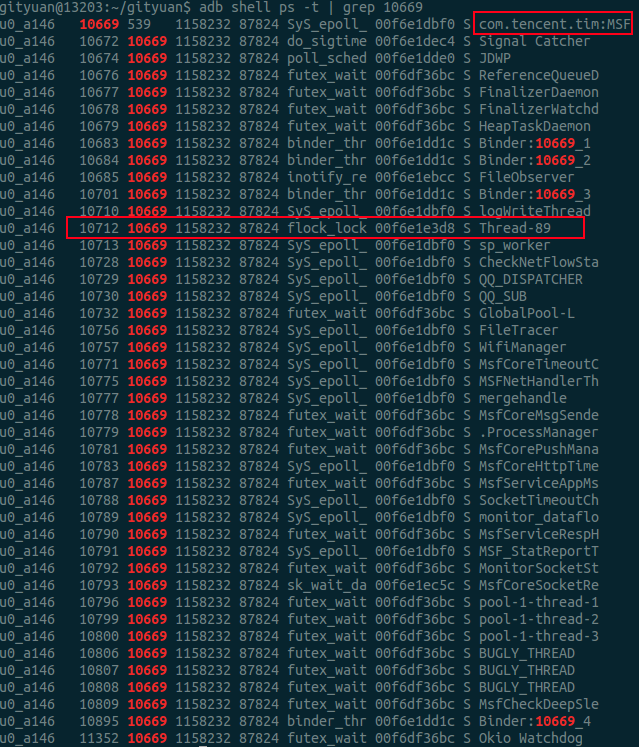
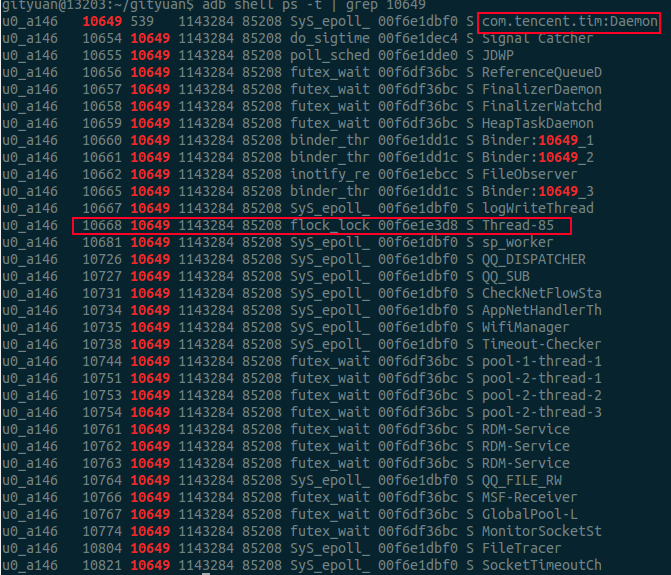
再来看看调用栈情况
1 | Cmd line: com.tencent.tim:Daemon |
从这个线程的调用栈中的名字, notify_and_waitfor让我想到了这极有可能用于监听文件来获知进程是否存活。 为了进一步观察这个特殊线程的工作使命, 这里还不需要GDB, 祭出strace大招应该就差不多
利用strace分析
strace -CttTip 22829 -CttTip 22793
结果如下:

flock基础知识简介:
flock是Linux文件锁,用于多个进程同时操作同一个文件时,通过加锁机制保证数据的完整,flock使用场景之一,便是用于检测进程是否存在。flock属于建议性的锁,而非强制性锁,只是进程可以直接操作正被另一个进程用flock锁住的文件, 原因在于flock只检测文件是否加锁,内核并不会强制阻塞其他进程的读写操作,这便是建议性锁的内核策略。
方法原型: int flock(int fd, int operation)
第一个参数是文件描述符,第二参数指定锁的类型,有以下3个可选值:
- LOCK_SH: 共享锁, 同一时间运行多个进程同时持有该共享锁
- LOCK_EX: 排它锁,只允许一个进程持有该锁
- LOCK_UN: 移除该进程的该文件所持有的锁
从strace可以推测出:com.tencent.tim:MSF进程的监控线程执行排它锁LOCK_EX类型的flock,尝试去获取某个文件,而该文件已被com.tencent.tim:Daemon进程所持有,所以MSF进程会被阻塞知道锁的释放,而一旦Daemon进程被杀,系统就会回收所有资源(包括文件),这是Linux内核负责完成的。
当Daemon进程的文件被回收,就会释放flock, 从而MSF进程可以获取该锁,从而吐出“lock file success”的信息。 MSF得知Daemon进程被杀,然后执行一行ioctl(11, BINDER_WRITE_READ, 0xffffffffee823ed0) = 0 <0.000867> ,
这个应该就是TIM进程自身实现了一套执行startService的Binder调用,向Binder驱动发送 BINDER_WRITE_READ的ioctl命令。 再然后发送kill SIGKILL将自身MSF进程杀掉,同样的道理可以再次被拉起。
分析到这里,看执行了writev操作, 应该就是Log操作, 有一个关键词到Watermelon吸引了我的注意力, 搜索Watermelon关键词,果然找到新的一片天地。
TIM日志
1 | //旧的MSF进程 |
再从其中的截取核心片段:
1 | 25159 25159 I Watermelon: BpActivityManager init |
不难看出:
- TIM自身通过向servicemanager查询来获取AMS的代理BpActivityManager, 然后自己去写startService通信过程的数据
- TIM通过两个进程通过flock来相互监听对方进程存活状态
- 监听的文件有比如:/data/user/0/com.tencent.tim/app_indicators/indicator_d2
indicator文件
进一步查看TIM所监听的路径下/data/user/0/com.tencent.tim/app_indicators/, 发现有4个监听文件:

问题4:为何需要4个indicator文件?
进一步延伸:通过查看flock,再次发现新大陆,原来除了Daemon和MSF进程各有一个监听文件的线程, 还有两个由init进程作为父进程的app_d进程也监听文件
1 | adb shell ps -t | grep -i flock |
不难发现,以上几个进程/线程的uid=10146,进一步通过ps命名查找。
再一次刷新对TIM应用的认识: 原来TIM有6个进程,其中还有2个是挂在init进程下,名字跟tencent没有关系,差点错过了这两个特殊的进程

这两个app_d进程其实也是做着同样的相互监听的工作, 应该是备选方案。当有概率恰巧Daemon和MSF进程同时被杀而来不及互保的情况下,那么可以走紧急通道app_d 将TIM进程拉起。可谓是暗藏玄机, 6个进程中有4个进程可以相互保活, 以保证TIM进程永生。
问题5: 这4个进程到达是什么如何相互监听的呢?
通过不断分析被杀与重启前后的规律与特征,得出进程与监听文件的关系图:
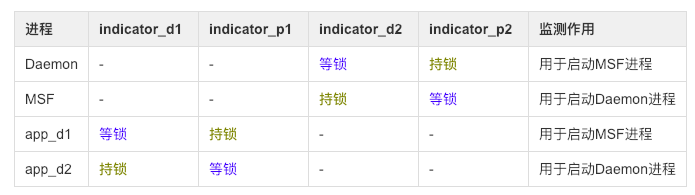
进一步揭露面纱,得到如下结论:
- Daemon与MSF两进程等待对方所持有的锁,两个app_d进程相互等待对方所持有的锁
- app_d1进程被杀, 则app_d2观察后通过拉起DaemonMsfService服务来启动MSF进程,然后跟着被杀
- app_d2进程被杀,则app_d1观察后通过拉起DaemonAssistService服务来启动Daemon进程,然后跟着被杀
- Daemon与MSF两进程, 如果杀掉其中一个,则另个一个进程观察后通过拉起服务方式来启动对方进程,然后跟着被杀;然后app_d两个进程也跟着重启
另外,猜想:监测indicator_p1和indicator_p2的两个进程有关联,indicator_d1和indicator_d2的进程有关联,后面会验证。
到这里又有出现新的疑问,Daemon进程死后,MSF进程通过flock能监测到该事件,可是app_d进程又是如何得知的呢? app_d得知之后,又为何要再次自杀重启?
从cgroup角度来分析
1 | cat cgroup.procs |
从而,进一步获取更多关于TIM深层次的关联,通过查看cgroup发现,Daemon和app_d1是同一个group的, MSF和app_d2是同一个group的。
问题6: app_d到底是如何创建出来?又是如何成为init进程的子进程的?
从进程创建与退出的角度来看看来看
1 | // 5170(MSF进程) --> 5192 --> 5201(退出) --> 5211(存活) |
说明:其中一个app_d进程是由MSF进程,通过两次fork,然后父进程退出,从而成为了孤儿进程,然后托孤给init进程,这是Linux进程机制所保证的。 同理,另一个app_d进程是由Daemon进程所fork。到这里,那么总算是认清的app_d的由来。 app_d是由于cgroup关联所以可以得知Daemon进程的情况。 关于重启的原因是为了重新建立互动的关系
问题7:为何单杀daemon,会牵连app_d进程被杀,这是什么原理?
解答:从杀进程的日志上来是调用killProcessGroup()杀进程,可事实上adb只调用kill -9 pid的方式,单杀一个进程,怎么就牵连了app_d进程。 这是由于当daemon进程被杀后,死亡回调会回来后,在binderDied()的过程执行了killProcessGroup()。
如果从Linux内核层面,研究过Binder死亡回调机制的童鞋,到这里还就会有想到一个新的疑问如下:
问题8:app_d是由daemon进程间接fork出来的, 会共享binder fd,所以即便daemon进程被杀,死亡回调也不会触发,这又是何触发的呢?
解答:由于app_d进程被fork后,马上执行了exec()系的函数, 而在ProcessState打开Binder驱动的时候, 有一个非常重要的flag, 那就是O_CLOEXEC。
采用O_CLOEXEC方式打开的问题,当新创建的进程调用exec()函数成功后,文件描述符会自动关闭, 代码如下:
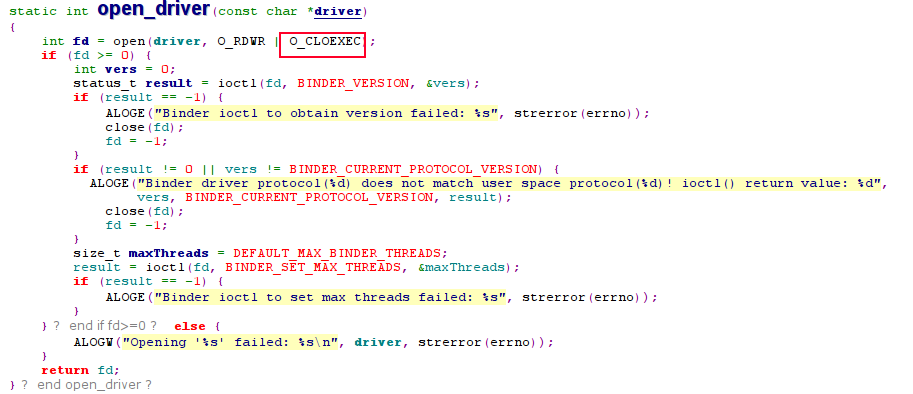
剖根问底
问题9:TIM到底对Binder框架做了什么级别的修改?这4个互保进程,既然callingPid=0,有没有办法知道到底是由谁拉起谁的?
前面既然说了,TIM强行修改了ONEWAY的方式。可以去掉该flags, 为了调试,这里就针对TIM,并且code=34(即START_SERVICE_TRANSACTION), 并且修改flag的case下:
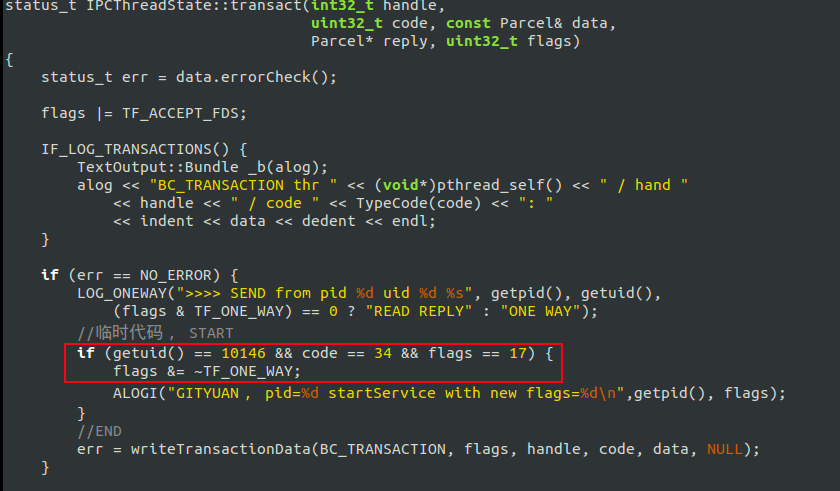
从实验结果来看,通过修改IPCThreadState.cpp代码, 完成control住了 TIM的所有修改, 这里可以说明:
TIM分别在Java层和Native层,主动向ServiceManager进程查询AMS后,获取BpActivityManager代理对象,然后继续使用框架中的IPCThreadState跟Binder驱动交互,并没有替换掉libbinder.so。
其实,还可以更高级的玩法,连IPCThreadState这些框架通信代码也不使用, 彻底地去自定义Binder交互代码,类似于servicemanager的方式。可以自己封装ioctl(),直接talkWithDriver。TIM保活还有改进空间, 提供保活变种方案,这样的话,上面的调试代码也拦截不了其对flags修改为ONEWAY的过程。 即使如此,一切都在Control之中, 完全可以在Binder Driver中拦截再定位其策略, 玩得再高级也主要活动在用户态, 内核态的策略还是相对安全的, 此所谓“魔高一座,道高一尺”。
另外,通过增加上面的临时代码,再次多次实验对比,可以得出如下关系图:
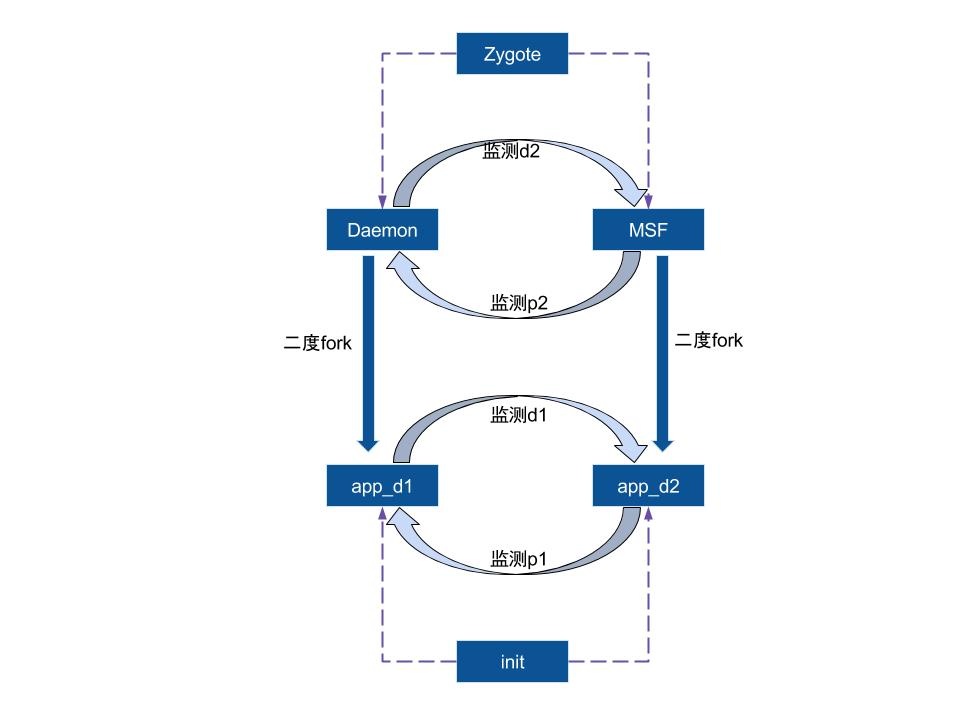
二度fork是指前面介绍了,fork后再fork,然后托孤,无论如何跟最初的进程都属于同一个group,有着级联被杀关系。
- 杀掉Daemon进程,则MSF进程观察到会去拉起Daemon进程; 同时app_d1因为同一个group而被杀,则app_d2进程观察到也拉起Daemon进程,这就是双保险;
- 杀掉app_d1进程, 则app_d2进程观察到会拉起MSF进程;
- 直接force-stop进程, 则6个进程都会被杀,只是杀的过程并非所有进程同一时刻点被杀,而是有前后顺序,所以造成能自启。
分析思路归纳
- 先有了初步分析过程中对一些常规套路的可能性的排除,并嗅到callingPid=0的异常举动
- 沿着蛛丝马迹,不断反复尝试杀进程,从中寻找更多的规律,不断地向自己提出疑问
- 结合signal,strace, traces,ps,binder,linux,kill等技能 不断地解答自己的疑惑
解系统层的问题,更像是侦探破案的感觉,要有敏锐的嗅觉,抓住蛛丝马迹,加上”大胆猜想,小心验证“ , 终究能找到案件的真相。 此所谓”点动成线,线动成面,面动成体“, 从零星的点滴勾画出全方面立体化的真相。
归纳下,主要提出过这些疑惑:
问题1:安全中心已配置了禁止TIM的自启动, 并且安全中心和Whetstone都有对进程自启动以及级联启动的严格限制, 为何会有漏网之鱼?
问题2:startService()的callingPid怎么可能等于0?
问题3:进程内的名叫“Thread-89”的线程具有什么特点,如何做到把进程杀掉?
问题4:为何需要4个indicator文件?
问题5:这4个进程到达是什么如何相互监听的呢?
问题6:app_d到底是如何创建出来?又是如何成为init进程的子进程的?
问题7:为何单杀daemon,会牵连app_d进程被杀,这是什么原理?
问题8:app_d是由daemon进程间接fork出来的, 会共享binder fd,所以即便daemon进程被杀,死亡回调也不会触发,这又是何触发的呢?
问题9:TIM到底对Binder框架做了什么级别的修改?这4个互保进程,既然callingPid=0,有没有办法知道到底是由谁拉起谁的?
总结以上理论
保活技术点
- 通过flock的文件排它锁方式来监听进程存活状态
- 先采用一对普通的进程Daemon和MSF相互监听文件的方式来获得对方进程是否存活的状态;
- 同时再采用一对退孤给init进程的app_d进程相互监听文件的方式来获得对方进程是否存活的状态; 而这两个进程都有间接由Daemon和MSF进程所fork而来;双重保险
- 不采用系统框架中startService的Binder框架代码,而是自身在Native层通过自己去查询获取BpActivityManager代理对象, 然后自己实现startService接口,并修改为ONEWAY的binder调用,既增加分析问题的难度,也进一步隐藏自身策略;
- 当监听进程死亡,则通过自身实现的StartService的Binder call去拉起对方进程,系统对于这种方式启动进程并没有拦截机制。
这种flock的方式至少比网上常说的通过循环监听的方式,要强很多;比往常的互保更厉害的是TIM共有6个进程(说明:使用过程也还会创建一些进程),其中4个进程,形成两组互动进程,其中一组利用Linux进程托孤原理,可谓是隐藏得很深来互保,进一步确保进程永生; 当然,进程收到signal信号后,如果恰巧这四个进程在同一个时刻点退出,那么还是有概率会被杀。 不走系统框架代码,自己去实现启动服务的binder call也是一大亮点,不过还有更高级的玩法,直接封装ioctl跟驱动交互。之前针对这个问题,做过反保活方案,后来为了某些功能缘故又放开对这个的限制,这里就不再继续展开了。
附录:有关IM/推送的进程保活/网络保活方成的文章汇总
《应用保活终极总结(一):Android6.0以下的双进程守护保活实践》
《应用保活终极总结(二):Android6.0及以上的保活实践(进程防杀篇)》
《应用保活终极总结(三):Android6.0及以上的保活实践(被杀复活篇)》
《Android进程保活详解:一篇文章解决你的所有疑问》
《Android端消息推送总结:实现原理、心跳保活、遇到的问题等》
《深入的聊聊Android消息推送这件小事》
《为何基于TCP协议的移动端IM仍然需要心跳保活机制?》
《微信团队原创分享:Android版微信后台保活实战分享(进程保活篇)》
《微信团队原创分享:Android版微信后台保活实战分享(网络保活篇)》
《移动端IM实践:实现Android版微信的智能心跳机制》
《移动端IM实践:WhatsApp、Line、微信的心跳策略分析》
《Android P正式版即将到来:后台应用保活、消息推送的真正噩梦》
《全面盘点当前Android后台保活方案的真实运行效果(截止2019年前)》
《一文读懂即时通讯应用中的网络心跳包机制:作用、原理、实现思路等》
《融云技术分享:融云安卓端IM产品的网络链路保活技术实践》
《正确理解IM长连接的心跳及重连机制,并动手实现(有完整IM源码)》
《2020年了,Android后台保活还有戏吗?看我如何优雅的实现!》
《史上最强Android保活思路:深入剖析腾讯TIM的进程永生技术》
《Android进程永生技术终极揭密:进程被杀底层原理、APP对抗被杀技巧
实际实现
Java 层复活进程
复活进程,其实就是启动指定的Service。当native层检测到有进程被杀时,为了能够快速启动新Service。我们可以通过反射,拿到ActivityManager的remote binder,直接通过这个binder发送数据,即可实现快速启动Service。
1 | Class<?> amnCls = Class.forName("android.app.ActivityManagerNative"); |
启动Service的Intent:
1 | Intent intent = new Intent(); |
封装启动Service的Parcel:
1 | Parcel mServiceData = Parcel.obtain(); |
启动Service:
1 | mRemote.transact(transactCode, mServiceData, null, 1); |
在 native 层进行 binder 通信
在Java层做进程复活的工作,这个方式是比较低效的,最好的方式是在 native 层使用纯 C/C++来复活进程。方案有两个。
** 其一 **,维术大佬给出的方案是利用libbinder.so, 利用Android提供的C++接口,跟ActivityManagerService通信,以唤醒新进程。
- Java 层创建 Parcel (含 Intent),拿到 Parcel 对象的 mNativePtr(native peer),传到 Native 层。
- native 层直接把 mNativePtr 强转为结构体指针。
- fork 子进程,建立管道,准备传输 parcel 数据。
- 子进程读管道,拿到二进制流,重组为 parcel。
** 其二 **,Gityuan大佬则认为使用 ioctl 直接给 binder 驱动发送数据以唤醒进程,才是更高效的做法。然而,这个方法,大佬们并没有提供思路。
通过实现在 native 层进行 Binder 调用的骚操作来实现进程保活。
方式一 利用 libbinder.so 与 ActivityManagerService 通信
在Java层是向ActivityManagerService发送特定的封装了Intent的Parcel包来实现唤醒进程。而在native层,没有Intent这个类。所以就需要在Java层创建好Intent,然后写到Parcel里,再传到Native层。
1 | Parcel mServiceData = Parcel.obtain(); |
可以看到,Parcel类有一个mNativePtr变量:
1 | private long mNativePtr; // used by native code |
可以通过反射得到这个变量:
1 | private static long getNativePtr(Parcel parcel) { |
这个变量对应了C++中 Parcel类 的地址,因此可以强转得到Parcel指针:
1 | Parcel *parcel = (Parcel *) parcel_ptr; |
然而,NDK中并没有提供binder这个模块,我们只能从Android源码中扒到binder相关的源码,再编译出libbinder.so。腾讯TIM应该就是魔改了binder相关的源码。
提取libbinder.so
为了避免libbinder的版本兼容问题,这里我们可以采用一个更简单的方式,拿到binder相关的头文件,再从系统中拿到libbinder.so,当然binder模块还依赖了其它的几个so,要一起拿到,不然编译的时候会报链接错误。
1 | adb pull /system/lib/libbinder.so ./ |
如果需要不同SDK版本,不同架构的系统so库,可以在 Google Factory Images 网页里找到适合的版本,下载相应的固件,然后解包system.img(需要在windows或linux中操作),提取出目标so。
1 | osx下解压img |
1 | ls -l binder_libs |
为了避免兼容问题,这里只让这些so参与了binder相关的头文件的链接,而没有实际使用这些so。这是利用了so的加载机制,如果应用lib目录没有相应的so,则会到system/lib目录下查找。
SDK24以上,系统禁止了从system中加载so的方式,所以使用这个方法务必保证targetApi <24。
否则,将会报找不到so的错误。可以把上面的so放到jniLibs目录解决这个问题,但这样就会有兼容问题了。
CMake修改:
1 | # 链接binder_libs目录下的所有so库 |
进程间传输Parcel对象
Parcel能直接拿到数据地址,并提供了构造方法。所以我们可以通过管道把Parcel数据传输到其它进程。
1 | Parcel *parcel = (Parcel *) parcel_ptr; |
重新创建Parcel:
1 | Parcel parcel; |
传输Parcel数据
1 | // 获取ServiceManager |
方式二 使用 ioctl 与 binder 驱动通信
尝到了一点甜头,实现了大佬的思路,不禁让鄙人浮想联翩,感慨万千,鄙人的造诣已经如此之深,不久就会人在美国,刚下飞机,迎娶白富美,走向人生巅峰矣……
ioctl是一个linux标准方法,那么我们就直奔主题看看,binder是什么,ioctl怎么跟binder driver通信。
Binder介绍
Binder是Android系统提供的一种IPC机制。每个Android的进程,都可以有一块用户空间和内核空间。用户空间在不同进程间不能共享,内核空间可以共享。Binder就是一个利用可以共享的内核空间,完成高性能的进程间通信的方案。
Binder通信采用C/S架构,从组件视角来说,包含Client、Server、ServiceManager以及binder驱动,其中ServiceManager用于管理系统中的各种服务。如图:

注册服务、获取服务、使用服务,都是需要经过binder通信的。
- Server通过注册服务的Binder通信把自己托管到ServiceManager
- Client端可以通过ServiceManager获取到Server
- Client端获取到Server后就可以使用Server的接口了
Binder通信的代表类是BpBinder(客户端)和BBinder(服务端)。
ps:有关binder的详细知识,大家可以查看Gityuan大佬的文章。
Binder系列
ioctl函数
ioctl(input/output control)是一个专用于设备输入输出操作的系统调用,它诞生在这样一个背景下:
操作一个设备的IO的传统做法,是在设备驱动程序中实现write的时候检查一下是否有特殊约定的数据流通过,如果有的话,后面就跟着控制命令(socket编程中常常这样做)。但是这样做的话,会导致代码分工不明,程序结构混乱。所以就有了ioctl函数,专门向驱动层发送或接收指令。
Linux操作系统分为了两层,用户层和内核层。我们的普通应用程序处于用户层,系统底层程序,比如网络栈、设备驱动程序,处于内核层。为了保证安全,操作系统要阻止用户态的程序直接访问内核资源。一个Ioctl接口是一个独立的系统调用,通过它用户空间可以跟设备驱动沟通了。函数原型:
1 | int ioctl(int fd, int request, …); |
作用:通过IOCTL函数实现指令的传递
- fd 是用户程序打开设备时使用open函数返回的文件描述符
- request是用户程序对设备的控制命令
- 后面的省略号是一些补充参数,和cmd的意义相关
应用程序在调用ioctl进行设备控制时,最后会调用到设备注册struct file_operations结构体对象时的unlocked_ioctl或者compat_ioctl两个钩子上,例如Binder驱动的这两个钩子是挂到了binder_ioctl方法上:
1 | static const struct file_operations binder_fops = { |
它的实现如下:
1 | static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg){ |
具体内核层的实现,我们就不关心了。到这里我们了解到,Binder在Android系统中会有一个设备节点,调用ioctl控制这个节点时,实际上会调用到内核态的binder_ioctl方法。
为了利用ioctl启动Android Service,必然是需要用ioctl向binder驱动写数据,而这个控制命令就是BINDER_WRITE_READ。binder驱动层的一些细节我们在这里就不关心了。那么在什么地方会用ioctl 向binder写数据呢?
IPCThreadState.talkWithDriver
阅读Gityuan的
Binder系列6—获取服务(getService)
一节,在binder模块下
IPCThreadState.cpp
中有这样的实现(源码目录:frameworks/native/libs/binder/IPCThreadState.cpp):
1 | status_t IPCThreadState::talkWithDriver(bool doReceive) { |
可以看到ioctl跟binder driver交互很简单,一个参数是mProcess->mDriverFD,一个参数是BINDER_WRITE_READ,另一个参数是binder_write_read结构体,很幸运的是,NDK中提供了linux/android/binder.h这个头文件,里面就有binder_write_read这个结构体,以及BINDER_WRITE_READ常量的定义。
[惊不惊喜]
[意不意外]
[手动滑稽]
1 |
|
这意味着,这些结构体和宏定义很可能是版本兼容的。那我们只需要到时候把数据揌到binder_write_read结构体里面,就可以进行ioctl系统调用了!
/dev/binder
再来看看mProcess->mDriverFD是什么东西。mProcess也就是 ProcessState.cpp
(源码目录:frameworks/native/libs/binder/ProcessState.cpp):
1 | ProcessState::ProcessState(const char *driver) |
从ProcessState的构造函数中得知,mDriverFD由open_driver方法初始化。
1 | static int open_driver(const char *driver) { |
ProcessState在哪里实例化呢?
1 | sp<ProcessState> ProcessState::self() { |
可以看到,ProcessState的gProcess是一个全局单例对象,这意味着,在当前进程中,open_driver只会执行一次,得到的 mDriverFD 会一直被使用。
1 | const char* kDefaultDriver = "/dev/binder"; |
而open函数操作的这个设备节点就是/dev/binder。
纳尼?在应用层直接操作设备节点?Gityuan大佬不会骗我吧?一般来说,Android系统在集成SELinux的安全机制之后,普通应用甚至是系统应用,都不能直接操作一些设备节点,除非有SELinux规则,给应用所属的域或者角色赋予了那样的权限。
看看文件权限:
1 | adb shell |
可以看到,/dev/binder设备对所有用户可读可写。
再看看,SELinux权限:
1 | ls -Z /dev/binder |
查看源码中对binder_device角色的SELinux规则描述:
1 | allow domain binder_device:chr_file rw_file_perms; |
也就是所有domain对binder的字符设备有读写权限,而普通应用属于domain。
既然这样,*肝它!*
写个Demo试一下
验证一下上面的想法,看看ioctl给binder driver发数据好不好使。
1、打开设备
1 | int fd = open("/dev/binder", O_RDWR | O_CLOEXEC); |
2、ioctl
1 | Parcel *parcel = new Parcel; |
3、查看日志
1 | D/KeepAlive: Opening '/dev/binder' success, fd is 35 |
打开设备节点成功了,耶✌️!但是ioctl失败了🤔,失败原因是Invalid argument,也就是说可以通信,但是Parcel数据有问题。来看看数据应该是什么样的。
binder_write_read结构体数据封装
IPCThreadState.talkWithDriver方法中,bwr.write_buffer指针指向了mOut.data(),显然mOut是一个Parcel对象。
1 | binder_write_read bwr; |
再来看看什么时候会向mOut中写数据:
1 | status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags, |
writeTransactionData方法中,会往mOut中写入一个binder_transaction_data结构体数据,binder_transaction_data结构体中又包含了作为参数传进来的data Parcel对象。
writeTransactionData方法会被transact方法调用:
1 | status_t IPCThreadState::transact(int32_t handle, uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags) { |
IPCThreadState是跟binder driver真正进行交互的类。每个线程都有一个IPCThreadState,每个IPCThreadState中都有一个mIn、一个mOut。
成员变量mProcess保存了ProcessState变量(每个进程只有一个)。
接着看一下一次Binder调用的时序图:

Binder介绍一节中说过,BpBinder是Binder Client,上层想进行进程间Binder通信时,会调用到BpBinder的transact方法,进而调用到IPCThreadState的transact方法。
来看看BpBinder的transact方法的定义:
1 | status_t BpBinder::transact(uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags) { |
BpBinder::transact方法的code/data/reply/flags这几个参数都是调用的地方传过来的,现在唯一不知道的就是mHandle是什么东西。
mHandle是BpBinder(也就是Binder Client)的一个int类型的局部变量(句柄),只要拿到了这个handle就相当于拿到了BpBinder。
ioctl启动Service分几步?
下面是在依赖libbinder.so时,启动Service的步骤:
1 | // 获取ServiceManager |
1、获取到IServiceManager Binder Client;
2、从ServiceManager中获取到ActivityManager Binder Client;
3、调用ActivityManager binder的transact方法传输Service的Parcel数据。
通过ioctl启动Service也应该是类似的步骤:
1、获取到ServiceManager的mHandle句柄;
2、进行binder调用获取到ActivityManager的mHandle句柄;
3、进行binder调用传输启动Service的指令数据。
这里有几个问题:
1、不依赖libbinder.so时,ndk中没有Parcel类的定义,parcel数据哪里来,怎么封装?
2、如何获取到BpBinder的mHandle句柄?
如何封装Parcel数据
Parcel类是Binder进程间通信的一个基础的、必不可少的数据结构,往Parcel中写入的数据实际上是写入到了一块内部分配的内存上,最后把这个内存地址封装到binder_write_read结构体中。Parcel作为一个基础的数据结构,和Binder相关类是可以解耦的,可以直接拿过来使用,我们可以根据需要对有耦合性的一些方法进行裁剪。
c++ Parcel类路径:
frameworks
/native
/libs
/binder
/Parcel.cpp
jni Parcel类路径:
frameworks
/base
/core
/jni
/android_os_Parcel.cpp
如何获取到BpBinder的mHandle句柄
具体流程参考Binder系列4—获取ServiceManager。
1、获取ServiceManager的mHandle句柄
defaultServiceManager()方法用来获取gDefaultServiceManager对象,gDefaultServiceManager是ServiceManager的单例。
1 | sp<IServiceManager> defaultServiceManager() { |
getContextObject方法用来获取BpServiceManager对象(BpBinder),查看其定义:
1 | sp<IBinder> ProcessState::getContextObject(const sp<IBinder>& /*caller*/) { |
可以发现,getStrongProxyForHandle是一个根据handle获取IBinder对象的方法,而这里handle的值为0,可以得知,ServiceManager的mHandle恒为0。
2、获取ActivityManager的mHandle句柄
获取ActivityManager的c++方法是:
1 | sp<IBinder> binder = serviceManager->getService(String16("activity")); |
BpServiceManager.getService:
1 | virtual sp<IBinder> getService(const String16& name) const { |
BpServiceManager.checkService:
1 | virtual sp<IBinder> checkService( const String16& name) const { |
可以看到,CHECK_SERVICE_TRANSACTION这个binder调用是有返回值的,返回值会写到reply中,通过reply.readStrongBinder()方法,即可从reply这个Parcel对象中读取到ActivityManager的IBinder。每个Binder对象必须要有它自己的mHandle句柄,不然,transact操作是没办法进行的。所以,很有可能,Binder的mHandle的值是写到reply这个Parcel里面的。
看看reply.readStrongBinder()方法搞了什么鬼:
1 | sp<IBinder> Parcel::readStrongBinder() const { |
调用到了Parcel::unflattenBinder方法,顾名思义,函数最终想要得到的是一个Binder对象,而Parcel中存放的是二进制的数据,unflattenBinder很可能是把Parcel中的一个结构体数据给转成Binder对象。
看看Parcel::unflattenBinder方法的定义:
1 | status_t Parcel::unflattenBinder(sp<IBinder>* out) const { |
果然如此,从Parcel中可以得到一个flat_binder_object结构体,这个结构体重有一个handle变量,这个变量就是BpBinder中的mHandle句柄。
因此,在不依赖libbinder.so的情况下,我们可以自己组装数据发送给ServiceManager,进而获取到ActivityManager的mHandle句柄。
IPCThreadState是一个被Binder依赖的类,它是可以从源码中抽离出来为我们所用的。上一节中说到,Parcel类也是可以从源码中抽离出来的。
通过如下的操作,我们就可以实现ioctl获取到ActivityManager对应的Parcel对象reply:
1 | Parcel data, reply; |
reply变量也就是我们想要的包含了flat_binder_object结构体的Parcel对象,再经过如下的操作就可以得到ActivityManager的mHandle句柄:
1 | const flat_binder_object* flat = reply->readObject(false); |
3、传输启动指定Service的Parcel数据
上一步已经拿到ActivityManger的mHandle句柄,比如值为1。这一步的过程和上一步类似,自己封装Parcel,然后调用IPCThreadState::transact方法传输数据,伪代码如下:
1 | Parcel data; |
4、writeService方法需要做什么事情?
下面这段代码是Java中封装Parcel对象的方法:
1 | Intent intent = new Intent(); |
可以看到,有Intent类转Parcel,ComponentName类转Parcel,这些类在c++中是没有对应的类的。所以需要我们参考intent.writeToParcel/ComponentName.writeToParcel等方法的源码的实现,自行封装数据。下面这段代码就是把启动Service的Intent写到Parcel中的方法:
1 | void writeIntent(Parcel &out, const char *mPackage, const char *mClass) { |
继续写Demo试一下
上面已经知道了怎么通过ioctl获取到ActivityManager,可以写demo试一下:
1 | // 打开binder设备 |
给IPCThreadState::transact加上一些日志,打印结果如下:
1 | D/KeepAlive: BR_DEAD_REPLY |
reply中始终读不到数据。这是为什么?现在已经不报Invalid argument的错误了,说明Parcel数据格式可能没问题了。但是不能成功把数据写给ServiceManager,或者ServiceManager返回的数据不能成功写回来。
想到Binder是基于内存的一种IPC机制,数据都是对的,那问题就出在内存上了。这就要说到Binder基本原理以及Binder内存转移关系。
Binder基本原理:
Binder的Client端和Server端位于不同的进程,它们的用户空间是相互隔离。而内核空间由Linux内核进程来维护,在安全性上是有保障的。所以,Binder的精髓就是在内核态开辟了一块共享内存。
数据发送方写数据时,内核态通过copy_from_user()方法把它的数据拷贝到数据接收方映射(mmap)到内核空间的地址上。这样,只需要一次数据拷贝过程,就可以完成进程间通信。
由此可知,没有这块内核空间是没办法完成IPC通信的。Demo失败的原因就是缺少了一个mmap过程,以映射一块内存到内核空间。修改如下:
1 |
|
日志:
1 | D/KeepAlive: BR_REPLY |
搞定!
最后
当然,这个保活的办法虽然很强,但现在也只能活在模拟器和部分机型中了。
尤其是MIUI12挂了,最新的EMUI挂了
说一下我的方法论。
1、确定问题和目标。
研究一个比较复杂的东西的时候,我们比较难有一个大局观。这个时候,就需要明确自己需要什么?有问题,才能推动自己学习,然后顺腾摸瓜,最后弄清自己的模块在系统中的位置。
确定了目标是直接通过ioctl进行Binder通信,进而确定Binder通信的关键是拿到mHandle句柄。同时也理清了Binder通信的一个基本流程。
2、时序图很重要。
大佬们画的时序图,可快帮助我们快速理清框架的思路。
3、实践出真知。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 nathanwriting@126.com

