问题集锦
1.ArrayList、LinkedList、HashMap线程安全和替代方案
ArryList 取值速度快(底层数据结构是数组)
LinkedList 插入和删除速度快(底层数据结构为链表)
ArrayList 线程替代方案Vector
线程安全:Collections.synchronizedList();
解决HashMap线程安全方法
1、继承HashMap,重写或者按要求编写自己的方法,这些方法要写成synchronized,在这些synchronized的方法中调用HashMap的方法
2、使用Collections.synchronizedMap()
3、使用ConcurrentHashMap替代,并不推荐新代码使用HashTable,HashTable继承于Dictionary,任意时间只有一个线程能写HashTable,并发性能不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。不需要线程安全的场景使用HashMap,需要线程安全的场合使用ConcurrentHashMap替换。(线程安全的ConcurrentHashMap、记录插入顺序的LinkHashMap、给key排序的TreeMap等)
1.1 数组动态扩容
1 | // 参考ArrayList源码实现 |
1.2动态扩容的集合
1 | package com.datastructure.array.sample; |
2.SharePreferences线程安全和替代方案MMKV及底层原理–MMKV使用Ashmem匿名内存
MMKV是基于mmap内存映射的移动端通用key-value组件,底层序列化/反序列化使用protobuf实现,性能高,稳定性强
但protobuf不支持增量更新,所以将key-value对象序列化之后直接append到结尾,此时的同一key对应的value非唯一,所以不断替换后取最后一个value为最新有效
在文件大小不到1K时采取append方式,并以pagesize大小申请空间,若超过阈值1K则对key进行排重后序列化保存结果,如果此时空间还是不够用则将文件扩大一倍直到空间足够
在空间增长时通过crc对文件进行校验甄别无效数据
可存储boolean、int、long、float、double、byte[],String、Set
代码实现:
1 | String rootDir = MMKV.initialize(this); |
3.OOM-JVM导致的内存泄露
内存泄漏场景
- 内存中数据量太大,比如一次性从数据库中取出来太多数据
- 静态集合类中对象的引用,在使用完后未清空(只把对象设为null,而不是从集合中移除),使JVM不能回收,即内存泄漏
- 静态方法中只能使用全局静态变量,而如果静态变量又持有静态方法传入的参数对象的引用,会引起内存泄漏
- 代码中存在死循环,或者循环过多,产生过多的重复的对象
- JVM启动参数内存值设置过小
a. 堆内存:JVM默认为64M,-Xms堆的最小值, -Xmx堆的最大值,OutOfMemoryError: java heap space
b. 栈内存:-Xss,StackOverflowError,栈太深
c. 永久代内存:-XX:PermSize,-XX:MaxPermSize,OutOfMemoryError: PermGen space,加载的类过多 - 监听器:addXXListener,没有remove
- 各种连接没有关闭:例如数据库连接、网络连接
- 单例模式:如果单例对象持有外部对象的引用,那么外部对象将不会被回收,引起内存泄漏
- 一个类含有静态变量,这个类的对象就无法被回收
- ThreadLocal
解决思路
- 修改JVM启动参数,直接增加内存
- 检查错误日志
- 检查代码中有没有一次性查出数据库所有数据
- 检查代码中是否有死循环
- 检查代码中循环和递归是否产生大量重复对象
- 检查List/Map等集合,是否未清除
- 使用内存查看工具
代码优化
- 主动释放无用的对象
- 尽量使用StringBuilder代替String
- 尽量少用静态变量,因为静态变量是类的,GC不会回收
- 避免创建大对象和同时创建多个对象,例如:数组,因为数组的长度是固定的
- 对象池技术
commons-pool提供了一套很好用的对象池组件,使用也很简单。
org.apache.commons.pool.ObjectPool定义了一个简单的池化接口,有三个对应实现,commons-pool提供了多样的集合,包括先进先出(FIFO),后进先出(LIFO)
StackObjectPool :实现了后进先出(LIFO)行为。
SoftReferenceObjectPool: 实现了后进先出(LIFO)行为。另外,对象池还在SoftReference 中保存了每个对象引用,允许垃圾收集器针对内存需要回收对象。
KeyedObjectPool定义了一个以任意的key访问对象的接口(可以池化对种对象),有两种对应实现。
GenericKeyedObjectPool :实现了先进先出(FIFO)行为。
StackKeyedObjectPool : 实现了后进先出(LIFO)行为。
PoolableObjectFactory 定义了池化对象的生命周期方法,我们可以使用它分离被池化的不同对象和管理对象的创建,持久,销毁。
BasePoolableObjectFactory这个实现PoolableObjectFactory接口的一个抽象类,我们可用扩展它实现自己的池化工厂。
JVM堆内存溢出后,其他线程可否继续工作?
- 当前线程OOM后,如果终止,会发生GC,其他线程可以继续工作
- 如果线程OOM后,没有终止,其他线程也会OOM
1 | public class PooledObject<T> { |
1 | public abstract class ObjectPool<T> { |
1 | public class DefaultObjectPool extends ObjectPool<String> { |
4.OkHttp及默认拦截器,与自定义拦截器的执行顺序
RetryAndFollowUpInterceptor:负责失败重试和重定向
BridgeInterceptor:负责把用户构造的Request转换为发送给服务器的Request和把服务器返回的Response转换为对用户友好的Response
CacheInterceptor:负责读取缓存以及更新缓存
ConnectInterceptor:负责与服务器建立连接并管理连接
CallServerInterceptor:负责向服务器发送请求和从服务器读取响应
RealCall.getResponseWithInterceptorChain() 方法中调用
网络请求前后:通过 OkHttpClient.addInterceptor 方法添加
读取响应前后:通过 OkHttpClient.addNetworkInterceptor 方法添加
发起请求:
自定义Intercepter->RetryAndFollowUpIntercepter->BridgeIntercepter->CacheIntercepter->ConnectIntercepter->自定义NetworkIntercepter->CallServerIntercepter
请求响应:
顺序与发起请求相反

5.线程池获取实例的方法和参数列表
Executors的静态方法
1 | public static ExecutorService newCachedThreadPool() |
内部调用
1 | public ThreadPoolExecutor(int corePoolSize, |
6.OKHttp和HtttpURLConnection的区别
是一个相对比较简单的网络库,最开始通过根据设置的URL信息,创建一个Socket连接,然后获得Socket连接后得到Socket的InputStream和OutputStream,然后通过其获取数据和写入数据,其内部提供的功能比较少,仅限于帮助我们做一些简单的http的包装,核心类是HttpConnection,HttpEngine两个类。
轻巧的api有助于简化管理并减少兼容性问题,可自动处理缓存机制HttpResponseCache,减少网络使用量,并减少电池消耗
Android4.4开始HttpURLConnection的底层实现采用的是基于OkHttp的fork,HttpURLConnection本身不与OkHttp绑定;HttpURLConnection存在于谷歌或Square之前。但是HttpURLConnection是一个abstract类,它本身是无用的。Java运行时库需要HttpURLConnection的具体实现,然后可以使用它来实现openConnection()上的URL等方法,这需要返回一些HttpURLConnection实现。
在android 4.3及更高版本中,afaik的具体实现基于apache harmony实现,android中的大多数类都是这样的。
okhttp是高性能的http库,支持同步、异步,而且实现了spdy、http2、websocket协议,api很简洁易用,和volley一样实现了http协议的缓存。picasso就是利用okhttp的缓存机制实现其文件缓存,实现的很优雅,很正确,反例就是UIL(universal image loader),自己做的文件缓存,而且不遵守http缓存机制,四大核心类:OkHttpClient、Request、Call 和 Response
HttpClient早就不推荐httpclient,5.0之后干脆废弃,后续会删除。6.0删除了HttpClient
7.Binder原理及为什么采用
Linux现有的IPC通信机制
- 管道:在创建时分配一个page大小的内存,缓存区大小比较有限;
- 消息队列:信息复制两次,额外的CPU消耗;不合适频繁或信息量大的通信;
- 共享内存:无须复制,共享缓冲区直接付附加到进程虚拟地址空间,速度快;但进程间的同步问题操作系统无法实现,必须各进程利用同步工具解决;
- 套接字:作为更通用的接口,传输效率低,主要用于不通机器或跨网络的通信;
- 信号量:常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 信号: 不适用于信息交换,更适用于进程中断控制,比如非法内存访问,杀死某个进程等;
(1)从性能的角度
数据拷贝次数:Binder数据拷贝只需要一次,而管道、消息队列、Socket都需要2次,但共享内存方式一次内存拷贝都不需要;从性能角度看,Binder性能仅次于共享内存。
(2)从稳定性的角度
Binder是基于C/S架构的,简单解释下C/S架构,是指客户端(Client)和服务端(Server)组成的架构,Client端有什么需求,直接发送给Server端去完成,架构清晰明朗,Server端与Client端相对独立,稳定性较好;而共享内存实现方式复杂,没有客户与服务端之别, 需要充分考虑到访问临界资源的并发同步问题,否则可能会出现死锁等问题;从这稳定性角度看,Binder架构优越于共享内存。仅仅从以上两点,各有优劣,还不足以支撑google去采用binder的IPC机制
(3)从安全的角度传统
Linux IPC的接收方无法获得对方进程可靠的UID/PID,从而无法鉴别对方身份;而Android作为一个开放的开源体系,拥有非常多的开发平台,App来源甚广,因此手机的安全显得额外重要;对于普通用户,绝不希望从App商店下载偷窥隐射数据、后台造成手机耗电等等问题,传统Linux IPC无任何保护措施,完全由上层协议来确保。 Android为每个安装好的应用程序分配了自己的UID,故进程的UID是鉴别进程身份的重要标志,前面提到C/S架构,Android系统中对外只暴露Client端,Client端将任务发送给Server端,Server端会根据权限控制策略,判断UID/PID是否满足访问权限,目前权限控制很多时候是通过弹出权限询问对话框,让用户选择是否运行。Android 6.0,也称为Android M,在6.0之前的系统是在App第一次安装时,会将整个App所涉及的所有权限一次询问,只要留意看会发现很多App根本用不上通信录和短信,但在这一次性权限权限时会包含进去,让用户拒绝不得,因为拒绝后App无法正常使用,而一旦授权后,应用便可以胡作非为。针对这个问题,google在Android M做了调整,不再是安装时一并询问所有权限,而是在App运行过程中,需要哪个权限再弹框询问用户是否给相应的权限,对权限做了更细地控制,让用户有了更多的可控性,但同时也带来了另一个用户诟病的地方,那也就是权限询问的弹框的次数大幅度增多。对于Android M平台上,有些App开发者可能会写出让手机异常频繁弹框的App,企图直到用户授权为止,这对用户来说是不能忍的,用户最后吐槽的可不光是App,还有Android系统以及手机厂商,有些用户可能就跳果粉了,这还需要广大Android开发者以及手机厂商共同努力,共同打造安全与体验俱佳的Android手机。Android中权限控制策略有SELinux等多方面手段,下面列举从Binder的一个角度的权限控制:Android源码的Binder权限是如何控制? -Gityuan的回答传统IPC只能由用户在数据包里填入UID/PID;另外,可靠的身份标记只有由IPC机制本身在内核中添加。其次传统IPC访问接入点是开放的,无法建立私有通道。从安全角度,Binder的安全性更高。说到这,可能有人要反驳,Android就算用了Binder架构,而现如今Android手机的各种流氓软件,不就是干着这种偷窥隐射,后台偷偷跑流量的事吗?没错,确实存在,但这不能说Binder的安全性不好,因为Android系统仍然是掌握主控权,可以控制这类App的流氓行为,只是对于该采用何种策略来控制,在这方面android的确存在很多有待进步的空间,这也是google以及各大手机厂商一直努力改善的地方之一。在Android 6.0,google对于app的权限问题作为较多的努力,大大收紧的应用权限;另外,在Google举办的Android Bootcamp 2016大会中,google也表示在Android 7.0 (也叫Android N)的权限隐私方面会进一步加强加固,比如SELinux,Memory safe language(还在research中)等等,在今年的5月18日至5月20日,google将推出Android N。 话题扯远了,继续说Binder。
(4)从语言层面的角度
Linux是基于C语言(面向过程的语言),而Android是基于Java语言(面向对象的语句),而对于Binder恰恰也符合面向对象的思想,将进程间通信转化为通过对某个Binder对象的引用调用该对象的方法,而其独特之处在于Binder对象是一个可以跨进程引用的对象,它的实体位于一个进程中,而它的引用却遍布于系统的各个进程之中。可以从一个进程传给其它进程,让大家都能访问同一Server,就像将一个对象或引用赋值给另一个引用一样。Binder模糊了进程边界,淡化了进程间通信过程,整个系统仿佛运行于同一个面向对象的程序之中。从语言层面,Binder更适合基于面向对象语言的Android系统,对于Linux系统可能会有点“水土不服”。另外,Binder是为Android这类系统而生,而并非Linux社区没有想到Binder IPC机制的存在,对于Linux社区的广大开发人员,我还是表示深深佩服,让世界有了如此精湛而美妙的开源系统。也并非Linux现有的IPC机制不够好,相反地,经过这么多优秀工程师的不断打磨,依然非常优秀,每种Linux的IPC机制都有存在的价值,同时在Android系统中也依然采用了大量Linux现有的IPC机制,根据每类IPC的原理特性,因时制宜,不同场景特性往往会采用其下最适宜的。比如在Android OS中的Zygote进程的IPC采用的是Socket(套接字)机制,Android中的Kill Process采用的signal(信号)机制等等。而Binder更多则用在system_server进程与上层App层的IPC交互。
(5) 从公司战略的角度
Linux内核是开源的系统,所开放源代码许可协议GPL保护,该协议具有“病毒式感染”的能力,怎么理解这句话呢?受GPL保护的Linux Kernel是运行在内核空间,对于上层的任何类库、服务、应用等运行在用户空间,一旦进行SysCall(系统调用),调用到底层Kernel,那么也必须遵循GPL协议。
8.TCP和UDP在报文上有什么区别
源端口(Source port)和目的端口(Destination port)
各16 bits。IP地址标识互联网中的不同终端,端口号标识终端中的不同应用进程,具有本地意义。32位IP + 16位端口号 = 48位插口。
端口由互联网数字分配机构(Internet Assigned Numbers Authority,IANA)分配,TCP和UDP端口号列表。

著名端口号(Well-known) 注册端口号(Registered) 动态端口号(Dynamic)
01023 102449151 49152~65535
IANA统一分配 向IANA申请注册 本地分配
- 序号(Sequence Number)和确认序号(Acknowledgment Number)
各32 bits。TCP连接传输的字节流中的每一个字节都有序号。SN指示本报文段所发送的数据第一个字节的序号。AN指示期望收到对方的下一个报文的第一个字节的序号,所有小于AN的报文都被正确接收。
首部长度(Data offset)
4 bits,以32-bit字为单位。TCP首部长短,也是TCP报文数据部分的偏移量。范围5~15,即20 bytes ~ 60 bytes。options部分最多允许40 bytes。
保留(Resevered)
3 bits,将来使用,目前应设为0。
标志位(Flags)
URG = 1,指示报文中有紧急数据,应尽快传送(相当于高优先级的数据)。
PSH = 1,接到后尽快交付给接收的应用进程。
RST = 1,TCP连接中出现严重差错(如主机崩溃),必须释放连接,在重新建立连接。
FIN = 1,发送端已完成数据传输,请求释放连接。
SYN = 1,处于TCP连接建立过程。
ACK = 1,确认序号(AN)有效。
窗口(Window size)
16 bits,接收窗口的大小。接收端希望接收的字节数。
校验和(Checksum)
16 bits,校验报文首部、数据。
紧急指针(Urgent pointer)
16 bits,如果URG = 1,该字段指示紧急数据的大小(相对于SN的偏移),紧急数据在数据部分的最前面。
可选项(Options)
TCP报文的字段实现了TCP的功能,标识进程、对字节流拆分组装、差错控制、流量控制、建立和释放连接等。

源端口(Source port)和目的端口(Destination port)
报文长度(Length)
16 bits,指示UDP报文(首部和数据)的总长度。最小8 bytes,只有首部,没有数据。最大值为65535 bytes。实际上,由于IPv4分组的最大数据长度为(65535 - 20 = 65515) bytes,UDP的报文长度不超过65515 bytes。IPv6允许UDP的长度超过65535,此时length字段设为0。
校验和(Checksum)
9.屏幕适配方案ScreenMatch(SmallWidth)
如果项目中使用SmallWidth适配,而设计师给的标注又是px的,我们只要调整base_dp的值,再使用ScreenMatch生成该base_dp对应的一系列values-swXX,就可以在布局中直接写像素对应的dp_xx
优点
使用成本特别低,操作相当简单,使用该方案后在页面布局时不需要额外的代码和操作。
侵入性非常低,该方案和项目完全解耦,在项目布局时不会依赖哪怕一行该方案的代码,而且还是 Android 官方的 API,意味着当你遇到什么问题无法解决,想切换为其他屏幕适配方案时,基本不需要更改之前的代码,整个切换过程几乎在瞬间完成,会少很多麻烦,节约很多时间,试错成本接近于 0,不会有任何性能的损耗。
可适配三方库的控件和系统的控件(不止是 Activity 和 Fragment,Dialog、Toast 等所有系统控件都可以适配),由于修改的 density 在整个项目中是全局的,所以只要一次修改,项目中的所有地方都会受益。
缺点
只需要修改一次 density,项目中的所有地方都会自动适配,这个看似解放了双手,减少了很多操作,但是实际上反应了一个缺点,那就是只能一刀切的将整个项目进行适配,但适配范围是不可控的。
这样不是很好吗?这样本来是很好的,但是应用到这个方案是就不好了,因为我上面的原理也分析了,这个方案依赖于设计图尺寸,但是项目中的系统控件、三方库控件、等非我们项目自身设计的控件,它们的设计图尺寸并不会和我们项目自身的设计图尺寸一样。
当这个适配方案不分类型,将所有控件都强行使用我们项目自身的设计图尺寸进行适配时,这时就会出现问题,当某个系统控件或三方库控件的设计图尺寸和和我们项目自身的设计图尺寸差距非常大时,这个问题就越严重。
其他适配方式
百分比
AutoLayout
自定义View
10.Kotlin协程实现
异步编程中最为常见的场景是:在后台线程执行一个复杂任务,下一个任务依赖于上一个任务的执行结果,所以必须等待上一个任务执行完成后才能开始执行。看下面代码中的三个函数,后两个函数都依赖于前一个函数的执行结果
协程通过将复杂性放入库来简化异步编程。程序的逻辑可以在协程中顺序地表达,而底层库会为我们解决其异步性。该库可以将用户代码的相关部分包装为回调、订阅相关事件、在不同线程(甚至不同机器)上调度执行,而代码则保持如同顺序执行一样简单
Future
CompletableFuture-JDK8
RxJava
CoroutineContext、CoroutineDispatcher、Job
1 CoroutineScope 和 CoroutineContext
CoroutineScope,可以理解为协程本身,包含了 CoroutineContext。
CoroutineContext,协程上下文,是一些元素的集合,主要包括 Job 和 CoroutineDispatcher 元素,可以代表一个协程的场景。
EmptyCoroutineContext 表示一个空的协程上下文。
2 CoroutineDispatcher
CoroutineDispatcher,协程调度器,决定协程所在的线程或线程池。它可以指定协程运行于特定的一个线程、一个线程池或者不指定任何线程(这样协程就会运行于当前线程)。coroutines-core中 CoroutineDispatcher 有三种标准实现Dispatchers.Default、Dispatchers.IO,Dispatchers.Main和Dispatchers.Unconfined,Unconfined 就是不指定线程。
launch函数定义如果不指定CoroutineDispatcher或者没有其他的ContinuationInterceptor,默认的协程调度器就是Dispatchers.Default,Default是一个协程调度器,其指定的线程为共有的线程池,线程数量至少为 2 最大与 CPU 数相同。
3 Job & Deferred
Job,任务,封装了协程中需要执行的代码逻辑。Job 可以取消并且有简单生命周期,它有三种状态:
State [isActive] [isCompleted] [isCancelled]
New (optional initial state) false false false
Active (default initial state) true false false
Completing (optional transient state) true false false
Cancelling (optional transient state) false false true
Cancelled (final state) false true true
Completed (final state) false true false
Job 完成时是没有返回值的,如果需要返回值的话,应该使用 Deferred,它是 Job 的子类public interface Deferred
4 Coroutine builders
CoroutineScope.launch函数属于协程构建器 Coroutine builders,Kotlin 中还有其他几种 Builders,负责创建协程。
4.1 CoroutineScope.launch {}
CoroutineScope.launch {} 是最常用的 Coroutine builders,不阻塞当前线程,在后台创建一个新协程,也可以指定协程调度器,例如在 Android 中常用的GlobalScope.launch(Dispatchers.Main) {}。
1 | fun postItem(item: Item) { |
4.2 runBlocking {}
runBlocking {}是创建一个新的协程同时阻塞当前线程,直到协程结束。这个不应该在协程中使用,主要是为main函数和测试设计的。
1 | fun main(args: Array<String>) = runBlocking { // start main coroutine |
4.3 withContext {}
withContext {}不会创建新的协程,在指定协程上运行挂起代码块,并挂起该协程直至代码块运行完成。
4.4 async {}
CoroutineScope.async {}可以实现与 launch builder 一样的效果,在后台创建一个新协程,唯一的区别是它有返回值,因为CoroutineScope.async {}返回的是 Deferred 类型。
1 | fun main(args: Array<String>) = runBlocking { // start main coroutine |
获取CoroutineScope.async {}的返回值需要通过await()函数,它也是是个挂起函数,调用时会挂起当前协程直到 async 中代码执行完并返回某个值
11.synchronized和volatile的区别
synchronized的两条规定:
线程解锁前,必须把共享变量的最新值刷新到主内存中
线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时,需要从主内存中重新读取最新的值(注意:加锁与解锁需要是同一把锁)
volatile关键字
能够保证volatile变量的可见性
不能保证volatile变量复合操作的原子性
synchronized和volatile的区别
volatile不需要加锁,比synchronized更轻量级,不会阻塞线程;
从内存可见性角度,volatile读相当于加锁,volatile写相当于解锁;
synchronized既能够保证可见性,又能保证原子性,而volatile只能保证可见性,无法保证原子性。
volatile本质是在告诉 jvm 当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住
volatile修饰变量;synchronized修饰方法
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞
volatile仅能实现变量的修改可见性,不能保证原子性,因为一个线程 A 修改了变量还没结束时,另外的线程 B 可以看到已修改的值,而且可以修改这个变量,而不用等待 A 释放锁,因为volatile变量没上锁。而synchronized则可以保证变量的修改可见性和原子性
12.HashMap的实现和哈希碰撞及扩容方案
HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。当程序执行put(String,Obect)方法 时,系统将调用String的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置
HashMap里面的bucket出现了单链表的形式,散列表要解决的一个问题就是散列值的冲突问题,通常是两种方法:链表法和开放地址法。链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。java.util.HashMap采用的链表法的方式,链表是单向链表
系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。 HashMap里面没有出现hash冲突时,没有形成单链表时,hashmap查找元素很快,get()方法能够直接定位到元素,但是出现单链表后,单个bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
通过上面可知如果多个hashCode()的值落到同一个桶内的时候,这些值是存储到一个链表中的。最坏的情况下,所有的key都映射到同一个桶中,这样HashMap就退化成了一个链表——查找时间从O(1)到O(n)。也就是说我们是通过链表的方式来解决这个Hash碰撞问题的。
如果某个桶中的记录过大的话(当前是TREEIFY_THRESHOLD = 8),HashMap会动态的使用一个专门的TreeMap实现来替换掉它。这样做的结果会更好,是O(logn),而不是糟糕的O(n)。它是如何工作的?前面产生冲突的那些KEY对应的记录只是简单的追加到一个链表后面,这些记录只能通过遍历来进行查找。但是超过这个阈值后HashMap开始将列表升级成一个二叉树,使用哈希值作为树的分支变量,如果两个哈希值不等,但指向同一个桶的话,较大的那个会插入到右子树里。如果哈希值相等,HashMap希望key值最好是实现了Comparable接口的,这样它可以按照顺序来进行插入。这对HashMap的key来说并不是必须的,不过如果实现了当然最好。如果没有实现这个接口,在出现严重的哈希碰撞的时候,你就并别指望能获得性能提升了。这个性能提升有什么用处?比方说恶意的程序,如果它知道我们用的是哈希算法,它可能会发送大量的请求,导致产生严重的哈希碰撞。然后不停的访问这些key就能显著的影响服务器的性能,这样就形成了一次拒绝服务攻击(DoS)。JDK 8中从O(n)到O(logn)的飞跃,可以有效地防止类似的攻击,同时也让HashMap性能的可预测性稍微增强了一些。
HashMap通过高16位与低16位进行异或运算来让高位参与散列,提高散列效果;
HashMap控制数组的长度为2的整数次幂来简化取模运算,提高性能;
HashMap通过控制初始化的数组长度为2的整数次幂、扩容为原来的2倍来控制数组长度一定为2的整数次幂。
哈希冲突解决方案
再优秀的hash算法永远无法避免出现hash冲突。hash冲突指的是两个不同的key经过hash计算之后得到的数组下标是相同的。解决hash冲突的方式很多,如开放定址法、再哈希法、公共溢出表法、链地址法。HashMap采用的是链地址法,jdk1.8之后还增加了红黑树的优化
BroadcastReceiver与LocalBroadcastManager应用及区别
应用场景
- BroadcastReceiver用于应用之间的传递消息;
- 而LocalBroadcastManager用于应用内部传递消息,比BroadcastReceiver更加高效。
安全
- BroadcastReceiver使用的Content API,所以本质上它是跨应用的,所以在使用它时必须要考虑到不要被别的应用滥用;
- LocalBroadcastManager不需要考虑安全问题,因为它只在应用内部有效。
相同点
- LocalBroadcastManager和传统广播(Context注册注销)都能通过BroadcastReceiver介绍信息。
不同点
- 通过LocalBroadcastManager注册的广播只能通过代码的方式注册即LocalBroadcastManager.getInstance(this).registerReceiver()注册。传统广播能在代码动态注册和XML永久注册。
- LocalBroadcastManager注册的广播,您在发送广播的时候务必使用LocalBroadcastManager.sendBroadcast(intent);否则接收不到广播。传统的发送广播的方法:context.sendBroadcast( intent );
- LocalBroadcastManager注册广播后,一定要记得取消监听。这一步可以有效的解决内存泄漏的问题。
应用场景
某些系统广播只能用getApplication().registerReceiver注册 不能使用LocalBroadcastManager注册,否则接受不到信息。比如: 蓝牙接收数据广播和蓝牙状态监听广播。
13.缓存实现 DiskLRUCache实现 LRU数据结构(双向链表)
AOP编程思想
AOP应用场景
场景一: 记录日志(审计日志,异常处理)
场景二: 监控方法运行时间(性能监控)(例如:网络状态,APM埋点)
场景三: 权限控制
场景四: 缓存优化 (第一次调用查询数据库,将查询结果放入内存对象, 第二次调用, 直接从内存对象返回,不需要查询数据库 )
场景五: 事务管理(事务控制) (调用方法前开启事务, 调用方法后提交关闭事务 ,如声明式事务)
场景六: 分布式追踪
AOP相关概念
Aspect 切面 通常指@Aspect标识的类
Join point 连接点 In Spring AOP, a join point always represents a method execution. 目标对象中的方法就是一个连接点
Advice 通知 @Before、@AfterReturning、@AfterThrowing、@After、@Around
Pointcut 切点 连接点的集合
Introduction:引入,Declaring additional methods or fields on behalf of a type
Target object:目标对象,原始对象
AOP proxy:代理对象, 包含了原始对象的代码和增强后的代码的那个对象
Weaving: 织入
AOP的初衷
减少重复代码
关注点分离:功能性需求、非功能性需求
14.悲观锁、乐观锁、可重入锁、自旋锁、偏向锁、轻量/重量级锁、读写锁、各种锁及其Java实现
ARouter源码分析
注解
1 | public enum ElementType { |
@Retention用来约束注解的生命周期,分别有三个值,源码级别(source),类文件级别(class)或者运行时级别(runtime),其含有如下:
SOURCE:注解将被编译器丢弃(该类型的注解信息只会保留在源码里,源码经过编译后,注解信息会被丢弃,不会保留在编译好的class文件里)
CLASS:注解在class文件中可用,但会被VM丢弃(该类型的注解信息会保留在源码里和class文件里,在执行的时候,不会加载到虚拟机中),请注意,当注解未定义Retention值时,默认值是CLASS,如Java内置注解,@Override、@Deprecated、@SuppressWarnning等
RUNTIME:注解信息将在运行期(JVM)也保留,因此可以通过反射机制读取注解的信息(源码、class文件和执行的时候都有注解的信息),如SpringMvc中的@Controller、@Autowired、@RequestMapping等。
Launcher被杀死
AMS.killBackgroundProcesses发出时Launcher会被杀死
ActivityManager.killBackgroundProcesses
1 | /** |
Camera1 Camera2 CameraX的演进
Camera1
- Camera1 的开发中,打开相机,设置参数的过程是同步的,就跟用户实际使用camera的操作步骤一样。但是如果有耗时情况发生时,会导致整个调用线程等待;
- 开发者如果想要个性化设置camera效果,无法手动设置调整参数,需要依靠第三方算法对于回调的数据进行处理(NV21)。而且不同手机的回调数据效果都是不一样的,采用第三方算法调整,通常效果不好;
- 开发者所能获取的Camera状态信息有限;
camera1 的开发过程比较简单,对于常规视频采集,如果只要一般的预览功能,是没问题的,然而如果想要挖掘Camera更多的功能,camera1无法满足,于是有了camera2.
Camera2
- Camera2 的开发中,camera的生命周期都是异步的,即发送请求,等待回调的client-service模式;
- 系统: Android L+;
- 这里的关键回调主要是三个:
(1)CameraDevice.StateCallback ///比如线程A发送打开相机请求, 线程B中收到相机状态回调,线程B中与cameraDevice建立会话,设置参数,数据回调处理;
(2)CameraCaptureSession.StateCallback ///与CameraDevice建立会话后,收到的会话状态回调;
(3)ImageReader.OnImageAvailableListener // 开发者可以直接获取并且操作的数据回调;
- 通过跟相机建立的会话,可以更加精细的调整Camera参数:比如ISO感光度,曝光时间,曝光补偿……;
- 如果开发者想要更多自己的定制,也可以直接使用回调数据(YUV488);
- MultiCamera的支持;
Multi-Camera
- 系统:Android P+;
- 目前支持的multi-camera的设备: Pixel 3, mate20 系列;
- Multi-Camera 新功能:
(1)更好的光学变焦:之前的方式通常使用数码变焦或者是单个摄像头的光学变焦来达到变焦的效果, 通过多摄像头的变焦方式,无论远景还是近景,都可以采到更好质量的数据。
(2)景深计算:通过多摄像头的景深不同,可以得到每一帧图片中不同物体的景深,从而更好的区分前景或者后景。应用范围:背景虚化,背景替换,现实增强。
(3)更广的视角:更广的视角带来鱼眼镜头的畸变效果,畸变矫正功能。
CaptureRequest.DISTORTION_CORRECTION_MODE(4)人脸识别功能:跟畸变效果一样,自带人脸识别功能。应用范围:人脸裁剪,人脸特效。
CaptureResult.STATISTICS_FACE_DETECT_MODE(5)多路流同时采集:场景包括(单摄像头输出多流,多摄像头输出多流)
2
3
4
wideOutputConfigImageReader.setPhysicalCameraId(wideAngleId)
params.previewBuilder?.addTarget(normalSurface)
params.previewBuilder?.addTarget(wideSurface)
- 带来的问题:更耗内存,更耗电
- 趋势:单个手机中,支持更多的摄像头
Camera2 虽然给开发者带来了相机的更多可玩性,然而android的碎片化,导致很多设备的兼容性问题频繁发生。尤其国内的手机厂商,对camera2 的支持程度各不相同,
所以Camera2的开发难度更多的是在兼容性,于是有了CameraX。
CameraX
- 系统:Android L+
- Jetpack 内的一套Camera开发支持库。
- 特点:
- 更简单易用的API,更少的代码量,使开发者更专注业务的个性化实现。比如:对采集到图片做分析处理。
- 更好的兼容性,减少不同设备适配烦恼:包括宽高比、屏幕方向、旋转、预览大小和高分辨率图片大小。
- 数据分析: 开发者依然可以对数据进行个性化处理。
- 第三方Camera特效拓展:对于一些手机厂商特定实现的camera特效,开发者也可以使用。
- Code Sample 1(CameraX的常规使用)
(1)CameraX 创建UseCaseConfig; //已经提前实现好各种UseCase(preview,ImageCapture,ImageAnalysis…)对应不同的UseCaseConfig, 开发者重要专注自己的业务。
(2)创建对应UseCase
(3)CameraX bindToLifecycle(LifeCycleOwner, UseCases) //CameraX 会观察生命周期以确定何时打开相机、何时创建拍摄会话以及何时停止和关闭。
(4)CameraX unbind(UseCase)
| Camera1.0 | Camera2.0 | |
|---|---|---|
| 引入时间 | 5.0 | |
| 权限 | android.permission.CAMERA | android.permission.CAMERA |
| 布局 | SurfaceView | TextureView |
| 实现接口 | SurfaceHolder.Callback 1.surfaceCreated 2.surfaceChanged 3.surfaceDestroyed | SurfaceTextureListener 1.onSurfaceTextureAvailable 2.onSurfaceTextureSizeChanged 3.onSurfaceTextureDestroyed 4.onSurfaceTextureUpdated |
| Camera参数(设置,查看) | Camera.Parameters Camera.Size | 查看:CameraCharacteristics中getCameraCharacteristics(CameraID)设置:CaptureRequest.Builder中void set(Key key, T value)举例:曝光:CaptureReqBuilder.set(CaptureRequest.CONTROL_AE_EXPOSURE_COMPENSATION, 2); |
| 打开摄像头 | surfaceCreated中Camera.open(CameraID) | onSurfaceTextureAvailable中CameraManager.openCamera(CameraId,CameraDevice.StateCallback,Handler) |
| 开始预览 | Camera.startPreview() | CaptureReqBuilder = camera.createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW);CaptureReqBuilder.addTarget(Surface);Camera.createCaptureSession(Arrays.asList(surface),CaptureSessionStateCallback, Handler); |
| 设置预览方向 | Camera.setDisplayOrientation(degrees) | 并没有直接设置预览方向的方法,但是TextureView本身是一个View,支持旋转、平移、缩放,再重写onMeasure方法 |
| 图像原始数据byte[]实时获取 | Camera.PreviewCallback中onPreviewFrame(byte[],Camera) | 1.onSurfaceTextureUpdated中使用TextureView的getBitmap()方法,但是这里获取到的是Bitmap对象,而我需要的是原始byte[],所以这个方法不适用。2.设置ImageReader.setOnImageAvailableListener监听,在onImageAvailable(ImageReader)通过回调传递的ImageReader.acquireLatestImage()方法获取到一个Image对象(别忘了close(),否则画面会卡住,停止刷新),然后Image.getPlanes()[0].getBuffer()返回了一个ByteBuffer对象,最后new byte[buffer.remaining()]即可得到原始图像的byte[]。别忘了CaptureReqBuilder.addTarget(ImageReader.getSurface()); 否则看不到效果 |
| Camera图像预览尺寸大小设置 | Camera.Parameters.setPreviewSize(width, height) | TextureView. getSurfaceTexture()拿到SurfaceTexture()对象,再通过setDefaultBufferSize(width, height)进行设置。 |
| 将来获取到的图片的大小设置 | Camera.Parameters.setPictureSize(width, height); | ImageReader.newInstance(width, height,ImageFormat.YUV_420_888, MAX_IMAGES); |
| 将来获取到的图片的格式设置 | Camera.Parameters..setPictureFormat(ImageFormat.JPEG); | ImageReader.newInstance(width, height,ImageFormat.YUV_420_888, MAX_IMAGE |
| Camera2是通过系统服务拿到CameraManager来管理camera设备对象,camera的一次预览、拍照都是向请求会话(CaptureSession.StateCallback,摄像头打开时由相机设备的输出surface组成)发送一次请求(CaptureRequest.Builder)。需要在它的回调onConfigured中进行处理,例如预览,如果不在此方法中写上CameraCaptureSession.setRepeatingRequest(mCaptureReqBuilder.build(), null, mHandler);那么预览就不会成功。 |
此外,在创建会话,设置ImageReader监听,都需要传递一个Handler对象,这个Handler对象决定着这些会话、监听的回调方法会被在哪个线程中调用,如果传递的是NULL,那么回调会调用在当前线程。
闪关灯的控制方式
Camera1:
这行代码可以得到摄像头支持的闪光灯模式
List supportedFlashModes = params.getSupportedFlashModes();
控制闪光灯的方法:
params.setFlashMode(Parameters.FLASH_MODE_TORCH );//开启闪光灯
Parameters.FLASH_MODE_TORCH : 闪光灯常开
Parameters.FLASH_MODE_ON :拍照时闪光灯才打开
Camera2:
这句代码可以用来检测当前打开的摄像头是否支持闪光灯
boolean flashAvailable = cameraCharacteristics.get(CameraCharacteristics.FLASH_INFO_AVAILABLE);
控制闪光灯的方法:
1 | case 0: |
核心类
CameraManager
相机系统服务,用于管理和连接相机设备
CameraDevice
相机设备类,和Camera1中的Camera同级
CameraCharacteristics
主要用于获取相机信息,内部携带大量的相机信息,包含摄像头的正反(LENS_FACING)、AE模式、AF模式等,和Camera1中的Camera.Parameters类似
CaptureRequest
相机捕获图像的设置请求,包含传感器,镜头,闪光灯等
CaptureRequest.Builder
CaptureRequest的构造器,使用Builder模式,设置更加方便
CameraCaptureSession
请求抓取相机图像帧的会话,会话的建立主要会建立起一个通道。一个CameraDevice一次只能开启一个CameraCaptureSession。 源端是相机,另一端是 Target,Target可以是Preview,也可以是ImageReader。
ImageReader
用于从相机打开的通道中读取需要的格式的原始图像数据,可以设置多个ImageReader。
MediaCodec MediaMuxer
在Android4.1和Android4.3才引入,只能支持一个audio track和一个video track,而且仅支持mp4输出
MediaExtractor用于音视频分路,和MediaMuxer正好是反过程。MediaFormat用于描述多媒体数据的格式。MediaRecorder用于录像+压缩编码,生成编码好的文件如mp4, 3gpp,视频主要是用于录制Camera preview。MediaPlayer用于播放压缩编码后的音视频文件。AudioRecord用于录制PCM数据。AudioTrack用于播放PCM数据。PCM即原始音频采样数据,可以用如vlc播放器播放。
从Camera获取YUV实现硬解,从麦克风采集PCM实现音频播放
1 | //TODO 录制常量 |
SurfaceView TextureView SurfaceTexture等的区别
SurfaceView
1.1 概述
SurfaceView继承自类View,因此它本质上是一个View。但与普通View不同的是,它有自己的Surface,在WMS中有对应的WindowState,在SurfaceFlinger中有Layer。
调用者可以通过lockCanvas获得了一块类型为Canvas的画布之后,就可以调用Canvas类所提供的绘图函数来绘制任意的UI了,例如,调用Canvas类的成员函数drawLine、drawRect和drawCircle可以分别用来画直线、矩形和圆。
调用者在画布上绘制完成所需要的UI之后,通过调用SurfaceHolder类的成员函数unlockCanvasAndPost就可以将这块画布的图形绘冲区的UI数据提交给SurfaceFlinger服务来处理了,以便SurfaceFlinger服务可以在合适的时候将该图形缓冲区合成到屏幕上去显示,这样就可以将对应的SurfaceView的UI展现出来了。
1.2 双缓冲机制
SurfaceView在更新视图时用到了两张Canvas,一张frontCanvas和一张backCanvas,每次实际显示的是frontCanvas,backCanvas存储的是上一次更改前的视图,当使用lockCanvas()获取画布时,得到的实际上是backCanvas而不是正在显示的frontCanvas,之后你在获取到的backCanvas上绘制新视图,再unlockCanvasAndPost(canvas)此视图,那么上传的这张canvas将替换原来的frontCanvas作为新的frontCanvas,原来的frontCanvas将切换到后台作为backCanvas。例如,如果你已经先后两次绘制了视图A和B,那么你再调用lockCanvas()获取视图,获得的将是A而不是正在显示的B,之后你将重绘的C视图上传,那么C将取代B作为新的frontCanvas显示在SurfaceView上,原来的B则转换为backCanvas。
1.3 SurfaceView优点与缺点
优点: 使用双缓冲机制,可以在一个独立的线程中进行绘制,不会影响主线程,播放视频时画面更流畅
缺点:Surface不在View hierachy中,它的显示也不受View的属性控制,SurfaceView 不能嵌套使用。在7.0版本之前不能进行平移,缩放等变换,也不能放在其它ViewGroup中,在7.0版本之后可以进行平移,缩放等变换。
TextureView
2.1 概述
在4.0(API level 14)中引入,与SurfaceView一样继承View,它可以将内容流直接投影到View中,TextureView重载了draw()方法,其中主要SurfaceTexture中收到的图像数据作为纹理更新到对应的HardwareLayer中。
和SurfaceView不同,它不会在WMS中单独创建窗口,而是作为View hierachy中的一个普通View,因此可以和其它普通View一样进行移动,旋转,缩放,动画等变化。值得注意的是TextureView必须在硬件加速的窗口中。它显示的内容流数据可以来自App进程或是远端进程。
2.2 TextureView优点与缺点
优点:支持移动、旋转、缩放等动画,支持截图
缺点:必须在硬件加速的窗口中使用,占用内存比SurfaceView高,在5.0以前在主线程渲染,5.0以后有单独的渲染线程。
2.3 TextureView与SurfaceView对比
| SurfaceView | TextureView | |
|---|---|---|
| 内存 | 低 | 高 |
| 绘制 | 及时 | 1~3帧的延迟 |
| 耗电 | 低 | 高 |
| 动画与截图 | 不支持 | 支持 |
TextureView总是使用GL合成,而SurfaceView可以使用硬件overlay后端,可以占用更少的内存带宽,消耗更少的CPU(耗电);
TextureView的内部缓冲队列导致比SurfaceView使用更多的内存;
SurfaceTexture
3.1 概述
SurfaceTexture 类是在 Android 3.0 中引入的。当你创建了一个 SurfaceTexture,你就创建了你的应用作为消费者的 BufferQueue。当一个新的缓冲区由生产者入队列时,你的应用将通过回调 (onFrameAvailable()) 被通知。你的应用调用 updateTexImage(),这将释放之前持有的缓冲区,并从队列中获取新的缓冲区,执行一些 EGL 调用以使缓冲区可作为一个外部 texture 由 GLES 使用。
3.2 SurfaceTexture与SurfaceView对比
SurfaceTexture和SurfaceView不同的是,它对图像流的处理并不直接显示,而是转为OpenGL外部纹理,因此可用于图像流数据的二次处理(如Camera滤镜,桌面特效等)。比如Camera的预览数据,变成纹理后可以交给GLSurfaceView直接显示,也可以通过SurfaceTexture交给TextureView作为View heirachy中的一个硬件加速层来显示。
GLSurfaceView
GLSurfaceView从Android 1.5(API level 3)开始加入。在SurfaceView的基础上,和SurfaceView不同的是,它加入了EGL的管理,并自带了渲染线程。另外它定义了用户需要实现的Render接口,只需要将实现了渲染函数的Renderer的实现类设置给GLSurfaceView即可。
GLSurfaceView也可以作为相机的预览,但是需要创建自己的SurfaceTexture并调用OpenGl API绘制出来。GLSurfaceView 本身自带EGL的管理,并有渲染线程,这对于一些需要多个EGLSurface的场景将不适用。
自定义相机实现
1 | /** |
SurfaceView生命周期
SurfaceHolder.Callback的回调
surfaceCreated()
surfaceChanged()
自定义View需要重写的方法
- 构造器:重写构造器是定制View的最基本方式,当Java代码创建一个View实例,或根据XML布局文件加载并构建界面时将需要调用该构造器。
- onFinishinflate():这是一个回调方法,当应用从XML布局文件加载该组件并利用它来构建界面之后,该方法就会被回调。
- onMeasure(int,int):调用该方法来检测View组件及它所包含的所有子组件的大小。
- onLayout(boolean,int,int,int,int):当该组件需要分配其子控件的位置、大小时该方法就会被调用。
- onSizeChanged(int, int, int, int):当该组件的大小被改变时回调该方法。
- onDraw(Canvas):当该组件将要绘制它的内容时回调该方法进行绘制。
- onKeyDown(int, KeyEvent):当某个键被按下时触发该方法。
- onKeyUp(int, KeyEvent):当松开某个键时触发该方法。
- onTrackballEvent(MotionEvent):当发生轨迹球事件时触发该方法。
- onTouchEvent(MotionEvent):当发生触摸屏事件时触发该方法。
- onWindowFocusChanged(boolean):当该组件得到、失去焦点时触发该方法。
- onAttachedToWindow():当把该组件放入某个窗口时触发该方法。
- onDetachedFromWindow():当把该组件从某个窗口上分离时触发该方法。
- onWindowVisibilityChanged(int):当包含该组件的窗口的可见性发生改变时触发该方法。
自定义View什么时候可以获取到view的宽高
Constructor->onFinishInflate->onMeasure->onSizeChanged->onLayout->addOnGlobalLayoutListener->onWindowFocusChanged->onMeasure->onLayout
- Constructor:构造方法,View初始化的时候调用,在这里是无法获取其子控件的引用的.更加无法获取宽高了.
- onFinishInflate:当布局初始化完毕后回调,在这里可以获取所有直接子View的引用,但是无法获取宽高.
- onMeasure:当测量控件宽高时回调,当调用了requestLayout()也会回调onMeasure.在这里一定可以通过getMeasuredHeight()和getMeasuredWidth()来获取控件的高和宽,但不一定可以通过getHeight()和getWidth()来获取控件宽高,因为getHeight()和getWidth()必须要等onLayout方法回调之后才能确定.
- onSizeChanged:当控件的宽高发生变化时回调,和onMeasure一样,一定可以通过getMeasuredHeight()和getMeasuredWidth()来获取控件的高和宽,因为它是在onMeasure方法执行之后和onLayout方法之前回调的.
- onLayout:当确定控件的位置时回调,当调用了requestLayout()也会回调onLayout.在这里一定可以通过getHeight()和getWidth()获取控件的宽高,同时由于onMeasure方法比onLayout方法先执行,所以在这里也可以通过getMeasuredHeight()和getMeasuredWidth()来获取控件的高和宽.
- addOnGlobalLayoutListener:当View的位置确定完后会回调改监听方法,它是紧接着onLayout方法执行而执行的,只要onLayout方法调用了,那么addOnGlobalLayoutListener的监听器就会监听到.在这里getMeasuredHeight()和getMeasuredWidth()和getHeight()和getWidth()都可以获取到宽高.
- onWindowFocusChanged:当View的焦点发送改变时回调,在这里getMeasuredHeight()和getMeasuredWidth()和getHeight()和getWidth()都可以获取到宽高.Activity也可以通过重写该方法来判断当前的焦点是否发送改变了;需要注意的是这里View获取焦点和失去焦点都会回调.
那么,上面分析了那么多方法来获取控件的宽高,那到底用哪一种呢?
具体要用哪一种,是需要根据View的宽高是否会发生变化来决定:
- 如果自定义的View在使用的过程中宽高信息是不会改变的,那么上面方式3~方式7都可以使用.
- 如果自定义的View在使用过程中宽高信息都会发生改变的,而且又需要获取一开始时的宽高信息,那么建议使用View.getViewTreeObserver().addOnGlobalLayoutListener(OnGlobalLayoutListener listener)的方式,因为这种方式有getViewTreeObserver().removeOnGlobalLayoutListener(this);来避免回调函数因宽高信息的变化而多次调用,如果使用其他方式的话,就要借助额外的变量来保证获取到的宽高是View的初始高度.
onTouchEvent()返回值作用
true表示已经消耗了
false表示没有操作完,继续分发
一次完整的Http/Https请求
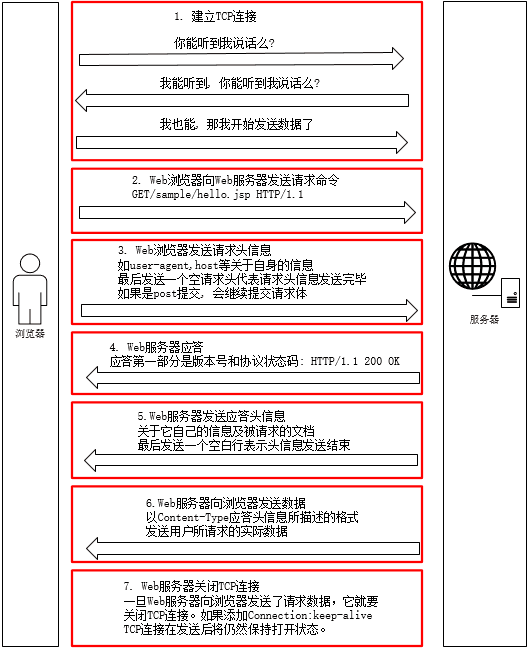
HTTP与HTTPS的不同点
- 1、HTTPS需要用到CA申请证书。
- 2、HTTP是超文本传输协议,信息是明文的;HTTPS则是具有安全性的SSL加密传输协议。
- 3、HTTPS和HTTP使用的是完全不同的连接方式,用的端口也不一样,HTTP是80,HTTPS是443。
- 4、HTTP的连接很简单,是无状态的,HTTPS是HTTP+SSL协议构建的,可进行加密传输、身份认证的网络协议,比HTTP协议安全。
HTTPS的优势
- 1、内容加密,建立一个信息的安全通道,来保证数据传输过程的安全性。
- 2、身份认证,确认网站的真是性。
- 3、数据完整性,防止内容被第三方冒充或者篡改。
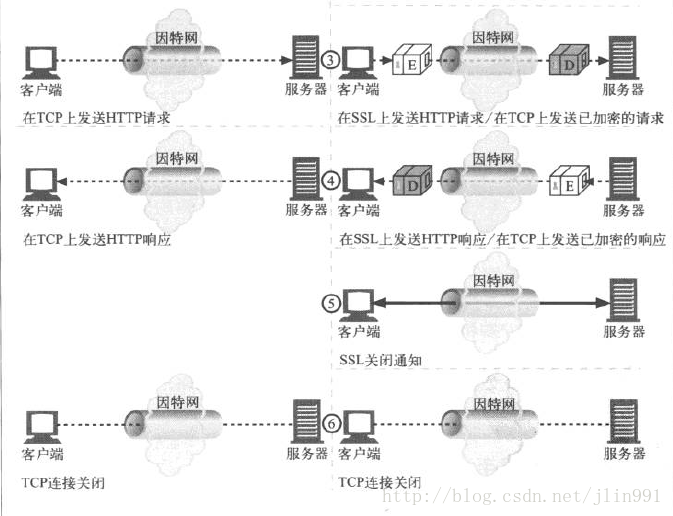
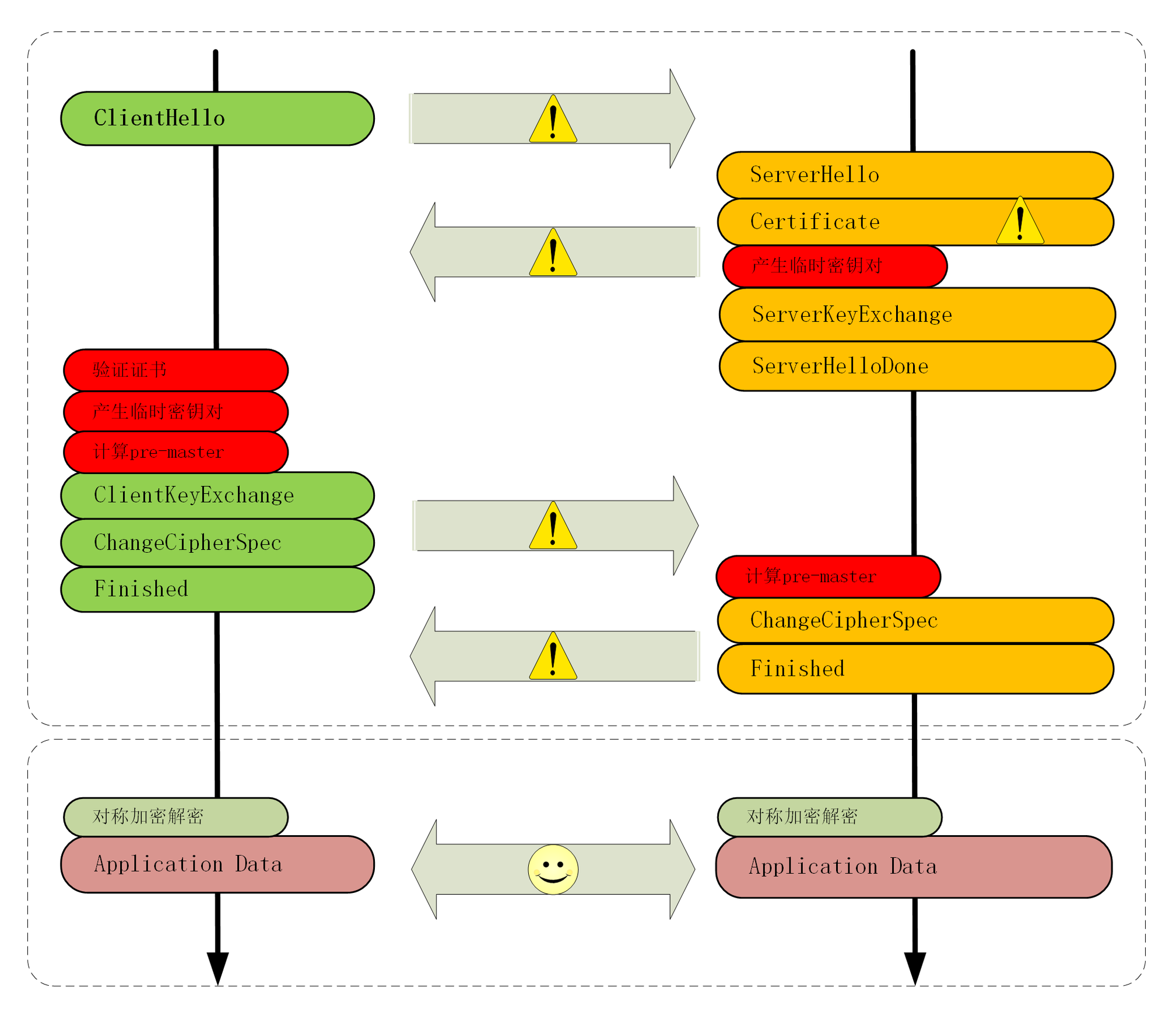
HTTPS请求过程
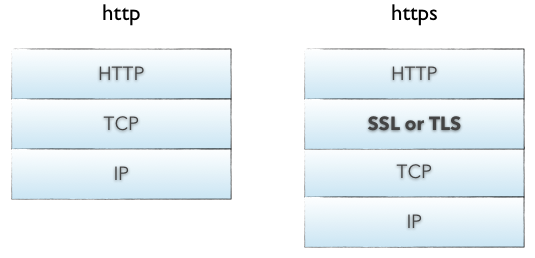
HTTPS协议的本质就是HTTP + SSL(or TLS)。在HTTP报文进入TCP报文之前,先使用SSL对HTTP报文进行加密。从网络的层级结构看它位于HTTP协议与TCP协议之间。
HTTPS在传输数据之前需要客户端与服务器进行一个握手(TLS/SSL握手),在握手过程中将确立双方加密传输数据的密码信息。
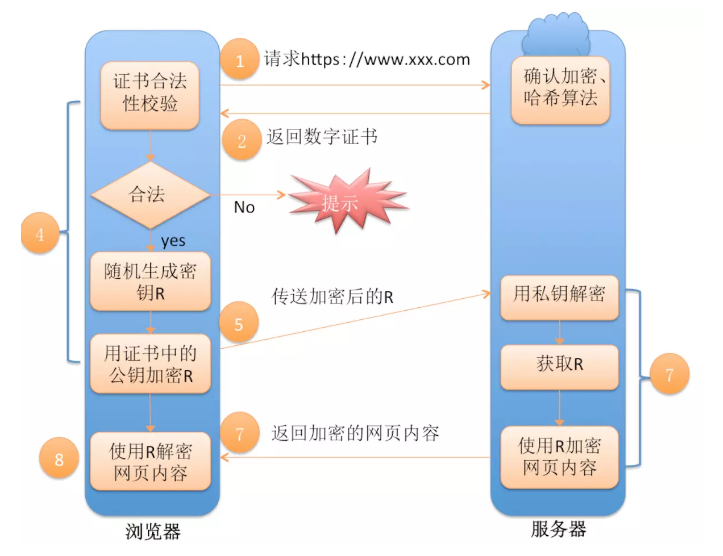
1、浏览器发起往服务器的 443 端口发起请求,请求携带了浏览器支持的加密算法和哈希算法。
2、服务器收到请求,选择浏览器支持的加密算法和哈希算法。
3、服务器将数字证书返回给浏览器,这里的数字证书可以是向某个可靠机构申请的,也可以是自制的。
(注释:证书包括以下这些内容:1. 证书序列号。2. 证书过期时间。3. 站点组织名。4. 站点DNS主机名。5. 站点公钥。6. 证书颁发者名。7. 证书签名。因为证书是要给大家用的,所以不需要加密传输)
4、浏览器进入数字证书认证环节,这一部分是浏览器内置的 TSL 完成的:
4.1 首先浏览器会从内置的证书列表中索引,找到服务器下发证书对应的机构,如果没有找到,此时就会提示用户该证书是不是由权威机构颁发,是不可信任的。如果查到了对应的机构,则取出该机构颁发的公钥。
4.2 用机构的证书公钥解密得到证书的内容和证书签名,内容包括网站的网址、网站的公钥、证书的有效期等。浏览器会先验证证书签名的合法性(验证过程类似上面 Bob 和 Susan 的通信)。
签名通过后,浏览器验证证书记录的网址是否和当前网址是一致的,不一致会提示用户。如果网址一致会检查证书有效期,证书过期了也会提示用户。这些都通过认证时,浏览器就可以安全使用证书中的网站公钥了。
4.3 浏览器生成一个随机数 R,并使用网站公钥对 R 进行加密。
5、浏览器将加密的 R 传送给服务器。
6、服务器用自己的私钥解密得到 R。
7、服务器以 R 为密钥使用了对称加密算法加密网页内容并传输给浏览器。
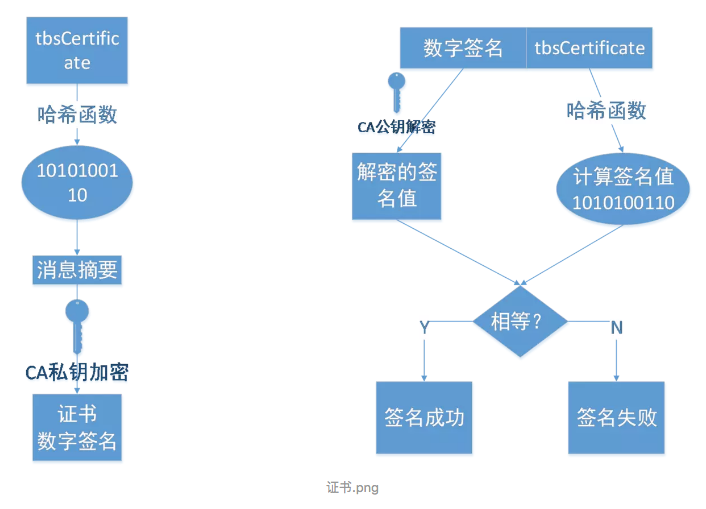
8、浏览器以 R 为密钥使用之前约定好的解密算法获取网页内容。数字证书如何认证? 首先你的证书会在https握手过程中被传递到浏览器,浏览器从你的证书中找到了颁发者,从颁发者的证书(如果你电脑上有的话)又找到了CA的证书
(CA证书会在操作系统安装时就安装好,所以每个人电脑上都有根证书),使用CA证书中带的公钥来对颁发者证书做验签,一旦匹配,说明你电脑上的颁发者证书不是伪造的,
同理,再用颁发者证书中的公钥去验证你的证书,以此证明你的证书不是伪造的。这样整个链状的验证,从而确保你的证书一定是直接或间接从CA签发的,
这样浏览器地址栏会显示一个绿色的盾牌,表示你的网站能通过证书验证。
如果你的电脑上没有颁发者证书(断链)或者你自己本身就是自签名证书(自己做CA,但是要记得,人家电脑上并没有装你的自签名根证书),那么浏览器会报警提示不能验证证书,问你是否还需要继续。
HTTPS 连接大致上可以划分为两个部分,第一个是建立连接时时的非对称加密握手,第二个是握手后的对称加密报文传输。
在最差的情况下,也就是不做任何的优化措施,HTTPS 建立连立连接可能会比HTTP 慢上几百毫秒甚至几秒,这其中既有网络耗时,也有计算耗时,就会让人产生“打开一个 HTTPS 网站好慢啊”的感觉。
HTTPS优化
硬件优化
更快的CPU
SSL加速卡 如:阿里的Tengine
SSL加速服务器
软件优化
软件升级 如:Linux 内核由 2.x 升级到 4.x,把 把 Nginx 由 1.6 升级到 1.16,把 OpenSSL 由 1.0.1 升级到 1.1.0/1.1.1。
协议优化
采用 TLS1.3
握手时使用的密钥交换协议应当尽量选用椭圆曲线的 ECDHE 算法。它不仅运算速度快,安全性高,还支持“False Start”
椭圆曲线也要选择高性能的曲线,最好是 x25519,次优选择是 P-256。对称加密算法方面,也可以选用“AES_128_GCM”,它能比“AES_256_GCM”略快一点点。
证书优化
采用选择椭圆曲线(ECDSA)证书而不是 RSA 证书,因为 224 位的 ECC 相当于 2048 位的 RSA,节约带宽和计算量
“OCSP Stapling”(OCSP 装订),它可以让服务器预先访问 CA 获取 OCSP 响应,然后在握手时随着证书一起发给客户端,免去了客户端连接 CA 服务器查询的时间。
会话复用
会话复用的效果类似 Cache,前提是客户端必须之前成功建立连接,后面就可以用“Session ID”“Session Ticket”等凭据跳过密钥交换、证书验证等步骤,直接开始加密通信。
Glide缓存机制
Glide5大磁盘缓存策略DiskCacheStrategy.DATA: 只缓存原始图片;DiskCacheStrategy.RESOURCE:只缓存转换过后的图片;DiskCacheStrategy.ALL:既缓存原始图片,也缓存转换过后的图片;对于远程图片,缓存 DATA和 RESOURCE;对于本地图片,只缓存 RESOURCE;DiskCacheStrategy.NONE:不缓存任何内容;DiskCacheStrategy.AUTOMATIC:默认策略,尝试对本地和远程图片使用最佳的策略。当下载网络图片时,使用DATA;对于本地图片,使用RESOURCE;
1 | // key是为了解决缓存图片的唯一性 |
内存缓存逻辑:首先通过loadFromActiveResources从弱引用读取;如果没有再通过loadFromCache从LruCache读取;2者中的任意一个获取到数据就会调用onResourceReady就是将资源回调给ImageView去加载。
Glide缓存分为弱引用(WeakReference) + LruCache + DiskLruCache,其中读取数据的顺序是:弱引用 > LruCache > DiskLruCache>网络;写入缓存的顺序是:网络 –> DiskLruCache–> LruCache–>弱引用
内存缓存分为弱引用的和 LruCache ,其中正在使用的图片使用弱引用缓存,暂时不使用的图片用 LruCache缓存,这一点是通过 图片引用计数器(acquired变量)来实现的,详情可以看内存缓存的小结。
磁盘缓存就是通过DiskLruCache实现的,根据缓存策略的不同会获取到不同类型的缓存图片。它的逻辑是:先从转换后的缓存中取;没有的话再从原始的(没有转换过的)缓存中拿数据;再没有的话就从网络加载图片数据,获取到数据之后,再依次缓存到磁盘和弱引用。
Glide内存优化
首先,内存总量有限,必须限制图片加载的内存
弱引用
这个大家都懂,好多第三方加载组件也体现了这个思路。
最早,大家将Bitmap用弱引用管理起来,当内存不足时,系统会自动GC回收掉部分引用,从而达到内存管理的目的。 这种方式很简单,组件本身不管理图片内存,而是交给GC,有GC来自动回收内存。
这种方法会有几个问题:
应用占有的内存量会不断攀升,知道内存不足时,出现断崖时的内存回收
GC的时间可能会比较长,造成界面会有明显的卡顿。
GC回收的内存,没有区分,可能回收了最近在使用的Bitmap,造成二次加载。
最严重的,新的Android系统开始每次GC都会回收弱引用,这就使内存缓存没有用处。
强引用+LRU算法
基于以上问题,有些组件开始用强引用+LRU算法的方式处理图片加载的问题,其思路大概是:
给定一个固定图片缓存大小,将所有的使用的Bitmap用强引用的方式管理起来,并利用LRU算法,将旧的Bitmap释放,新的bitmap增加。
这样,图片缓存不会无限制的增长,内存量也能处在一个较理想的范围,申请和释放。UIL就是采用这种方法。
但这个思路也会有问题:
图片缓存的内存不会无限制增长,但会周期性的释放和申请。特别是对于一个长列表页面,图片会不断的申请,不断的释放。因为最终的内存释放还是GC去处理,快速滑动时,会造成大量的图片申请内存,大量的图片释放,系统的GC会很频繁,就产生了所谓的内存抖动。
内存的抖动同样也会造成界面卡顿,在快速滑动时,会非常明显。
提到界面卡顿,我要说明下卡顿的原因。
人眼能识别的帧数是一秒24帧,就是所若一个屏幕以每秒24帧显示时,人眼是看不出什么的,感觉很流畅。但若少于24帧,我们就能感觉出卡顿,不流畅。 最佳的帧数是每秒60帧,再高就没有任何意义了,一般显卡会跟屏幕的刷新速率保持一致,大部分都是60hz。
那我们来计算下,最高60帧,1000ms/60帧=16ms/帧,最低24帧,1000ms/24帧=42ms,也就是说每次ui线程里面的计算最佳的情况是少于16ms,最高则不能超过42ms。
以ListView为例,getView的运行时间不能大于42ms, 推荐大家用hugo统计运行时间,很方便。
特殊情况下,即便是不大于42ms,接近也会造成卡顿,因为还会有其他的函数运行。
在这种情况下,若出现内存抖动,就会频繁的暂停进程,释放内存,极易出现卡顿。
GLide的BitmapPool
Glide对这个环节做了非常好的优化,解决了内存抖动的问题。
Glide构建了一个BitmapPool,Bitmap申请和回收都是透过BitmapPool来处理的。新加载图片时,会先从BitmapPool里面找有没有相应大小的Bitmap,有则直接使用,没有才会申请新的Bitmap;回收时,则会提交给BitmapPool, 供下次使用。
这种方式极大的减少了Bitmap的申请和回收操作,使得GC频度降低了很多。
图片与显示区域大小一致
图片加载最终的目的是显示到界面上,因此若是图片缓存的尺寸大于显示区域的尺寸是没有必要的。不光是造成内存浪费,占用较大的内存,而且会造成图片解析速度比较慢。
因此,不管是UIL,Glide和Freso等等都建议ImageView需要给定固定的长和宽,这样图片加载时,就可以根据显示区域的大小,加载最小的图片,又不会造成损失。
另外,七牛的云服务提供了imageView2参数,可以给定长宽,在网络加载层次上就可以降低加载的图片尺寸,提高加载速度。
另外,UIL,Glide都将缩放后的图片缓存到本地,下次加载时直接从磁盘缓存加载,也会有比原始尺寸加载更好的速度。
图片的加载优化有很多内容可以做,比如现在的图片加载,都是等将要显示时开始加载,这样图片可能需要等待一下才能加载出来,我们是不是可以提前加载呢?
强引用 弱应用 软引用 虚引用
- 强引用
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出
OutOfMmoryError错误,使程序异常终止,也不会靠随意回收具有强引用对象来解决内存不足的问题。
- 软引用
软引用是用来描述一些还有用但并非必须的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。
软引用关联的对象不会被
GC回收。JVM在分配空间时,若果Heap空间不足,就会进行相应的GC,但是这次GC并不会收集软引用关联的对象,但是在JVM发现就算进行了一次回收后还是不足(Allocation Failure),JVM会尝试第二次GC,回收软引用关联的对象。像这种如果内存充足,
GC时就保留,内存不够,GC再来收集的功能很适合用在缓存的引用场景中。在使用缓存时有一个原则,如果缓存中有就从缓存获取,如果没有就从数据库中获取,缓存的存在是为了加快计算速度,如果因为缓存导致了内存不足进而整个程序崩溃,那就得不偿失了。
- 弱引用
弱引用也是用来描述非必须对象的,他的强度比软引用更弱一些,被弱引用关联的对象,在垃圾回收时,如果这个对象只被弱引用关联(没有任何强引用关联他),那么这个对象就会被回收。
设计
WeakHashMap类是为了解决一个有趣的问题。如果有一个值,对应的键已经不再 使用了, 将会出现什么情况呢? 假定对某个键的最后一次引用已经消亡,不再有任何途径引 用这个值的对象了。但是,由于在程序中的任何部分没有再出现这个键,所以,这个键 / 值 对无法从映射中删除。为什么垃圾回收器不能够删除它呢? 难道删除无用的对象不是垃圾回 收器的工作吗?遗憾的是,事情没有这样简单。垃圾回收器跟踪活动的对象。只要映射对象是活动的, 其中的所有桶也是活动的, 它们不能被回收。因此,需要由程序负责从长期存活的映射表中 删除那些无用的值。 或者使用
WeakHashMap完成这件事情。当对键的唯一引用来自散列条
目时, 这一数据结构将与垃圾回收器协同工作一起删除键 / 值对。下面是这种机制的内部运行情况。
WeakHashMap使用弱引用(weak references) 保存键。WeakReference对象将引用保存到另外一个对象中,在这里,就是散列键。对于这种类型的 对象,垃圾回收器用一种特有的方式进行处理。通常,如果垃圾回收器发现某个特定的对象 已经没有他人引用了,就将其回收。然而, 如果某个对象只能由WeakReference引用, 垃圾 回收器仍然回收它,但要将引用这个对象的弱引用放人队列中。WeakHashMap将周期性地检 查队列, 以便找出新添加的弱引用。一个弱引用进人队列意味着这个键不再被他人使用, 并 且已经被收集起来。于是,WeakHashMap将删除对应的条目。除了
WeakHashMap使用了弱引用,ThreadLocal类中也是用了弱引用。
- 虚引用
一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来获取一个对象的实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。虚引用和弱引用对关联对象的回收都不会产生影响,如果只有虚引用活着弱引用关联着对象,那么这个对象就会被回收。它们的不同之处在于弱引用的
get方法,虚引用的get方法始终返回null,弱引用可以使用ReferenceQueue,虚引用必须配合ReferenceQueue使用。
jdk中直接内存的回收就用到虚引用,由于jvm自动内存管理的范围是堆内存,而直接内存是在堆内存之外(其实是内存映射文件,自行去理解虚拟内存空间的相关概念),所以直接内存的分配和回收都是有Unsafe类去操作,java在申请一块直接内存之后,会在堆内存分配一个对象保存这个堆外内存的引用,这个对象被垃圾收集器管理,一旦这个对象被回收,相应的用户线程会收到通知并对直接内存进行清理工作。
SharedPreferences apply和commit的区别
commit特点如下
- 存储的过程是原子操作
- commit方法有返回值,设置成功为ture,否则为false
- 同时对一个SharedPreferences设置值最后一次的设置会直接覆盖前次值
- 如果不关心设置成功与否,并且是在主线程设置值,建议用apply方法
apply特点如下
- 存储的过程也是原子操作
- apply没有返回值,存储是否成功无从知道。
- apply写入过程分两步,第一步先同步写入内存,第二部在异步写入物理磁盘。并且写入的过程会阻塞同一个SharedPreferences对象的其他写入操作。
原子操作的意思是”不可中断的一个或一系列操作”,通俗的讲一个操作一旦开始,在结束前不会被打断。比如常见的++i操作就不具有原子性,因为它实际上包含了3个步骤,1-读取i的值,2-对读取的i值加1,3-写入加1后的值。单独看此三个步骤都是原子操作,但组合起来就是非原子操作了。
总结
commit相对于apply效率较低,commit直接是向物理介质写入内容,而apply是先同步将内容提交到内存,然后在异步的向物理介质写入内容。这样做显然提高了效率。
Message的源码
1 | public Object obj; // 用来保存对象 |
Messenger与Message的区别
Messenger 可以翻译为信使,顾名思义,通过它可以在不同进程中传递Message对象.
Message 可以翻译为信封,顾名思义,信封里附带着数据
Messenger
Messenger是一种轻量级的IPC方案,它的底层实现是AIDL,为什么这么说呢,大致看一下Messenger这个类的构造方法就明白了。
1 | /** |
从Messenger两个构造方法的实现上我们可以明显看出AIDL的痕迹,不管是IMessenger还是Stub.asInterface,这种使用方法都表明它的底层是AIDL。
我们接着来看Messenger的两个重要方法:
getBinder() : 返回一个IBinder对象,一般在服务端的onBind方法调用这个方法,返回给客户端一个IBinder对象
send(Message msg) : 发送一个message对象到messengerHandler。这里,我们传递的参数是一个Message对象,
Messenge
如果说Messenger充当了信使的角色,那么Message就充当了一个信封的角色。同样地,先看官方文档的描述:
Defines a message containing a description and arbitrary data object that can be sent to a Handler. This object contains two extra int fields and an extra object field that allow you to not do allocations in many cases.While the constructor of Message is public,the best way to get one of these is to call Message.obtain() or one of the Handler.obtainMessage() methods, which will pull them from a pool of recycled objects.
从官文的描述可知,该Message对象含有两个Int型的属性和一个object型的属性,然后创建Message的实例,最好调用Message.obtain()方法而不是直接通过构造器。我们来看看主要参数以及重要方法:
- 属性 public int arg1,public int arg2,public Object obj : 一般这三个属性用于保存数据,其中Object对象用于保存一个对象。
- 属性 public Messenger replyTo : 这个属性一般用于服务端需要返回消息给客户端的时候用到,下面会说到。
- 属性 public int what:这个属性用于描述这个message,一般在实例化的时候会传递这个参数。
- 方法 obtain():提供了多个参数的重载方法,为了获得message实例。
- setData(Bundle data):设置obj的值,Bundle将在下节单独讲一下。
实现举例
Messenger的使用方法很简单,它对AIDL做了封装,使得我们可以更简便地进行进程间通信。同时,由于因为Handler的机制一次处理一个请求,因此在服务端我们不用考虑线程同步的问题。实现一个Messenger有如下几个步骤,分为服务端和客户端。
1. 创建一个Service
首先,我们需要在服务端创建一个Service来处理客户端的连接请求,同时创建一个Handler并通过它来创建一个Messenger对象,然后在Service的onBind中返回这个Messenger对象底层的Binder即可。
代码如下:
1 | public class MessengerService extends Service{ |
2. 声明进程
然后,在AndroidManifest中声明Service并给一个进程名,使该服务成为一个单独的进程。
AndroidManifest配置如下:
1 | <service android:name=".MessengerService" |
3. 创建客户端
户端进程中,首先要绑定服务端的Service,绑定成功后用服务端返回的IBinder对象创建一个Messenger,通过这个Messenger就可以向服务端发送消息了,发消息类型为Message对象。这听起来可能还是有点抽象,不过看了下面的两个例子,读者肯定就都明白了。首先,我们来看一个简单点的例子,在这个例子中服务端无法回应客户端。
首先看服务端的代码,这是服务端的典型代码,可以看到MessengerHandler用来处理客户端发送的消息,并从消息中取出客户端发来的文本信息。而mMessenger是一个Messenger对象,它和MessengerHandler相关联,并在onBind方法中返回它里面的Binder对象,可以看出,这里Messenger的作用是将客户端发送的消息传递给MessengerHandler处理。
1 | public class MessengerActivity extends Activity{ |
通过以上代码,可以看到Messenger的使用方法:
- 服务实现一个Handler,由其接收来自客户端的每个调用的回调。
- Handler用于创建Messenger对象(对Handler的引用)。
- Messenger创建一个IBinder,服务通过onBind()使其返回客户端。
- 客户端使用IBinder将Messenger(引用服务的Handler)实例化,然后使用后者将Message对象发送给服务。
- 服务在其Handler中(具体地讲,是在handleMessage()方法中)接收每个Message。
这样,客户端并没有调用服务的“方法”。而客户端传递的“消息”(Message对象)是服务在其Handler中接收的。
结语
注意,绑定解绑服务最好在onstart和onStop内,在activity的生命周期里,onStart和onStop是activity在栈顶与否的出口和入口,我们的服务一般是绑定当前activity,顾在这两个位置比较合适。
另外,如果需要服务端能够回应客户端,就和服务端一样,我们还需要创建一个Handler并创建一个新的Messenger,并把这个Messenger对象通过Message的replyTo参数传递给服务端,服务端通过这个replyTo参数就可以回应客户端。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 nathanwriting@126.com

