Android音视频开发初级入门篇 Android 音视频开发(一) : 通过三种方式绘制图片 在 Android 音视频开发学习思路 里面,我们写到了,想要逐步入门音视频开发,就需要一步步的去学习整理,并积累。本文是音视频开发积累的第一篇。 对应的要学习的内容是:在 Android 平台绘制一张图片,使用至少 3 种不同的 API,ImageView,SurfaceView,自定义 View。
ImageView 绘制图片 这个想必做过Android开发的都知道如何去绘制了。很简单:
1 2 Bitmap bitmap = BitmapFactory.decodeFile(Environment.getExternalStorageDirectory().getPath() + File.separator + "11.jpg"); imageView.setImageBitmap(bitmap);
很轻松,在界面上看到了我们绘制的图片。
SurfaceView 绘制图片 这个比 ImageView 绘制图片稍微复杂一点点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 SurfaceView surfaceView = (SurfaceView) findViewById(R.id.surface); surfaceView.getHolder().addCallback(new SurfaceHolder.Callback() { @Override public void surfaceCreated(SurfaceHolder surfaceHolder) { if (surfaceHolder == null) { return; } Paint paint = new Paint(); paint.setAntiAlias(true); paint.setStyle(Paint.Style.STROKE); Bitmap bitmap = BitmapFactory.decodeFile(Environment.getExternalStorageDirectory().getPath() + File.separator + "11.jpg"); // 获取bitmap Canvas canvas = surfaceHolder.lockCanvas(); // 先锁定当前surfaceView的画布 canvas.drawBitmap(bitmap, 0, 0, paint); //执行绘制操作 surfaceHolder.unlockCanvasAndPost(canvas); // 解除锁定并显示在界面上 } @Override public void surfaceChanged(SurfaceHolder surfaceHolder, int i, int i1, int i2) { } @Override public void surfaceDestroyed(SurfaceHolder surfaceHolder) { } });
自定义 View 绘制图片 这个有绘制自定义View经验的可以很轻松的完成,本人也简单整理过 Android 自定义 View 绘制 这一块的知识:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class CustomView extends View { Paint paint = new Paint(); Bitmap bitmap; public CustomView(Context context) { super(context); paint.setAntiAlias(true); paint.setStyle(Paint.Style.STROKE); bitmap = BitmapFactory.decodeFile(Environment.getExternalStorageDirectory().getPath() + File.separator + "11.jpg"); // 获取bitmap } @Override protected void onDraw(Canvas canvas) { super.onDraw(canvas); // 不建议在onDraw做任何分配内存的操作 if (bitmap != null) { canvas.drawBitmap(bitmap, 0, 0, paint); } } }
注:别忘记了权限,*否则是不会展示成功的。*
1 <uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
这三种方式都成功了展示出来了,我们可以继续学习并整理后面的知识了
Android 音视频开发(二):使用 AudioRecord 采集音频PCM并保存到文件 AudioRecord API详解 AudioRecord是Android系统提供的用于实现录音的功能类。
要想了解这个类的具体的说明和用法,我们可以去看一下官方的文档:
AndioRecord类的主要功能是让各种JAVA应用能够管理音频资源,以便它们通过此类能够录制声音相关的硬件所收集的声音。此功能的实现就是通过”pulling”(读取)AudioRecord对象的声音数据来完成的。在录音过程中,应用所需要做的就是通过后面三个类方法中的一个去及时地获取AudioRecord对象的录音数据. AudioRecord类提供的三个获取声音数据的方法分别是read(byte[], int, int), read(short[], int, int), read(ByteBuffer, int). 无论选择使用那一个方法都必须事先设定方便用户的声音数据的存储格式。 开始录音的时候,AudioRecord需要初始化一个相关联的声音buffer, 这个buffer主要是用来保存新的声音数据。这个buffer的大小,我们可以在对象构造期间去指定。它表明一个AudioRecord对象还没有被读取(同步)声音数据前能录多长的音(即一次可以录制的声音容量)。声音数据从音频硬件中被读出,数据大小不超过整个录音数据的大小(可以分多次读出),即每次读取初始化buffer容量的数据。
实现Android录音的流程为:
构造一个AudioRecord对象,其中需要的最小录音缓存buffer大小可以通过getMinBufferSize 方法得到。如果buffer容量过小,将导致对象构造的失败。
初始化一个buffer,该buffer大于等于AudioRecord对象用于写声音数据的buffer大小。
开始录音
创建一个数据流,一边从AudioRecord中读取声音数据到初始化的buffer,一边将buffer中数据导入数据流。
关闭数据流
停止录音
使用 AudioRecord 实现录音,并生成wav 创建一个AudioRecord对象 首先要声明一些全局的变量参数:
1 2 private AudioRecord audioRecord = null; // 声明 AudioRecord 对象 private int recordBufSize = 0; // 声明recoordBufffer的大小字段
获取buffer的大小并创建AudioRecord:
1 2 3 4 public void createAudioRecord() { recordBufSize = AudioRecord.getMinBufferSize(frequency, channelConfiguration, EncodingBitRate); //audioRecord能接受的最小的buffer大小 audioRecord = new AudioRecord(MediaRecorder.AudioSource.MIC, frequency, channelConfiguration, EncodingBitRate, recordBufSize); }
初始化一个buffer 1 byte data[] = new byte[recordBufSize];
开始录音 1 2 audioRecord.startRecording(); isRecording = true;
创建一个数据流,一边从AudioRecord中读取声音数据到初始化的buffer,一边将buffer中数据导入数据流。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 FileOutputStream os = null; try { os = new FileOutputStream(filename); } catch (FileNotFoundException e) { e.printStackTrace(); } if (null != os) { while (isRecording) { read = audioRecord.read(data, 0, recordBufSize); // 如果读取音频数据没有出现错误,就将数据写入到文件 if (AudioRecord.ERROR_INVALID_OPERATION != read) { try { os.write(data); } catch (IOException e) { e.printStackTrace(); } } } try { os.close(); } catch (IOException e) { e.printStackTrace(); } }
关闭数据流 修改标志位:isRecording 为false,上面的while循环就自动停止了,数据流也就停止流动了,Stream也就被关闭了。
停止录音 停止录音之后,注意要释放资源。
1 2 3 4 5 6 if (null != audioRecord) { audioRecord.stop(); audioRecord.release(); audioRecord = null; recordingThread = null; }
注:权限需求:WRITE_EXTERNAL_STORAGE、RECORD_AUDIO
到现在基本的录音的流程就介绍完了。但是这时候,有人就提出问题来了:
1)、我按照流程,把音频数据都输出到文件里面了,停止录音后,打开此文件,发现不能播放,到底是为什么呢?
答:按照流程走完了,数据是进去了,但是现在的文件里面的内容仅仅是最原始的音频数据,术语称为raw(中文解释是“原材料”或“未经处理的东西”),这时候,你让播放器去打开,它既不知道保存的格式是什么,又不知道如何进行解码操作。当然播放不了。
2)、那如何才能在播放器中播放我录制的内容呢?
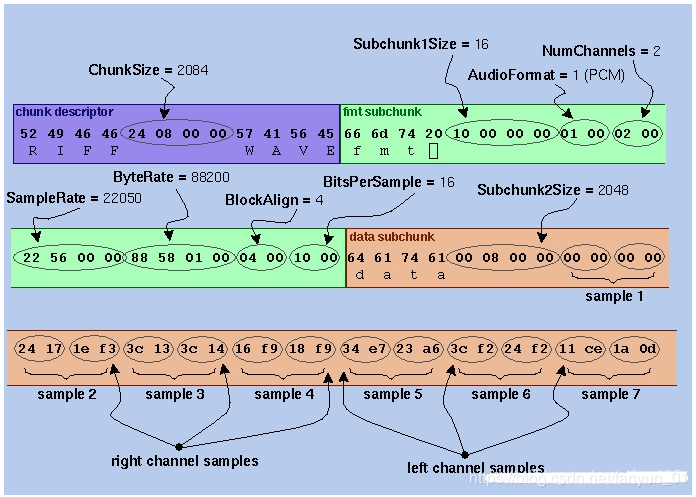
答: 在文件的数据开头加入WAVE HEAD数据即可,也就是文件头 。只有加上文件头部的数据,播放器才能正确的知道里面的内容到底是什么,进而能够正常的解析并播放里面的内容。具体的头文件的描述,在 Play a WAV file on an AudioTrack 里面可以进行了解。
添加WAVE文件头的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 public class PcmToWavUtil { /** * 缓存的音频大小 */ private int mBufferSize; /** * 采样率 */ private int mSampleRate; /** * 声道数 */ private int mChannel; /** * @param sampleRate sample rate、采样率 * @param channel channel、声道 * @param encoding Audio data format、音频格式 */ PcmToWavUtil(int sampleRate, int channel, int encoding) { this.mSampleRate = sampleRate; this.mChannel = channel; this.mBufferSize = AudioRecord.getMinBufferSize(mSampleRate, mChannel, encoding); } /** * pcm文件转wav文件 * * @param inFilename 源文件路径 * @param outFilename 目标文件路径 */ public void pcmToWav(String inFilename, String outFilename) { FileInputStream in; FileOutputStream out; long totalAudioLen; long totalDataLen; long longSampleRate = mSampleRate; int channels = mChannel == AudioFormat.CHANNEL_IN_MONO ? 1 : 2; long byteRate = 16 * mSampleRate * channels / 8; byte[] data = new byte[mBufferSize]; try { in = new FileInputStream(inFilename); out = new FileOutputStream(outFilename); totalAudioLen = in.getChannel().size(); totalDataLen = totalAudioLen + 36; writeWaveFileHeader(out, totalAudioLen, totalDataLen, longSampleRate, channels, byteRate); while (in.read(data) != -1) { out.write(data); } in.close(); out.close(); } catch (IOException e) { e.printStackTrace(); } } /** * 加入wav文件头 */ private void writeWaveFileHeader(FileOutputStream out, long totalAudioLen, long totalDataLen, long longSampleRate, int channels, long byteRate) throws IOException { byte[] header = new byte[44]; // RIFF/WAVE header header[0] = 'R'; header[1] = 'I'; header[2] = 'F'; header[3] = 'F'; header[4] = (byte) (totalDataLen & 0xff); header[5] = (byte) ((totalDataLen >> 8) & 0xff); header[6] = (byte) ((totalDataLen >> 16) & 0xff); header[7] = (byte) ((totalDataLen >> 24) & 0xff); //WAVE header[8] = 'W'; header[9] = 'A'; header[10] = 'V'; header[11] = 'E'; // 'fmt ' chunk header[12] = 'f'; header[13] = 'm'; header[14] = 't'; header[15] = ' '; // 4 bytes: size of 'fmt ' chunk header[16] = 16; header[17] = 0; header[18] = 0; header[19] = 0; // format = 1 header[20] = 1; header[21] = 0; header[22] = (byte) channels; header[23] = 0; header[24] = (byte) (longSampleRate & 0xff); header[25] = (byte) ((longSampleRate >> 8) & 0xff); header[26] = (byte) ((longSampleRate >> 16) & 0xff); header[27] = (byte) ((longSampleRate >> 24) & 0xff); header[28] = (byte) (byteRate & 0xff); header[29] = (byte) ((byteRate >> 8) & 0xff); header[30] = (byte) ((byteRate >> 16) & 0xff); header[31] = (byte) ((byteRate >> 24) & 0xff); // block align header[32] = (byte) (2 * 16 / 8); header[33] = 0; // bits per sample header[34] = 16; header[35] = 0; //data header[36] = 'd'; header[37] = 'a'; header[38] = 't'; header[39] = 'a'; header[40] = (byte) (totalAudioLen & 0xff); header[41] = (byte) ((totalAudioLen >> 8) & 0xff); header[42] = (byte) ((totalAudioLen >> 16) & 0xff); header[43] = (byte) ((totalAudioLen >> 24) & 0xff); out.write(header, 0, 44); } }
附言 Android SDK 提供了两套音频采集的API,分别是:MediaRecorder 和 AudioRecord,前者是一个更加上层一点的API,它可以直接把手机麦克风录入的音频数据进行编码压缩(如AMR、MP3等)并存成文件,而后者则更接近底层,能够更加自由灵活地控制,可以得到原始的一帧帧PCM音频数据。如果想简单地做一个录音机,录制成音频文件,则推荐使用 MediaRecorder,而如果需要对音频做进一步的算法处理、或者采用第三方的编码库进行压缩、以及网络传输等应用,则建议使用 AudioRecord,其实 MediaRecorder 底层也是调用了 AudioRecord 与 Android Framework 层的 AudioFlinger 进行交互的。直播中实时采集音频自然是要用AudioRecord了。
源码 https://github.com/renhui/AudioDemo
Android 音视频开发(三):使用 AudioTrack 播放PCM音频 AudioTrack 基本使用 AudioTrack 类可以完成Android平台上音频数据的输出任务。AudioTrack有两种数据加载模式(MODE_STREAM和MODE_STATIC),对应的是数据加载模式和音频流类型, 对应着两种完全不同的使用场景。
MODE_STREAM:在这种模式下,通过write一次次把音频数据写到AudioTrack中。这和平时通过write系统调用往文件中写数据类似,但这种工作方式每次都需要把数据从用户提供的Buffer中拷贝到AudioTrack内部的Buffer中,这在一定程度上会使引入延时。为解决这一问题,AudioTrack就引入了第二种模式。
MODE_STATIC:这种模式下,在play之前只需要把所有数据通过一次write调用传递到AudioTrack中的内部缓冲区,后续就不必再传递数据了。这种模式适用于像铃声这种内存占用量较小,延时要求较高的文件。但它也有一个缺点,就是一次write的数据不能太多,否则系统无法分配足够的内存来存储全部数据。
MODE_STATIC模式 MODE_STATIC模式输出音频的方式如下(注意:如果采用STATIC模式,须先调用write写数据,然后再调用play。 ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 public class AudioTrackPlayerDemoActivity extends Activity implements OnClickListener { private static final String TAG = "AudioTrackPlayerDemoActivity"; private Button button; private byte[] audioData; private AudioTrack audioTrack; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); super.setContentView(R.layout.main); this.button = (Button) super.findViewById(R.id.play); this.button.setOnClickListener(this); this.button.setEnabled(false); new AsyncTask<Void, Void, Void>() { @Override protected Void doInBackground(Void... params) { try { InputStream in = getResources().openRawResource(R.raw.ding); try { ByteArrayOutputStream out = new ByteArrayOutputStream( 264848); for (int b; (b = in.read()) != -1;) { out.write(b); } Log.d(TAG, "Got the data"); audioData = out.toByteArray(); } finally { in.close(); } } catch (IOException e) { Log.wtf(TAG, "Failed to read", e); } return null; } @Override protected void onPostExecute(Void v) { Log.d(TAG, "Creating track..."); button.setEnabled(true); Log.d(TAG, "Enabled button"); } }.execute(); } public void onClick(View view) { this.button.setEnabled(false); this.releaseAudioTrack(); this.audioTrack = new AudioTrack(AudioManager.STREAM_MUSIC, 44100, AudioFormat.CHANNEL_OUT_STEREO, AudioFormat.ENCODING_PCM_16BIT, audioData.length, AudioTrack.MODE_STATIC); Log.d(TAG, "Writing audio data..."); this.audioTrack.write(audioData, 0, audioData.length); Log.d(TAG, "Starting playback"); audioTrack.play(); Log.d(TAG, "Playing"); this.button.setEnabled(true); } private void releaseAudioTrack() { if (this.audioTrack != null) { Log.d(TAG, "Stopping"); audioTrack.stop(); Log.d(TAG, "Releasing"); audioTrack.release(); Log.d(TAG, "Nulling"); } } public void onPause() { super.onPause(); this.releaseAudioTrack(); } }
MODE_STREAM模式 MODE_STREAM 模式输出音频的方式如下:
1 2 3 4 5 6 7 8 9 10 11 12 byte[] tempBuffer = new byte[bufferSize]; int readCount = 0; while (dis.available() > 0) { readCount = dis.read(tempBuffer); if (readCount == AudioTrack.ERROR_INVALID_OPERATION || readCount == AudioTrack.ERROR_BAD_VALUE) { continue; } if (readCount != 0 && readCount != -1) { audioTrack.play(); audioTrack.write(tempBuffer, 0, readCount); } }
AudioTrack 详解 音频流的类型 在AudioTrack构造函数中,会接触到AudioManager.STREAM_MUSIC这个参数。它的含义与Android系统对音频流的管理和分类有关。
Android将系统的声音分为好几种流类型,下面是几个常见的:
· STREAM_ALARM:警告声
· STREAM_MUSIC:音乐声,例如music等
· STREAM_RING:铃声
· STREAM_SYSTEM:系统声音,例如低电提示音,锁屏音等
· STREAM_VOCIE_CALL:通话声
注意:上面这些类型的划分和音频数据本身并没有关系。例如MUSIC和RING类型都可以是某首MP3歌曲。另外,声音流类型的选择没有固定的标准,例如,铃声预览中的铃声可以设置为MUSIC类型。音频流类型的划分和Audio系统对音频的管理策略有关。
Buffer分配和Frame的概念 在计算Buffer分配的大小的时候,我们经常用到的一个方法就是:getMinBufferSize。这个函数决定了应用层分配多大的数据Buffer。
1 2 3 AudioTrack.getMinBufferSize(8000,//每秒8K个采样点 AudioFormat.CHANNEL_CONFIGURATION_STEREO,//双声道 AudioFormat.ENCODING_PCM_16BIT);
从AudioTrack.getMinBufferSize开始追溯代码,可以发现在底层的代码中有一个很重要的概念:Frame(帧)。Frame是一个单位,用来描述数据量的多少。1单位的Frame等于1个采样点的字节数×声道数(比如PCM16,双声道的1个Frame等于2×2=4字节)。1个采样点只针对一个声道,而实际上可能会有一或多个声道。由于不能用一个独立的单位来表示全部声道一次采样的数据量,也就引出了Frame的概念。Frame的大小,就是一个采样点的字节数×声道数。另外,在目前的声卡驱动程序中,其内部缓冲区也是采用Frame作为单位来分配和管理的。
下面是追溯到的native层的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 // minBufCount表示缓冲区的最少个数,它以Frame作为单位 uint32_t minBufCount = afLatency / ((1000 *afFrameCount)/afSamplingRate); if(minBufCount < 2) minBufCount = 2;//至少要两个缓冲 //计算最小帧个数 uint32_tminFrameCount = (afFrameCount*sampleRateInHertz*minBufCount)/afSamplingRate; //下面根据最小的FrameCount计算最小的缓冲大小 intminBuffSize = minFrameCount //计算方法完全符合我们前面关于Frame的介绍 * (audioFormat == javaAudioTrackFields.PCM16 ? 2 : 1) * nbChannels; returnminBuffSize;
getMinBufSize会综合考虑硬件的情况(诸如是否支持采样率,硬件本身的延迟情况等)后,得出一个最小缓冲区的大小。一般我们分配的缓冲大小会是它的整数倍。
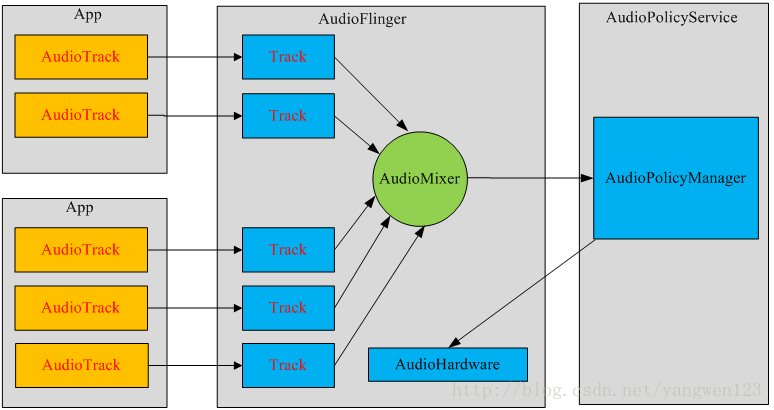
AudioTrack构造过程 每一个音频流对应着一个AudioTrack类的一个实例,每个AudioTrack会在创建时注册到 AudioFlinger中,由AudioFlinger把所有的AudioTrack进行混合(Mixer),然后输送到AudioHardware中进行播放,目前Android同时最多可以创建32个音频流,也就是说,Mixer最多会同时处理32个AudioTrack的数据流。
播放声音可以用MediaPlayer和AudioTrack,两者都提供了Java API供应用开发者使用。虽然都可以播放声音,但两者还是有很大的区别的。
区别 其中最大的区别是MediaPlayer可以播放多种格式的声音文件,例如MP3,AAC,WAV,OGG,MIDI等。MediaPlayer会在framework层创建对应的音频解码器。而AudioTrack只能播放已经解码的PCM流,如果对比支持的文件格式的话则是AudioTrack只支持wav格式的音频文件,因为wav格式的音频文件大部分都是PCM流。AudioTrack不创建解码器,所以只能播放不需要解码的wav文件。
联系 MediaPlayer在framework层还是会创建AudioTrack,把解码后的PCM数流传递给AudioTrack,AudioTrack再传递给AudioFlinger进行混音,然后才传递给硬件播放,所以是MediaPlayer包含了AudioTrack。
SoundPool 在接触Android音频播放API的时候,发现SoundPool也可以用于播放音频。下面是三者的使用场景:MediaPlayer 更加适合在后台长时间播放本地音乐文件或者在线的流式资源; SoundPool 则适合播放比较短的音频片段,比如游戏声音、按键声、铃声片段等等,它可以同时播放多个音频; 而 AudioTrack 则更接近底层,提供了非常强大的控制能力,支持低延迟播放,适合流媒体和VoIP语音电话等场景。
源码 https://github.com/renhui/AudioDemo
Android 音视频开发(四):使用 Camera API 采集视频数据 本文主要将的是:使用 Camera API 采集视频数据并保存到文件,分别使用 SurfaceView、TextureView 来预览 Camera 数据,取到 NV21 的数据回调。
注: 需要权限:**
预览 Camera 数据 做过Android开发的人一般都知道,有两种方法能够做到这一点:SurfaceView、TextureView。
下面是使用SurfaceView预览数据的方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 SurfaceView surfaceView; Camera camera; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); surfaceView = (SurfaceView) findViewById(R.id.surface_view); surfaceView.getHolder().addCallback(this); // 打开摄像头并将展示方向旋转90度 camera = Camera.open(); camera.setDisplayOrientation(90); } //------ Surface 预览 ------- @Override public void surfaceCreated(SurfaceHolder surfaceHolder) { try { camera.setPreviewDisplay(surfaceHolder); camera.startPreview(); } catch (IOException e) { e.printStackTrace(); } } @Override public void surfaceChanged(SurfaceHolder surfaceHolder, int format, int w, int h) { } @Override public void surfaceDestroyed(SurfaceHolder surfaceHolder) { camera.release(); }
下面是使用TextureView预览数据的方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 TextureView textureView; Camera camera; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); textureView = (TextureView) findViewById(R.id.texture_view); textureView.setSurfaceTextureListener(this);// 打开摄像头并将展示方向旋转90度 camera = Camera.open(); camera.setDisplayOrientation(90); } //------ Texture 预览 ------- @Override public void onSurfaceTextureAvailable(SurfaceTexture surfaceTexture, int i, int i1) { try { camera.setPreviewTexture(surfaceTexture); camera.startPreview(); } catch (IOException e) { e.printStackTrace(); } } @Override public void onSurfaceTextureSizeChanged(SurfaceTexture surfaceTexture, int i, int i1) { } @Override public boolean onSurfaceTextureDestroyed(SurfaceTexture surfaceTexture) { camera.release(); return false; } @Override public void onSurfaceTextureUpdated(SurfaceTexture surfaceTexture) { }
取到 NV21 的数据回调 Android 中Google支持的 Camera Preview Callback的YUV常用格式有两种:一个是NV21,一个是YV12。Android一般默认使用YCbCr_420_SP的格式(NV21)。
我们可以配置数据回调的格式:
1 2 3 Camera.Parameters parameters = camera.getParameters(); parameters.setPreviewFormat(ImageFormat.NV21); camera.setParameters(parameters);
通过setPreviewCallback方法监听预览的回调:
1 2 3 4 5 6 camera.setPreviewCallback(new Camera.PreviewCallback() { @Override public void onPreviewFrame(byte[] bytes, Camera camera) { } });
这里面的Bytes的数据就是NV21格式的数据。
在后面的文章中,会对这些数据进行处理,来满足相关的需求场景。
一个音视频文件是由音频和视频组成的,我们可以通过MediaExtractor、MediaMuxer把音频或视频给单独抽取出来,抽取出来的音频和视频能单独播放;
MediaExtractor的 作用是把音频和视频的数据进行分离。
主要API介绍:
setDataSource(String path):即可以设置本地文件又可以设置网络文件
getTrackCount():得到源文件通道数
getTrackFormat(int index):获取指定(index)的通道格式
getSampleTime():返回当前的时间戳
readSampleData(ByteBuffer byteBuf, int offset):把指定通道中的数据按偏移量读取到ByteBuffer中;
advance():读取下一帧数据
release(): 读取结束后释放资源
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 MediaExtractor extractor = new MediaExtractor(); extractor.setDataSource(...); int numTracks = extractor.getTrackCount(); for (int i = 0; i < numTracks; ++i) { MediaFormat format = extractor.getTrackFormat(i); String mime = format.getString(MediaFormat.KEY_MIME); if (weAreInterestedInThisTrack) { extractor.selectTrack(i); } } ByteBuffer inputBuffer = ByteBuffer.allocate(...) while (extractor.readSampleData(inputBuffer, ...) >= 0) { int trackIndex = extractor.getSampleTrackIndex(); long presentationTimeUs = extractor.getSampleTime(); ... extractor.advance(); } extractor.release(); extractor = null;
MediaMuxer的作用是生成音频或视频文件;还可以把音频与视频混合成一个音视频文件。
相关API介绍:
MediaMuxer(String path, int format):path:输出文件的名称 format:输出文件的格式;当前只支持MP4格式;
addTrack(MediaFormat format):添加通道;我们更多的是使用MediaCodec.getOutpurForma()或Extractor.getTrackFormat(int index)来获取MediaFormat;也可以自己创建;
start():开始合成文件
writeSampleData(int trackIndex, ByteBuffer byteBuf, MediaCodec.BufferInfo bufferInfo):把ByteBuffer中的数据写入到在构造器设置的文件中;
stop():停止合成文件
release():释放资源
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 MediaMuxer muxer = new MediaMuxer("temp.mp4", OutputFormat.MUXER_OUTPUT_MPEG_4); // More often, the MediaFormat will be retrieved from MediaCodec.getOutputFormat() // or MediaExtractor.getTrackFormat(). MediaFormat audioFormat = new MediaFormat(...); MediaFormat videoFormat = new MediaFormat(...); int audioTrackIndex = muxer.addTrack(audioFormat); int videoTrackIndex = muxer.addTrack(videoFormat); ByteBuffer inputBuffer = ByteBuffer.allocate(bufferSize); boolean finished = false; BufferInfo bufferInfo = new BufferInfo(); muxer.start(); while(!finished) { // getInputBuffer() will fill the inputBuffer with one frame of encoded // sample from either MediaCodec or MediaExtractor, set isAudioSample to // true when the sample is audio data, set up all the fields of bufferInfo, // and return true if there are no more samples. finished = getInputBuffer(inputBuffer, isAudioSample, bufferInfo); if (!finished) { int currentTrackIndex = isAudioSample ? audioTrackIndex : videoTrackIndex; muxer.writeSampleData(currentTrackIndex, inputBuffer, bufferInfo); } }; muxer.stop(); muxer.release();
使用情境 从MP4文件中提取视频并生成新的视频文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 public class MainActivity extends AppCompatActivity { private static final String SDCARD_PATH = Environment.getExternalStorageDirectory().getPath(); private MediaExtractor mMediaExtractor; private MediaMuxer mMediaMuxer; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); // 获取权限 int checkWriteExternalPermission = ContextCompat.checkSelfPermission(this, Manifest.permission.WRITE_EXTERNAL_STORAGE); int checkReadExternalPermission = ContextCompat.checkSelfPermission(this, Manifest.permission.READ_EXTERNAL_STORAGE);if (checkWriteExternalPermission != PackageManager.PERMISSION_GRANTED || checkReadExternalPermission != PackageManager.PERMISSION_GRANTED) { ActivityCompat.requestPermissions(this, new String[]{ Manifest.permission.WRITE_EXTERNAL_STORAGE, Manifest.permission.READ_EXTERNAL_STORAGE}, 0); } setContentView(R.layout.activity_main); new Thread(new Runnable() { @Override public void run() { try { process(); } catch (Exception e) { e.printStackTrace(); } } }).start(); } private boolean process() throws IOException { mMediaExtractor = new MediaExtractor(); mMediaExtractor.setDataSource(SDCARD_PATH + "/ss.mp4"); int mVideoTrackIndex = -1; int framerate = 0; for (int i = 0; i < mMediaExtractor.getTrackCount(); i++) { MediaFormat format = mMediaExtractor.getTrackFormat(i); String mime = format.getString(MediaFormat.KEY_MIME); if (!mime.startsWith("video/")) { continue; } framerate = format.getInteger(MediaFormat.KEY_FRAME_RATE); mMediaExtractor.selectTrack(i); mMediaMuxer = new MediaMuxer(SDCARD_PATH + "/ouput.mp4", MediaMuxer.OutputFormat.MUXER_OUTPUT_MPEG_4); mVideoTrackIndex = mMediaMuxer.addTrack(format); mMediaMuxer.start(); } if (mMediaMuxer == null) { return false; } MediaCodec.BufferInfo info = new MediaCodec.BufferInfo(); info.presentationTimeUs = 0; ByteBuffer buffer = ByteBuffer.allocate(500 * 1024); int sampleSize = 0; while ((sampleSize = mMediaExtractor.readSampleData(buffer, 0)) > 0) { info.offset = 0; info.size = sampleSize; info.flags = MediaCodec.BUFFER_FLAG_SYNC_FRAME; info.presentationTimeUs += 1000 * 1000 / framerate; mMediaMuxer.writeSampleData(mVideoTrackIndex, buffer, info); mMediaExtractor.advance(); } mMediaExtractor.release(); mMediaMuxer.stop(); mMediaMuxer.release(); return true; } }
在学习了Android 音视频的基本的相关知识,并整理了相关的API之后,我们应该对基本的音视频有一定的轮廓了。
下面开始接触一个Android音视频中相当重要的一个API: MediaCodec。 通过这个API,我们能够做很多Android音视频方面的工作,下面是我们学习这个API的时候,主要的方向:
学习 MediaCodec API,完成音频 AAC 硬编、硬解
学习 MediaCodec API,完成视频 H.264 的硬编、硬解
MediaCodec类可以用于使用一些基本的多媒体编解码器(音视频编解码组件),它是Android基本的多媒体支持基础架构的一部分通常和 MediaExtractor, MediaSync, MediaMuxer, MediaCrypto, MediaDrm, Image, Surface, and AudioTrack 一起使用。
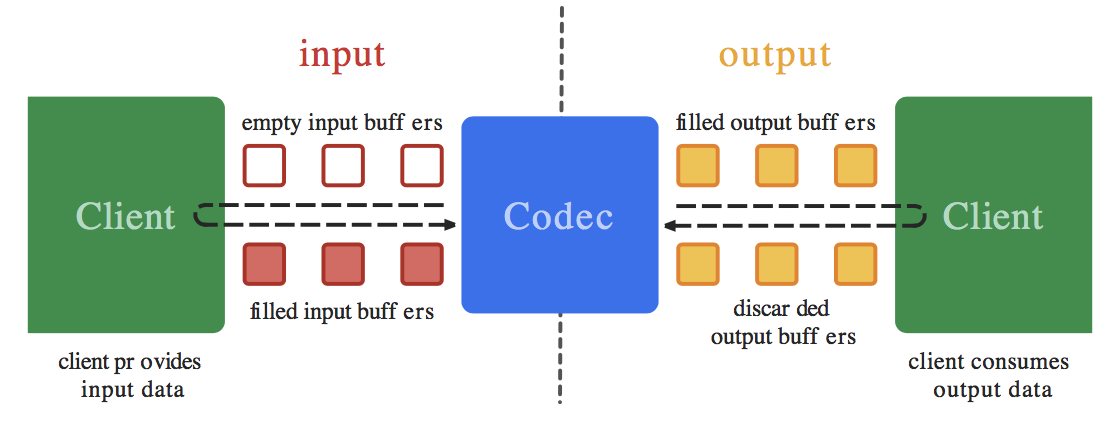
一个编解码器可以处理输入的数据来产生输出的数据,编解码器使用一组输入和输出缓冲器来异步处理数据。你可以创建一个空的输入缓冲区,填充数据后发送到编解码器进行处理。编解码器使用输入的数据进行转换,然后输出到一个空的输出缓冲区。最后你获取到输出缓冲区的数据,消耗掉里面的数据,释放回编解码器。如果后续还有数据需要继续处理,编解码器就会重复这些操作。输出流程如下:
编解码器支持的数据类型:
编解码器能处理的数据类型为: 压缩数据、原始音频数据和原始视频数据。 你可以通过ByteBuffers能够处理这三种数据,但是需要你提供一个Surface,用于对原始的视频数据进行展示,这样也能提高编解码的性能。Surface使用的是本地的视频缓冲区,这个缓冲区不映射或拷贝到ByteBuffers。这样的机制让编解码器的效率更高。通常在使用Surface的时候,无法访问原始的视频数据,但是你可以使用ImageReader访问解码后的原始视频帧。在使用ByteBuffer的模式下,您可以使用Image类和getInput/OutputImage(int)访问原始视频帧。
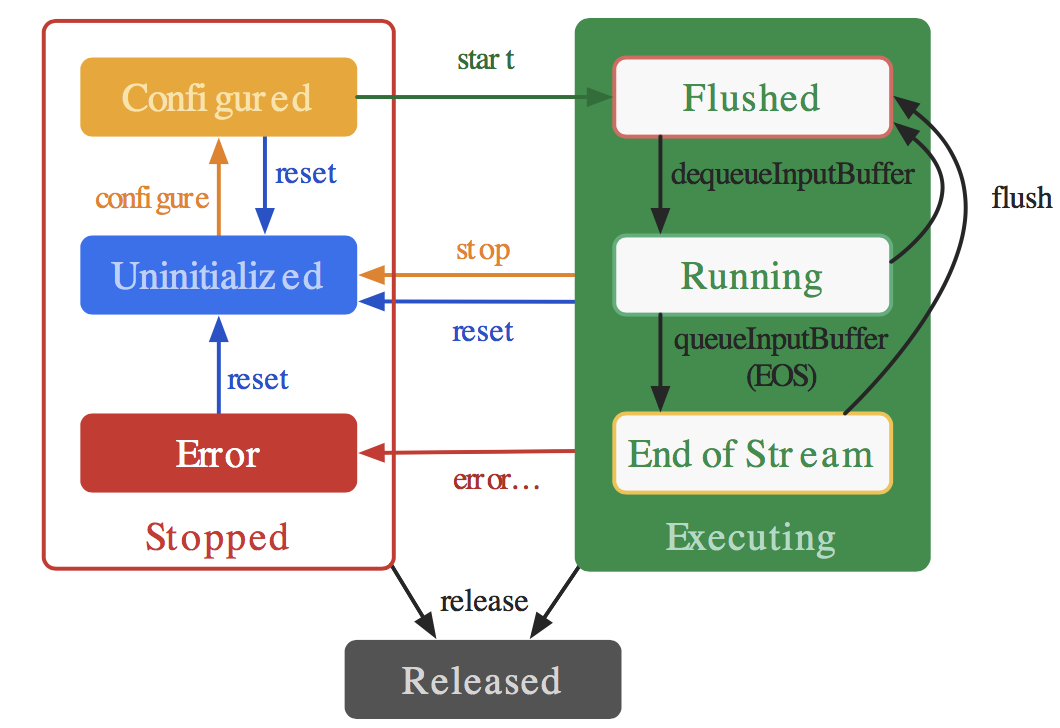
编解码器的生命周期:
主要的生命周期为:Stopped、Executing、Released。
Stopped的状态下也分为三种子状态:Uninitialized、Configured、Error。
Executing的状态下也分为三种子状态:Flushed, Running、End-of-Stream。
下图是生命周期的说明图:
如图可以看到:
当创建编解码器的时候处于未初始化状态。首先你需要调用configure(…)方法让它处于Configured状态,然后调用start()方法让其处于Executing状态。在Executing状态下,你就可以使用上面提到的缓冲区来处理数据。
Executing的状态下也分为三种子状态:Flushed, Running、End-of-Stream。在start() 调用后,编解码器处于Flushed状态,这个状态下它保存着所有的缓冲区。一旦第一个输入buffer出现了,编解码器就会自动运行到Running的状态。当带有end-of-stream标志的buffer进去后,编解码器会进入End-of-Stream状态,这种状态下编解码器不在接受输入buffer,但是仍然在产生输出的buffer。此时你可以调用flush()方法,将编解码器重置于Flushed状态。
调用stop()将编解码器返回到未初始化状态,然后可以重新配置。 完成使用编解码器后,您必须通过调用release()来释放它。
在极少数情况下,编解码器可能会遇到错误并转到错误状态。 这是使用来自排队操作的无效返回值或有时通过异常来传达的。 调用reset()使编解码器再次可用。 您可以从任何状态调用它来将编解码器移回未初始化状态。 否则,调用 release()动到终端释放状态。
MediaCodec可以处理具体的视频流,主要有这几个方法:
getInputBuffers:获取需要编码数据的输入流队列,返回的是一个ByteBuffer数组
queueInputBuffer:输入流入队列
dequeueInputBuffer:从输入流队列中取数据进行编码操作
getOutputBuffers:获取编解码之后的数据输出流队列,返回的是一个ByteBuffer数组
dequeueOutputBuffer:从输出队列中取出编码操作之后的数据
releaseOutputBuffer:处理完成,释放ByteBuffer数据
流控基本概念 流控就是流量控制。为什么要控制,因为条件有限! 涉及到了 TCP 和视频编码:
对 TCP 来说就是控制单位时间内发送数据包的数据量,对编码来说就是控制单位时间内输出数据的数据量。
TCP 的限制条件是网络带宽,流控就是在避免造成或者加剧网络拥塞的前提下,尽可能利用网络带宽。带宽够、网络好,我们就加快速度发送数据包,出现了延迟增大、丢包之后,就放慢发包的速度(因为继续高速发包,可能会加剧网络拥塞,反而发得更慢)。
视频编码的限制条件最初是解码器的能力,码率太高就会无法解码,后来随着 codec 的发展,解码能力不再是瓶颈,限制条件变成了传输带宽/文件大小,我们希望在控制数据量的前提下,画面质量尽可能高。
一般编码器都可以设置一个目标码率,但编码器的实际输出码率不会完全符合设置,因为在编码过程中实际可以控制的并不是最终输出的码率,而是编码过程中的一个量化参数(Quantization Parameter,QP),它和码率并没有固定的关系,而是取决于图像内容。
无论是要发送的 TCP 数据包,还是要编码的图像,都可能出现“尖峰”,也就是短时间内出现较大的数据量。TCP 面对尖峰,可以选择不为所动(尤其是网络已经拥塞的时候),这没有太大的问题,但如果视频编码也对尖峰不为所动,那图像质量就会大打折扣了。如果有几帧数据量特别大,但仍要把码率控制在原来的水平,那势必要损失更多的信息,因此图像失真就会更严重。
Android 硬编码流控 MediaCodec 流控相关的接口并不多,一是配置时设置目标码率和码率控制模式,二是动态调整目标码率(Android 19 版本以上)。
配置时指定目标码率和码率控制模式:
1 2 3 4 mediaFormat.setInteger(MediaFormat.KEY_BIT_RATE, bitRate); mediaFormat.setInteger(MediaFormat.KEY_BITRATE_MODE, MediaCodecInfo.EncoderCapabilities.BITRATE_MODE_VBR); mVideoCodec.configure(mediaFormat, null, null, MediaCodec.CONFIGURE_FLAG_ENCODE);
码率控制模式有三种:
CQ 表示完全不控制码率,尽最大可能保证图像质量;
CBR 表示编码器会尽量把输出码率控制为设定值,即我们前面提到的“不为所动”;
VBR 表示编码器会根据图像内容的复杂度(实际上是帧间变化量的大小)来动态调整输出码率,图像复杂则码率高,图像简单则码率低;
动态调整目标码率:
1 2 3 Bundle param = new Bundle(); param.putInt(MediaCodec.PARAMETER_KEY_VIDEO_BITRATE, bitrate); mediaCodec.setParameters(param);
Android 流控策略选择
质量要求高、不在乎带宽、解码器支持码率剧烈波动的情况下,可以选择 CQ 码率控制策略。
VBR 输出码率会在一定范围内波动,对于小幅晃动,方块效应会有所改善,但对剧烈晃动仍无能为力;连续调低码率则会导致码率急剧下降,如果无法接受这个问题,那 VBR 就不是好的选择。
CBR 的优点是稳定可控,这样对实时性的保证有帮助。所以 WebRTC 开发中一般使用的是CBR。
Android 音视频开发(七): 音视频录制流程总结 在前面我们学习和使用了AudioRecord 、AudioTrack 、Camera 、 MediaExtractor 、MediaMuxer API 、MediaCodec 。 学习和使用了上述的API之后,相信对Android系统的音视频处理有一定的经验和心得了。本文及后面的几篇文章做的事情就是将这些知识串联起来,做一些稍微复杂的事情。
流程分析 需求说明 我们需要做的事情就是:串联整个音视频录制流程,完成音视频的采集、编码、封包成 mp4 输出。
实现方式 Android音视频采集的方法:预览用SurfaceView,视频采集用Camera类,音频采集用AudioRecord。
数据处理思路 使用MediaCodec 类进行编码压缩,视频压缩为H.264,音频压缩为aac,使用MediaMuxer 将音视频合成为MP4。
实现过程 收集Camera数据,并转码为H264存储到文件 在收集数据之前,对Camera设置一些参数,方便收集后进行数据处理:
1 2 3 Camera.Parameters parameters = camera.getParameters(); parameters.setPreviewFormat(ImageFormat.NV21); parameters.setPreviewSize(1280, 720);
然后设置PreviewCallback:
1 camera.setPreviewCallback(this);
就可以获取到Camera的原始NV21数据:
1 onPreviewFrame(byte[] bytes, Camera camera)
在创建一个H264Encoder类,在里面进行编码操作,并将编码后的数据存储到文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 new Thread(new Runnable() { @Override public void run() { isRuning = true; byte[] input = null; long pts = 0; long generateIndex = 0; while (isRuning) { if (yuv420Queue.size() > 0) { input = yuv420Queue.poll(); byte[] yuv420sp = new byte[width * height * 3 / 2]; // 必须要转格式,否则录制的内容播放出来为绿屏 NV21ToNV12(input, yuv420sp, width, height); input = yuv420sp; } if (input != null) { try { ByteBuffer[] inputBuffers = mediaCodec.getInputBuffers(); ByteBuffer[] outputBuffers = mediaCodec.getOutputBuffers(); int inputBufferIndex = mediaCodec.dequeueInputBuffer(-1); if (inputBufferIndex >= 0) { pts = computePresentationTime(generateIndex); ByteBuffer inputBuffer = inputBuffers[inputBufferIndex]; inputBuffer.clear(); inputBuffer.put(input); mediaCodec.queueInputBuffer(inputBufferIndex, 0, input.length, System.currentTimeMillis(), 0); generateIndex += 1; } MediaCodec.BufferInfo bufferInfo = new MediaCodec.BufferInfo(); int outputBufferIndex = mediaCodec.dequeueOutputBuffer(bufferInfo, TIMEOUT_USEC); while (outputBufferIndex >= 0) { ByteBuffer outputBuffer = outputBuffers[outputBufferIndex]; byte[] outData = new byte[bufferInfo.size]; outputBuffer.get(outData); if (bufferInfo.flags == MediaCodec.BUFFER_FLAG_CODEC_CONFIG) { configbyte = new byte[bufferInfo.size]; configbyte = outData; } else if (bufferInfo.flags == MediaCodec.BUFFER_FLAG_SYNC_FRAME) { byte[] keyframe = new byte[bufferInfo.size + configbyte.length]; System.arraycopy(configbyte, 0, keyframe, 0, configbyte.length); System.arraycopy(outData, 0, keyframe, configbyte.length, outData.length); outputStream.write(keyframe, 0, keyframe.length); } else { outputStream.write(outData, 0, outData.length); } mediaCodec.releaseOutputBuffer(outputBufferIndex, false); outputBufferIndex = mediaCodec.dequeueOutputBuffer(bufferInfo, TIMEOUT_USEC); } } catch (Throwable t) { t.printStackTrace(); } } else { try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } } } // 停止编解码器并释放资源 try { mediaCodec.stop(); mediaCodec.release(); } catch (Exception e) { e.printStackTrace(); } // 关闭数据流 try { outputStream.flush(); outputStream.close(); } catch (IOException e) { e.printStackTrace(); } } }).start();
当结束编码的时候,需要将相关的资源释放掉:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 停止编解码器并释放资源 try { mediaCodec.stop(); mediaCodec.release(); } catch (Exception e) { e.printStackTrace(); } // 关闭数据流 try { outputStream.flush(); outputStream.close(); } catch (IOException e) { e.printStackTrace(); }
此时,我们做到了将视频内容采集–>编码–>存储文件。但这个仅仅是对Android 音视频开发(四):使用 Camera API 采集视频数据 的延伸,但是很有必要。因为在前面学习了如何采集音频,如何使用MediaCodec去处理音视频,如何使用MediaMuxer去混合音视频。
示例代码:https://github.com/renhui/AndroidRecorder/releases/tag/only_h264_video
下面我们在当前的的基础上继续完善,即将音视频采集并混合为音视频。
音视频采集+混合,存储到文件 基本完成思路已经在2.1的结尾处坐了说明,下面贴一下demo的链接:
示例代码:https://github.com/renhui/AndroidRecorder/releases/tag/h264_video_audio
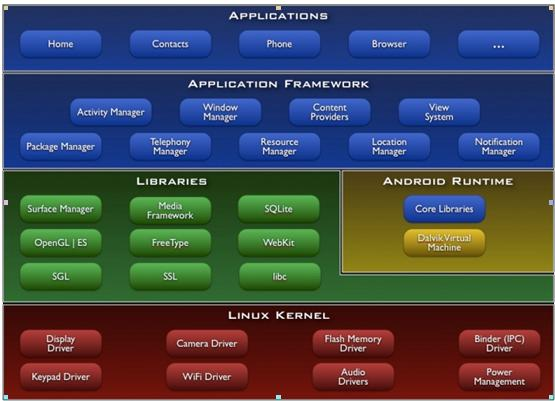
Android音视频开发中级进阶篇 OpenGL ES Android OpenGL ES 开发(一): OpenGL ES 介绍 简介OpenGL ES 谈到OpenGL ES,首先我们应该先去了解一下Android的基本架构,基本架构下图:
根据上图可以知道Android 目前是支持使用开放的图形库的,特别是通过OpenGL ES API来支持高性能的2D和3D图形。OpenGL是一个跨平台的图形API。为3D图形处理硬件指定了一个标准的软件接口。OpenGL ES 是适用于嵌入式设备的OpenGL规范。
Android 支持OpenGL ES API版本的详细状态是:
OpenGL ES 1.0 和 1.1 能够被Android 1.0及以上版本支持
OpenGL ES 2.0 能够被Android 2.2及更高版本支持
OpenGL ES 3.0 能够被Android 4.3及更高版本支持
OpenGL ES 3.1 能够被Android 5.0及以上版本支持
基本介绍 Android 能够通过framework框架提供的API或者NDK来支持OpenGL。本文重点介绍框架提供的接口来使用OpenGL的方式,有关于NDK方面的信息,可以自行去官方文档进行了解。
在Android框架里面两个基本的类允许你使用OpenGL ES API创建和操作图形: GLSurfaceView 和 GLSurfaceView.Renderer。如果您的目标是在Android程序中使用OpenGL,那么首先需要做的事情就是了解这两个类。
GLSurfaceView 这是一个视图类,你可以使用OpenGL API来绘制和操作图形对象,这一点在功能上很类似于SurfaceView。你可以通过创建一个SurfaceView的实例并添加你的渲染器来使用这个类。但是如果想要捕捉触摸屏的事件,则应该扩展GLSurfaceView以实现触摸监听器。关于实现触摸监听器的方式,我们会在后面的文章中进行讲解。
GLSurfaceView.Renderer 此接口定义了在GLSurfaceView中绘制图形所需的方法。您必须将此接口的实现作为单独的类提供,并使用GLSurfaceView.setRenderer()将其附加到您的GLSurfaceView实例。
onSurfaceCreated():创建GLSurfaceView时,系统调用一次该方法。使用此方法执行只需要执行一次的操作,例如设置OpenGL环境参数或初始化OpenGL图形对象。
onDrawFrame():系统在每次重画GLSurfaceView时调用这个方法。使用此方法作为绘制(和重新绘制)图形对象的主要执行方法。
onSurfaceChanged():当GLSurfaceView的发生变化时,系统调用此方法,这些变化包括GLSurfaceView的大小或设备屏幕方向的变化。例如:设备从纵向变为横向时,系统调用此方法。我们应该使用此方法来响应GLSurfaceView容器的改变。
Android OpenGL ES开发(二) : OpenGL ES 环境搭建 环境搭建目的 为了在Android应用程序中使用OpenGL ES绘制图形,必须要为他们创建一个视图容器。其中最直接或者最常用的方式就是实现一个GLSurfaceView和一个GLSurfaceView.Renderer。GLSurfaceView是用OpenGL绘制图形的视图容器,GLSurfaceView.Renderer控制在该视图内绘制的内容。
下面将讲解如何使用GLSurfaceView 和 GLSurfaceView.Renderer 在一个简单的应用程序的Activity上面做一个最小的实现。
在Manifest中声明OpenGL ES使用 为了让你的应用程序能够使用OpenGL ES 2.0的API,你必须添加以下声明到manifest:
1 <uses-feature android:glEsVersion ="0x00020000" android:required ="true" />
如果你的应用程序需要使用纹理压缩,你还需要声明你的应用程序需要支持哪种压缩格式,以便他们安装在兼容的设备上。
1 2 <supports-gl-texture android:name ="GL_OES_compressed_ETC1_RGB8_texture" /> <supports-gl-texture android:name ="GL_OES_compressed_paletted_texture" />
关于更多的纹理压缩格式的知识,可以到 https://developer.android.com/guide/topics/graphics/opengl.html###textures 做进一步的了解。
创建一个Activity 用于展示OpenGL ES 图形 使用OpenGL ES的应用程序的Activity和其他应用程的Activity一样,不同的地方在于你设置的Activity的布局。在许多使用OpenGL ES的app中,你可以添加TextView,Button和ListView,还可以添加GLSurfaceView。
下面的代码展示了使用GLSurfaceView做为主视图的基本实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class OpenGLES20Activity extends Activity { private GLSurfaceView mGLView; @Override public void onCreate (Bundle savedInstanceState) { super .onCreate(savedInstanceState); mGLView = new MyGLSurfaceView (this ); setContentView(mGLView); } }
注意:OpenGL ES 2.0 需要的Android版本是2.2及以上,请确保你的Android项目针对的版本是否符合。
创建GLSurfaceView对象 GLSurfaceView是一个特殊的View,通过这个View你可以绘制OpenGL图像。但是View本身没有做太多的事情,主要的绘制是通过设置在View里面的GLSurfaceView.Renderer 来控制的。实际上,创建这个对象的代码是很少的,你能会想尝试跳过extends的操作,只去创建一个没有被修改的GLSurfaceView实例,但是不建议这样去做。因为在某些情况下,你需要扩展这个类来捕获触摸的事件,捕获触摸的事件的方式会在后面的文章里面做介绍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class MyGLSurfaceView extends GLSurfaceView { private final MyGLRenderer mRenderer; public MyGLSurfaceView (Context context) { super (context); setEGLContextClientVersion(2 ); mRenderer = new MyGLRenderer (); setRenderer(mRenderer); } }
你可以通过设置GLSurfaceView.RENDERMODE_WHEN_DIRTY来让你的GLSurfaceView监听到数据变化的时候再去刷新,即修改GLSurfaceView的渲染模式。这个设置可以防止重绘GLSurfaceView,直到你调用了requestRender(),这个设置在默写层面上来说,对你的APP是更有好处的。
创建一个Renderer类 实现了GLSurfaceView.Renderer 类才是真正算是开始能够在应用中使用OpenGL ES。这个类控制着与它关联的GLSurfaceView 绘制的内容。在renderer 里面有三个方法能够被Android系统调用,以便知道在GLSurfaceView绘制什么以及如何绘制
onSurfaceCreated() - 在View的OpenGL环境被创建的时候调用。
onDrawFrame() - 每一次View的重绘都会调用
onSurfaceChanged() - 如果视图的几何形状发生变化(例如,当设备的屏幕方向改变时),则调用此方法。
下面是使用OpenGL ES 渲染器的基本实现,仅仅做的事情就是在GLSurfaceView绘制一个黑色背景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class MyGLRenderer implements GLSurfaceView .Renderer { public void onSurfaceCreated (GL10 unused, EGLConfig config) { GLES20.glClearColor(0.0f , 0.0f , 0.0f , 1.0f ); } public void onDrawFrame (GL10 unused) { GLES20.glClear(GLES20.GL_COLOR_BUFFER_BIT); } public void onSurfaceChanged (GL10 unused, int width, int height) { GLES20.glViewport(0 , 0 , width, height); } }
总结 上述的内容就是基本的OpenGL ES基本的环境配置,本文的代码仅仅是创建一个简单的Android应用然后使用OpenGL展示一个黑板。虽然没有做其他更加有趣的事情,但是,通过创建这些类,你应该已经拥有了使用OpenGL绘制图形元素的基础了。
注:你可能很好奇为什么在使用OpenGL ES 2.0的API的时候会看到GL10的参数,因为这些方法签名被简单地用于2.0 API这样可以保持Android框架代码的简单。
如果你熟悉OpenGL的API,现在你应该可以在你的APP里面创建一个OpenGL ES的环境,并开始进行画图了。但是如果需要更多的帮助来使用OpenGL,就请期待下面的文章吧。
Android OpenGL ES 开发(三):OpenGL ES定义形状 在上篇文章,我们能够配置好基本的Android OpenGL 使用的环境。但是如果我们不了解OpenGL ES如何定义图像的一些基本知识就使用OpenGL ES进行绘图还是有点棘手的。所以能够在OpenGL ES的View里面定义要绘制的形状是进行高端绘图操作的第一步。
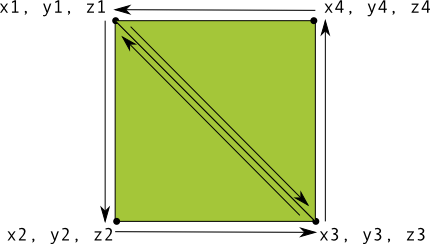
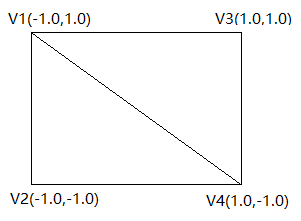
定义三角形 OpenGL ES允许你使用三维空间坐标系定义绘制的图像,所以你在绘制一个三角形之前必须要先定义它的坐标。在OpenGL中,这样做的典型方法是为坐标定义浮点数的顶点数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Triangle { private FloatBuffer vertexBuffer; static final int COORDS_PER_VERTEX = 3 ; static float triangleCoords[] = { 0.0f , 0.622008459f , 0.0f , -0.5f , -0.311004243f , 0.0f , 0.5f , -0.311004243f , 0.0f }; float color[] = { 0.63671875f , 0.76953125f , 0.22265625f , 1.0f }; public Triangle () { ByteBuffer bb = ByteBuffer.allocateDirect( triangleCoords.length * 4 ); bb.order(ByteOrder.nativeOrder()); vertexBuffer = bb.asFloatBuffer(); vertexBuffer.put(triangleCoords); vertexBuffer.position(0 ); } }
默认情况下,OpenGL ES采用坐标系,[0,0,0](X,Y,Z)指定GLSurfaceView框架的中心,[1,1,0]是框架的右上角,[ - 1,-1,0]是框架的左下角。 有关此坐标系的说明,请参阅OpenGL ES开发人员指南。
请注意,此图形的坐标以逆时针顺序定义。 绘图顺序非常重要,因为它定义了哪一面是您通常想要绘制的图形的正面,以及背面。关于这块相关的更多的内容,可以去查看一下相关的OpenGL ES 文档。
定义正方形 可以看到,在OpenGL里面定义一个三角形很简单。但是如果你想要得到一个更复杂一点的东西呢?比如一个正方形?能够找到很多办法来作到这一点,但是在OpenGL里面绘制这个图形的方式是将两个三角形画在一起。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Square { private FloatBuffer vertexBuffer; private ShortBuffer drawListBuffer; static final int COORDS_PER_VERTEX = 3 ; static float squareCoords[] = { -0.5f , 0.5f , 0.0f , -0.5f , -0.5f , 0.0f , 0.5f , -0.5f , 0.0f , 0.5f , 0.5f , 0.0f }; private short drawOrder[] = { 0 , 1 , 2 , 0 , 2 , 3 }; public Square () { ByteBuffer bb = ByteBuffer.allocateDirect( squareCoords.length * 4 ); bb.order(ByteOrder.nativeOrder()); vertexBuffer = bb.asFloatBuffer(); vertexBuffer.put(squareCoords); vertexBuffer.position(0 ); ByteBuffer dlb = ByteBuffer.allocateDirect( drawOrder.length * 2 ); dlb.order(ByteOrder.nativeOrder()); drawListBuffer = dlb.asShortBuffer(); drawListBuffer.put(drawOrder); drawListBuffer.position(0 ); } }
这个例子让你了解用OpenGL创建更复杂的形状的过程。 一般来说,您使用三角形的集合来绘制对象。下面的文章里面,将讲述如何在屏幕上绘制这些形状。
Android OpenGL ES开发(四) : OpenGL ES绘制形状 在上文中,我们使用OpenGL定义了能够被绘制出来的形状了,现在我们想绘制出来它们。使用OpenGLES 2.0来绘制形状会比你想象的需要更多的代码。因为OpenGL的API提供了大量的对渲染管线的控制能力。
本文就将讲述如何使用OpenGL ES 2.0 API来绘制出来我们上节定义的形状。
初始化形状 在你做任何绘制操作之前,你必须要初始化并加载你准备绘制的形状。除非形状的结构(指原始的坐标)在执行过程中发生改变,你都应该在你的Renderer的方法onSurfaceCreated()中进行内存和效率方面的初始化工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class MyGLRenderer implements GLSurfaceView .Renderer { ... private Triangle mTriangle; private Square mSquare; public void onSurfaceCreated (GL10 unused, EGLConfig config) { ... mTriangle = new Triangle (); mSquare = new Square (); } ... }
绘制形状 使用OpenGLES 2.0画一个定义好的形状需要比较多的代码,因为你必须为图形渲染管线提供一大堆信息。特别的,你必须定义以下几个东西:
Vertex Shader - 用于渲染形状的顶点的OpenGLES 图形代码。
Fragment Shader - 用于渲染形状的外观(颜色或纹理)的OpenGLES 代码。
Program - 一个OpenGLES对象,包含了你想要用来绘制一个或多个形状的shader。
你至少需要一个vertexshader来绘制一个形状和一个fragmentshader来为形状上色。这些形状必须被编译然后被添加到一个OpenGLES program中,program之后被用来绘制形状。下面是一个展示如何定义一个可以用来绘制形状的基本shader的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Triangle { private final String vertexShaderCode = "attribute vec4 vPosition;" + "void main() {" + " gl_Position = vPosition;" + "}" ; private final String fragmentShaderCode = "precision mediump float;" + "uniform vec4 vColor;" + "void main() {" + " gl_FragColor = vColor;" + "}" ; ... }
Shader们包含了OpenGLShading Language (GLSL)代码,必须在使用前编译。要编译这些代码,在你的Renderer类中创建一个工具类方法:
1 2 3 4 5 6 7 8 9 10 11 12 public static int loadShader (int type, String shaderCode) { int shader = GLES20.glCreateShader(type); GLES20.glShaderSource(shader, shaderCode); GLES20.glCompileShader(shader); return shader; }
为了绘制你的形状,你必须编译shader代码,添加它们到一个OpenGLES program 对象然后链接这个program。在renderer对象的构造器中做这些事情,从而只需做一次即可。
注:编译OpenGLES shader们和链接linkingprogram们是很耗CPU的,所以你应该避免多次做这些事。如果在运行时你不知道shader的内容,你应该只创建一次code然后缓存它们以避免多次创建。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Triangle () { ... private final int mProgram; public Triangle () { ... int vertexShader = MyGLRenderer.loadShader(GLES20.GL_VERTEX_SHADER, vertexShaderCode); int fragmentShader = MyGLRenderer.loadShader(GLES20.GL_FRAGMENT_SHADER, fragmentShaderCode); mProgram = GLES20.glCreateProgram(); GLES20.glAttachShader(mProgram, vertexShader); GLES20.glAttachShader(mProgram, fragmentShader); GLES20.glLinkProgram(mProgram); } }
此时,你已经准备好增加真正的绘制调用了。需要为渲染管线指定很多参数来告诉它你想画什么以及如何画。因为绘制操作因形状而异,让你的形状类包含自己的绘制逻辑是个很好主意。
创建一个draw()方法负责绘制形状。下面的代码设置位置和颜色值到形状的vertexshader和fragmentshader,然后执行绘制功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 private int mPositionHandle;private int mColorHandle;private final int vertexCount = triangleCoords.length / COORDS_PER_VERTEX;private final int vertexStride = COORDS_PER_VERTEX * 4 ; public void draw () { GLES20.glUseProgram(mProgram); mPositionHandle = GLES20.glGetAttribLocation(mProgram, "vPosition" ); GLES20.glEnableVertexAttribArray(mPositionHandle); GLES20.glVertexAttribPointer(mPositionHandle, COORDS_PER_VERTEX, GLES20.GL_FLOAT, false , vertexStride, vertexBuffer); mColorHandle = GLES20.glGetUniformLocation(mProgram, "vColor" ); GLES20.glUniform4fv(mColorHandle, 1 , color, 0 ); GLES20.glDrawArrays(GLES20.GL_TRIANGLES, 0 , vertexCount); GLES20.glDisableVertexAttribArray(mPositionHandle); }
一旦完成了所有这些代码,绘制该对象只需要在渲染器的onDrawFrame()方法中调用draw()方法:
1 2 3 4 5 public void onDrawFrame (GL10 unused) { ... mTriangle.draw(); }
当你运行程序的时候,你就应该看到以下的内容:
此例子中的代码还有很多问题。首先,它不会打动你和你的朋友。其次,三角形会在你从竖屏变为横屏时被压扁。三角形变形的原因是其顶点们没有跟据屏幕的宽高比进行修正。而且这里展示出来的三角形是静止的,这样的图形是有点无聊的,在“添加动画”的文章中,我们会使用OpenGL ES 的视图管线来旋转此形状。
Android OpenGL ES开发(五) : OpenGL ES使用投影和相机视图 OpenGL ES环境允许你以更接近于你眼睛看到的物理对象的方式来显示你绘制的对象。物理查看的模拟是通过对你所绘制的对象的坐标进行数学变换完成的:
Projection — 这个变换是基于他们所显示的GLSurfaceView的宽和高来调整绘制对象的坐标的。没有这个计算变换,通过OpenGL绘制的形状会在不同显示窗口变形。这个投影变化通常只会在OpenGL view的比例被确定或者在你渲染器的onSurfaceChanged()方法中被计算。想要了解更多的关于投影和坐标映射的相关信息,请看绘制对象的坐标映射。
Camera View — 这个换是基于虚拟的相机的位置来调整绘制对象坐标的。需要着重注意的是,OpenGL ES并没有定义一个真实的相机对象,而是提供一个实用方法,通过变换绘制对象的显示来模拟一个相机。相机视图变换可能只会在你的GLSurfaceView被确定时被计算,或者基于用户操作或你应用程序的功能来动态改变。
本课程描述怎样创建投影和相机视图并将其应用的到你的GLSurfaceView的绘制对象上。
定义投影 投影变化的数据是在你GLSurfaceView.Renderer类的onSurfaceChanged()方法中被计算的。下面的示例代码是获取GLSurfaceView的高和宽,并通过Matrix.frustumM()方法用它们填充到投影变换矩阵中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private final float [] mMVPMatrix = new float [16 ];private final float [] mProjectionMatrix = new float [16 ];private final float [] mViewMatrix = new float [16 ];@Override public void onSurfaceChanged (GL10 unused, int width, int height) { GLES20.glViewport(0 , 0 , width, height); float ratio = (float ) width / height; Matrix.frustumM(mProjectionMatrix, 0 , -ratio, ratio, -1 , 1 , 3 , 7 ); }
上面的代码填充有一个投影矩阵mProjectionMatrix,mProjectionMatrix可以在onFrameDraw()方法中与下一部分的相机视图结合在一起。
注意:如果仅仅只把投影矩阵应用的到你绘制的对象中,通常你只会得到一个非常空的显示。一般情况下,你还必须为你要在屏幕上显示的任何内容应用相机视图。
定义相机视图 通过在你的渲染器中添加相机视图变换作为你绘制过程的一部分来完成你的绘制图像的变换过程。在下面的代码中,通过Matrix.setLookAtM()方法计算相机视图变换,然后将其与之前计算出的投影矩阵结合到一起。合并后的矩阵接下来会传递给绘制的图形。
1 2 3 4 5 6 7 8 9 10 11 12 @Override public void onDrawFrame (GL10 unused) { ... Matrix.setLookAtM(mViewMatrix, 0 , 0 , 0 , -3 , 0f , 0f , 0f , 0f , 1.0f , 0.0f ); Matrix.multiplyMM(mMVPMatrix, 0 , mProjectionMatrix, 0 , mViewMatrix, 0 ); mTriangle.draw(mMVPMatrix); }
应用投影和相机变换 为了使用在上一部分内容中展示的投影和相机视图变换的合并矩阵,首先要在之前Triangle类中定义的定点着色器代码中添加一个矩阵变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Triangle { private final String vertexShaderCode = "uniform mat4 uMVPMatrix;" + "attribute vec4 vPosition;" + "void main() {" + " gl_Position = uMVPMatrix * vPosition;" + "}" ; private int mMVPMatrixHandle; ... }
下一步,修改你的图形对象的draw()方法来接收联合变换矩阵,并将它们应用到图形中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public void draw (float [] mvpMatrix) { ... mMVPMatrixHandle = GLES20.glGetUniformLocation(mProgram, "uMVPMatrix" ); GLES20.glUniformMatrix4fv(mMVPMatrixHandle, 1 , false , mvpMatrix, 0 ); GLES20.glDrawArrays(GLES20.GL_TRIANGLES, 0 , vertexCount); GLES20.glDisableVertexAttribArray(mPositionHandle); }
一旦你正确的计算并应用投影和相机视图变换,你的绘图对象将会以正确的比例绘制,它看起来应该像下面这样:
现在你已经有一个可以以正确比例显示图形的应用了。后面的章节,我们可以了解如何为你的图形添加运动了。
Android openGL ES开发(六): OpenGL ES添加运动效果 在屏幕上绘制图形只是OpenGL的相当基础的特点,你也可以用其他的Android图形框架类来实现这些,包括Canvas和Drawable对象。OpenGL ES为在三维空间中移动和变换提供了额外的功能,并提供了创建引人注目的用户体验的独特方式。
旋转一个图形 用OpenGL ES 2.0来旋转一个绘制对象是相对简单的。在你的渲染器中,添加一个新的变换矩阵(旋转矩阵),然后把它与你的投影与相机视图变换矩阵合并到一起:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private float [] mRotationMatrix = new float [16 ];public void onDrawFrame (GL10 gl) { float [] scratch = new float [16 ]; ... long time = SystemClock.uptimeMillis() % 4000L ; float angle = 0.090f * ((int ) time); Matrix.setRotateM(mRotationMatrix, 0 , angle, 0 , 0 , -1.0f ); Matrix.multiplyMM(scratch, 0 , mMVPMatrix, 0 , mRotationMatrix, 0 ); mTriangle.draw(scratch); }
如果做了这些改变后你的三角形还没有旋转,请确保你是否注释掉了GLSurfaceView.RENDERMODE_WHEN_DIRTY设置项,这将在下一部分讲到。
允许连续渲染 如果你勤恳地遵循本系列课程的示例代码到这个点,请确保你注释了设置只有当dirty的时候才渲染的渲染模式这一行,否则OpenGL旋转图形,只会递增角度然后等待来自GLSurfaceView容器的对requestRender()方法的调用:
1 2 3 4 5 6 public MyGLSurfaceView (Context context) { ... }
除非你的对象改变没有用户交互,否则通常打开这个标志是个好主意。准备好取消注释这行代码,因为下一节内容将使这个调用再次适用。
Android openGL ES开发(七) : OpenGL ES 响应触摸事件 像旋转三角形一样,通过预设程序来让对象移动对于吸引注意是很有用的,但是如果你想让你的OpenGL图形有用户交互呢?让你的OpenGL ES应用有触摸交互的关键是,扩展你的GLSurfaceView的实现重载onTouchEvent()方法来监听触摸事件。
设置触摸事件 为了你的OpenGL ES应用能够响应触摸事件,你必须在你的GLSurfaceView中实现onTouchEvent()方法,下面的实现例子展示了怎样监听MotionEvent.ACTION_MOVE事件,并将该事件转换成图形的旋转角度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 private final float TOUCH_SCALE_FACTOR = 180.0f / 320 ;private float mPreviousX;private float mPreviousY;@Override public boolean onTouchEvent (MotionEvent e) { float x = e.getX(); float y = e.getY(); switch (e.getAction()) { case MotionEvent.ACTION_MOVE: float dx = x - mPreviousX; float dy = y - mPreviousY; if (y > getHeight() / 2 ) { dx = dx * -1 ; } if (x < getWidth() / 2 ) { dy = dy * -1 ; } mRenderer.setAngle( mRenderer.getAngle() + ((dx + dy) * TOUCH_SCALE_FACTOR)); requestRender(); } mPreviousX = x; mPreviousY = y; return true ; }
需要注意的是,计算完旋转角度后,需要调用requestRender()方法来告诉渲染器是时候渲染帧画面了。在本例子中这种方法是最高效的,因为除非旋转有改变,否则帧画面不需要重绘。然而除非你还用setRenderMode()方法要求渲染器只有在数据改变时才进行重绘,否则这对性能没有任何影响。因此,确保渲染器中的下面这行是取消注释的:
1 2 3 4 5 public MyGLSurfaceView (Context context) { ... setRenderMode(GLSurfaceView.RENDERMODE_WHEN_DIRTY); }
暴露旋转角度 上面的例程代码中需要你通过在渲染器中添加共有的成员来暴露旋转角度。当渲染代码是在独立于你应用程序的主用户界面线程的单独线程执行的时候,你必须声明这个共有变量是volatile类型的。下面的代码声明了这个变量并且暴露了它的getter和setter方法对:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class MyGLRenderer implements GLSurfaceView .Renderer { ... public volatile float mAngle; public float getAngle () { return mAngle; } public void setAngle (float angle) { mAngle = angle; } }
应用旋转 为了应用触摸输入产生的旋转,先注释掉产生角度的代码,并添加一个右触摸事件产生的角度mAngle:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public void onDrawFrame (GL10 gl) { ... float [] scratch = new float [16 ]; Matrix.setRotateM(mRotationMatrix, 0 , mAngle, 0 , 0 , -1.0f ); Matrix.multiplyMM(scratch, 0 , mMVPMatrix, 0 , mRotationMatrix, 0 ); mTriangle.draw(scratch); }
当你完成上面介绍的步骤,运行你的程序,然后在屏幕上拖拽你的手指来旋转这个三角形。
Android OpenGL ES开发(八) :OpenGL ES 着色器语言GLSL 前面的文章主要是整理的Android 官方文档对OpenGL ES支持的介绍。通过之前的文章,我们基本上可以完成的基本的形状的绘制。
这是本人做的整理笔记: https://github.com/renhui/OpenGLES20Study
目前到这里第一阶段的学习,也就是基本的图形绘制,基本的交互的实现。
平面绘制:三角形、正方形、在相机视角下的三角形、彩色三角形
立体绘制:正方体、圆柱体、圆锥体、球体
基本交互:手绘点、旋转三角形
知道了基本的图形绘制,也知道了基本的交互的实现,现在可能大多数人还是对整个实现的流程有点懵,最主要的地方可能就是对顶点着色器和片元着色器了。前面的使用过程中,我们大概也对着色器语言有一定的了解了,但是在前面我们使用的着色器代码还是很简单的,做的事情也是很有限的,后面的开发过程中,我们用到的着色器会越来越复杂,So,这里我们想一下着色器语言GLSL。
我们知道,在OpenGL ES中着色器分为顶点着色器和片元着色器。顶点着色器是针对每个顶点执行一次,用于确定顶点的位置。片元着色器是针对每个片元,片元我们可以理解为每个像素,用于确定每个片元(像素)的颜色。
GLSL 简介 GLSL又叫OpenGL着色语言(OpenGL Shading Language),是用来在OpenGL中着色编程的语言,是一种面向过程的语言,基本的语法和C/C++基本相同,他们是在图形卡的GPU (Graphic Processor Unit图形处理单元)上执行的,代替了固定的渲染管线的一部分,使渲染管线中不同层次具有可编程性。比如:视图转换、投影转换等。GLSL(GL Shading Language)的着色器代码分成2个部分:Vertex Shader(顶点着色器)和Fragment(片断着色器)。
在前面的学习中,我们基本上使用的都是非常简单的着色器,基本上没有使用过GLSL的内置函数,但是在后面我们完成其他的功能的时候应该就会用到这些内置函数了。
GLSL 基础 GLSL 虽然很类似于C/C++,但是它和C/C++还是有很大的不同的,比如,没有double,long等类型,没有union、enum、unsigned以及位运算等特性。
基本数据类型 GLSL中的数据类型主要分为标量、向量、矩阵、采样器、结构体、数组、空类型七种类型:
标量: 标量表示的是只有大小没有方向的量,在GLSL中标量只有bool、int和float三种。对于int,和C一样,可以写为十进制(16)、八进制(020)或者十六进制(0x10)。对于标量的运算,我们最需要注意的是精度,防止溢出问题。
向量: 向量我们可以看做是数组,在GLSL通常用于储存颜色、坐标等数据,针对维数,可分为二维、三维和四位向量。针对存储的标量类型,可以分为bool、int和float。共有vec2、vec3、vec4,ivec2、ivec3、ivec4、bvec2、bvec3和bvec4九种类型,数组代表维数、i表示int类型、b表示bool类型。需要注意的是,GLSL中的向量表示竖向量,所以与矩阵相乘进行变换时,矩阵在前,向量在后(与DirectX正好相反)。向量在GPU中由硬件支持运算,比CPU快的多。
作为颜色向量时,用rgba表示分量,就如同取数组的中具体数据的索引值。三维颜色向量就用rgb表示分量。比如对于颜色向量vec4 color,color[0]和color.r都表示color向量的第一个值,也就是红色的分量。其他相同。
作为位置向量时,用xyzw表示分量,xyz分别表示xyz坐标,w表示向量的模。三维坐标向量为xyz表示分量,二维向量为xy表示分量。
作为纹理向量时,用stpq表示分量,三维用stp表示分量,二维用st表示分量。
矩阵: 在GLSL中矩阵拥有22、3 3、4*4三种类型的矩阵,分别用mat2、mat3、mat4表示。我们可以把矩阵看做是一个二维数组,也可以用二维数组下表的方式取里面具体位置的值。
采样器: 采样器是专门用来对纹理进行采样工作的,在GLSL中一般来说,一个采样器变量表示一副或者一套纹理贴图。所谓的纹理贴图可以理解为我们看到的物体上的皮肤。
结构体: 和C语言中的结构体相同,用struct来定义结构体,关于结构体参考C语言中的结构体。
数组: 数组知识也和C中相同,不同的是数组声明时可以不指定大小,但是建议在不必要的情况下,还是指定大小的好。
空类型: 空类型用void表示,仅用来声明不返回任何值得函数。
数据声明示例:
1 2 3 4 5 6 7 8 9 10 11 float a=1.0; int b=1; bool c=true; vec2 d=vec2(1.0,2.0); vec3 e=vec3(1.0,2.0,3.0) vec4 f=vec4(vec3,1.2); vec4 g=vec4(0.2); //相当于vec(0.2,0.2,0.2,0.2) vec4 h=vec4(a,a,1.3,a); mat2 i=mat2(0.1,0.5,1.2,2.4); mat2 j=mat2(0.8); //相当于mat2(0.8,0.8,0.8,0.8) mat3 k=mat3(e,e,1.2,1.6,1.8);
运算符 GLSL中的运算符有(越靠前,运算优先级越高):
索引:[]
前缀自加和自减:++,–
一元非和逻辑非:~,!
加法和减法:+,-
等于和不等于:==,!=
逻辑异或:^^
三元运算符号,选择:?:
成员选择与混合:.
后缀自加和自减:++,–
乘法和除法:*,/
关系运算符:>,<,=,>=,<=,<>
逻辑与:&&
逻辑或:||
赋值预算:=,+=,-=,*=,/=
类型转换 GLSL的类型转换与C不同。在GLSL中类型不可以自动提升,比如float a=1;就是一种错误的写法,必须严格的写成float a=1.0,也不可以强制转换,即float a=(float)1;也是错误的写法,但是可以用内置函数来进行转换,如float a=float(1);还有float a=float(true);(true为1.0,false为0.0)等,值得注意的是,低精度的int不能转换为低精度的float。
限定符 在之前的博客中也提到了,GLSL中的限定符号主要有:
attritude:一般用于各个顶点各不相同的量。如顶点颜色、坐标等。
uniform:一般用于对于3D物体中所有顶点都相同的量。比如光源位置,统一变换矩阵等。
varying:表示易变量,一般用于顶点着色器传递到片元着色器的量。
const:常量。
流程控制 GLSL中的流程控制与C中基本相同,主要有:
if(){}、if(){}else{}、if(){}else if(){}else{}
while(){}和do{}while()
for(;😉{}
break和continue
函数 GLSL中也可以定义函数,定义函数的方式也与C语言基本相同。函数的返回值可以是GLSL中的除了采样器的任意类型。对于GLSL中函数的参数,可以用参数用途修饰符来进行修饰,常用修饰符如下:
in:输入参数,无修饰符时默认为此修饰符。
out:输出参数。
inout:既可以作为输入参数,又可以作为输出参数。
浮点精度 与顶点着色器不同的是,在片元着色器中使用浮点型时,必须指定浮点类型的精度,否则编译会报错。精度有三种,分别为:
lowp:低精度。8位。
mediump:中精度。10位。
highp:高精度。16位。
不仅仅是float可以制定精度,其他(除了bool相关)类型也同样可以,但是int、采样器类型并不一定要求指定精度。加精度的定义如下:
1 2 uniform lowp float a=1.0; varying mediump vec4 c;
当然,也可以在片元着色器中设置默认精度,只需要在片元着色器最上面加上precision <精度> <类型>即可制定某种类型的默认精度。其他情况相同的话,精度越高,画质越好,使用的资源也越多。
程序结构 前面几篇博客都有使用到着色器,我们对着色器的程序结构也应该有一定的了解。也许一直沉浸在Android应用开发,没有了解C开发的朋友,对这种结构并不熟悉。GLSL程序的结构和C语言差不多,main()方法表示入口函数,可以在其上定义函数和变量,在main中可以引用这些变量和函数。定义在函数体以外的叫做全局变量,定义在函数体内的叫做局部变量。与高级语言不通的是,变量和函数在使用前必须声明,不能再使用的后面声明变量或者函数。
GLSL 内建变量 在着色器中我们一般都会声明变量来在程序中使用,但是着色器中还有一些特殊的变量,不声明也可以使用。这些变量叫做内建变量。內建变量,相当于着色器硬件的输入和输出点,使用者利用这些输入点输入之后,就会看到屏幕上的输出。通过输出点可以知道输出的某些数据内容。当然,实际上肯定不会这样简单,这么说只是为了帮助理解。在顶点着色器中的内建变量和片元着色器的内建变量是不相同的。着色器中的内建变量有很多,在此,我们只列出最常用的集中内建变量。
顶点着色器的内建变量 输入变量:
gl_Position:顶点坐标
gl_PointSize:点的大小,没有赋值则为默认值1,通常设置绘图为点绘制才有意义。\
片元着色器的内建变量 输入变量:
gl_FragCoord:当前片元相对窗口位置所处的坐标。
gl_FragFacing:bool型,表示是否为属于光栅化生成此片元的对应图元的正面。
gl_FragColor:当前片元颜色
gl_FragData:vec4类型的数组。向其写入的信息,供渲染管线的后继过程使用。
常用内置函数 常见函数
radians(x):角度转弧度
degrees(x):弧度转角度
sin(x):正弦函数,传入值为弧度。相同的还有cos余弦函数、tan正切函数、asin反正弦、acos反余弦、atan反正切
pow(x,y):xy
exp(x):ex
exp2(x):2x
log(x):logex
log2(x):log2x
sqrt(x):x√
inversesqr(x):1x√
abs(x):取x的绝对值
sign(x):x>0返回1.0,x<0返回-1.0,否则返回0.0
ceil(x):返回大于或者等于x的整数
floor(x):返回小于或者等于x的整数
fract(x):返回x-floor(x)的值
mod(x,y):取模(求余)
min(x,y):获取xy中小的那个
max(x,y):获取xy中大的那个
mix(x,y,a):返回x∗(1−a)+y∗a
step(x,a):x< a返回0.0,否则返回1.0
smoothstep(x,y,a):a < x返回0.0,a>y返回1.0,否则返回0.0-1.0之间平滑的Hermite插值。
dFdx(p):p在x方向上的偏导数
dFdy(p):p在y方向上的偏导数
fwidth(p):p在x和y方向上的偏导数的绝对值之和
几何函数
length(x):计算向量x的长度
distance(x,y):返回向量xy之间的距离
dot(x,y):返回向量xy的点积
cross(x,y):返回向量xy的差积
normalize(x):返回与x向量方向相同,长度为1的向量
矩阵函数
matrixCompMult(x,y):将矩阵相乘
lessThan(x,y):返回向量xy的各个分量执行x< y的结果,类似的有greaterThan,equal,notEqual
lessThanEqual(x,y):返回向量xy的各个分量执行x<= y的结果,类似的有类似的有greaterThanEqual
any(bvec x):x有一个元素为true,则为true
all(bvec x):x所有元素为true,则返回true,否则返回false
not(bvec x):x所有分量执行逻辑非运算
纹理采样函数 纹理采样函数有texture2D、texture2DProj、texture2DLod、texture2DProjLod、textureCube、textureCubeLod及texture3D、texture3DProj、texture3DLod、texture3DProjLod等。
texture表示纹理采样,2D表示对2D纹理采样,3D表示对3D纹理采样
Lod后缀,只适用于顶点着色器采样
Proj表示纹理坐标st会除以q
纹理采样函数中,3D在OpenGLES2.0并不是绝对支持。我们再次暂时不管3D纹理采样函数。重点只对texture2D函数进行说明。texture2D拥有三个参数,第一个参数表示纹理采样器。第二个参数表示纹理坐标,可以是二维、三维、或者四维。第三个参数加入后只能在片元着色器中调用,且只对采样器为mipmap类型纹理时有效。
Android OpenGL ES开发(九): OpenGL ES纹理贴图 概念 一般说来,纹理是表示物体表面的一幅或几幅二维图形,也称纹理贴图(texture)。当把纹理按照特定的方式映射到物体表面上的时候,能使物体看上去更加真实。当前流行的图形系统中,纹理绘制已经成为一种必不可少的渲染方法。在理解纹理映射时,可以将纹理看做应用在物体表面的像素颜色。在真实世界中,纹理表示一个对象的颜色、图案以及触觉特征。纹理只表示对象表面的彩色图案,它不能改变对象的几何形式。更进一步的说,它只是一种高强度的计算行为。
原理 首先介绍一下纹理映射时的坐标系,纹理映射的坐标系和顶点着色器的坐标系是不一样的。
顶点着色器的坐标系如下:
将纹理映射到右边的两个三角形上(也就是一个矩形),需要将纹理坐标指定到正确的顶点上,才能使纹理正确的显示,否则显示出来的纹理会无法显示,或者出现旋转、翻转、错位等情况。
显示纹理图片 我们可以根据以下步骤利用OpenGL ES显示一张图片:
修改着色器 首先,我们需要修改我们的着色器,将顶点着色器修改为:
1 2 3 4 5 6 7 8 9 10 attribute vec4 vPosition; attribute vec2 vCoordinate; uniform mat4 vMatrix; varying vec2 aCoordinate; void main () { gl_Position=vMatrix*vPosition; aCoordinate=vCoordinate; }
可以看到,顶点着色器中增加了一个vec2变量,并将这个变量传递给了片元着色器,这个变量就是纹理坐标。接着我们修改片元着色器为:
1 2 3 4 5 6 7 8 precision mediump float ; uniform sampler2D vTexture; varying vec2 aCoordinate; void main () { gl_FragColor=texture2D(vTexture,aCoordinate); }
片元着色器中,增加了一个sampler2D的变量,sampler2D我们在前一篇博客GLSL语言基础中提到过,是GLSL的变量类型之一的取样器。texture2D也有提到,它是GLSL的内置函数,用于2D纹理取样,根据纹理取样器和纹理坐标,可以得到当前纹理取样得到的像素颜色。
设置顶点坐标和纹理坐标 根据纹理映射原理中的介绍,我们将顶点坐标设置为:
1 2 3 4 5 6 private final float [] sPos={ -1.0f ,1.0f , -1.0f ,-1.0f , 1.0f ,1.0f , 1.0f ,-1.0f };
相应的,对照顶点坐标,我们可以设置纹理坐标为:
1 2 3 4 5 6 private final float [] sCoord={ 0.0f ,0.0f , 0.0f ,1.0f , 1.0f ,0.0f , 1.0f ,1.0f , };
计算变换矩阵 按照上步设置顶点坐标和纹理坐标,大多数情况下我们得到的一定是一张拉升或者压缩的图片。为了让图片完整的显示,且不被拉伸和压缩,我们需要向绘制等腰直角三角形一样,计算一个合适的变换矩阵,传入顶点着色器,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Override public void onSurfaceChanged (GL10 gl, int width, int height) { GLES20.glViewport(0 ,0 ,width,height); int w=mBitmap.getWidth(); int h=mBitmap.getHeight(); float sWH=w/(float )h; float sWidthHeight=width/(float )height; if (width>height){ if (sWH>sWidthHeight){ Matrix.orthoM(mProjectMatrix, 0 , -sWidthHeight*sWH,sWidthHeight*sWH, -1 ,1 , 3 , 7 ); }else { Matrix.orthoM(mProjectMatrix, 0 , -sWidthHeight/sWH,sWidthHeight/sWH, -1 ,1 , 3 , 7 ); } }else { if (sWH>sWidthHeight){ Matrix.orthoM(mProjectMatrix, 0 , -1 , 1 , -1 /sWidthHeight*sWH, 1 /sWidthHeight*sWH,3 , 7 ); }else { Matrix.orthoM(mProjectMatrix, 0 , -1 , 1 , -sWH/sWidthHeight, sWH/sWidthHeight,3 , 7 ); } } Matrix.setLookAtM(mViewMatrix, 0 , 0 , 0 , 7.0f , 0f , 0f , 0f , 0f , 1.0f , 0.0f ); Matrix.multiplyMM(mMVPMatrix,0 ,mProjectMatrix,0 ,mViewMatrix,0 ); }
mMVPMatrix即为我们所需要的变换矩阵。
显示图片 然后我们需要做的,就和之前绘制正方形一样容易了。和之前不同的是,在绘制之前,我们还需要将纹理和纹理坐标传入着色器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @Override public void onDrawFrame (GL10 gl) { GLES20.glClear(GLES20.GL_COLOR_BUFFER_BIT|GLES20.GL_DEPTH_BUFFER_BIT); GLES20.glUseProgram(mProgram); onDrawSet(); GLES20.glUniformMatrix4fv(glHMatrix,1 ,false ,mMVPMatrix,0 ); GLES20.glEnableVertexAttribArray(glHPosition); GLES20.glEnableVertexAttribArray(glHCoordinate); GLES20.glUniform1i(glHTexture, 0 ); textureId=createTexture(); GLES20.glVertexAttribPointer(glHPosition,2 ,GLES20.GL_FLOAT,false ,0 ,bPos); GLES20.glVertexAttribPointer(glHCoordinate,2 ,GLES20.GL_FLOAT,false ,0 ,bCoord); GLES20.glDrawArrays(GLES20.GL_TRIANGLE_STRIP,0 ,4 ); } public abstract void onDrawSet () ;public abstract void onDrawCreatedSet (int mProgram) ;private int createTexture () { int [] texture=new int [1 ]; if (mBitmap!=null &&!mBitmap.isRecycled()){ GLES20.glGenTextures(1 ,texture,0 ); GLES20.glBindTexture(GLES20.GL_TEXTURE_2D,texture[0 ]); GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MIN_FILTER,GLES20.GL_NEAREST); GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D,GLES20.GL_TEXTURE_MAG_FILTER,GLES20.GL_LINEAR); GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_S,GLES20.GL_CLAMP_TO_EDGE); GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_T,GLES20.GL_CLAMP_TO_EDGE); GLUtils.texImage2D(GLES20.GL_TEXTURE_2D, 0 , mBitmap, 0 ); return texture[0 ]; } return 0 ; }
这样我们就可以显示出我们需要显示的图片,并且保证它完整的居中显示而且不会变形了。
Android OpenGL ES 开发(十):通过GLES20与着色器交互 获取着色器程序内成员变量的id(句柄、指针) GLES20.glGetAttribLocation方法:获取着色器程序中,指定为attribute类型变量的id。
如:
1 2 3 4 maPositionHandle = GLES20.glGetAttribLocation(mProgram, "aPosition" ); muMVPMatrixHandle = GLES20.glGetUniformLocation(mProgram, "uMVPMatrix" );
向着色器传递数据 使用上一节获取的指向着色器相应数据成员的各个id,就能将我们自己定义的顶点数据、颜色数据等等各种数据传递到着色器当中了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 GLES20.glUseProgram(mProgram); GLES20.glUniformMatrix4fv(muMVPMatrixHandle, 1 , false , MatrixState.getFinalMatrix(), 0 ); mRectBuffer.position(0 ); GLES20.glVertexAttribPointer(maPositionHandle, 3 , GLES20.GL_FLOAT, false , 20 , mRectBuffer); GLES20.glVertexAttribPointer(maColorHandle, 4 , GLES20.GL_FLOAT, false , 4 *4 , mColorBuffer); GLES20.glVertexAttribPointer(maTextureHandle, 2 , GLES20.GL_FLOAT, false , 20 , mRectBuffer); GLES20.glEnableVertexAttribArray(maPositionHandle); GLES20.glDisableVertexAttribArray(maColorHandle); GLES20.glEnableVertexAttribArray(maTextureHandle); GLES20.glActiveTexture(GLES20.GL_TEXTURE0); GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, texture); GLES20.glDrawArrays(GLES20.GL_TRIANGLE_FAN, 0 , 4 );
定义顶点属性数组 1 void glVertexAttribPointer (int index, int size, int type, boolean normalized, int stride, Buffer ptr )
参数含义:-1,1 ,或者区间[0,1](无符号整数),反之,这些值会被直接转换为浮点值而不进行归一化处理;
启用或者禁用顶点属性数组 调用GLES20.glEnableVertexAttribArray和GLES20.glDisableVertexAttribArray传入参数index。
1 2 GLES20.glEnableVertexAttribArray(glHPosition); GLES20.glEnableVertexAttribArray(glHCoordinate);
如果启用,那么当GLES20.glDrawArrays或者GLES20.glDrawElements被调用时,顶点属性数组会被使用。
选择活动纹理单元。 1 void glActiveTexture (int texture)
texture指定哪一个纹理单元被置为活动状态。texture必须是GL_TEXTUREi之一,其中0 <= i < GL_MAX_COMBINED_TEXTURE_IMAGE_UNITS,初始值为GL_TEXTURE0。
OpenSL ES Android OpenSL ES 开发:Android OpenSL 介绍和开发流程说明 Android OpenSL ES 介绍 OpenSL ES (Open Sound Library for Embedded Systems)是无授权费、跨平台、针对嵌入式系统精心优化的硬件音频加速API。它为嵌入式移动多媒体设备上的本地应用程序开发者提供标准化, 高性能,低响应时间的音频功能实现方法,并实现软/硬件音频性能的直接跨平台部署,降低执行难度,促进高级音频市场的发展。简单来说OpenSL ES是一个嵌入式跨平台免费的音频处理库。
Android的OpenSL ES库是在NDK的platforms文件夹对应android平台先相应cpu类型里面,如:
Android OpenSL ES 开发流程 OpenSL ES 的开发流程主要有如下6个步骤:
1、 创建接口对象
2、设置混音器
3、创建播放器(录音器)
4、设置缓冲队列和回调函数
5、设置播放状态
6、启动回调函数
注明:其中第4步和第6步是OpenSL ES 播放PCM等数据格式的音频是需要用到的。
在使用OpenSL ES的API之前,需要引入OpenSL ES的头文件,代码如下:
1 2 #include <SLES/OpenSLES.h> #include <SLES/OpenSLES_Android.h>
由于是在Native层使用该特性,所需需要在Android.mk中增加链接选项,以便在链接阶段使用到系统系统的OpenSL ES的so库:
1 LOCAL_LDLIBS += -lOepnSLES
我们知道OpenSL ES提供的是基于C语言的API,但是它是基于对象和接口的方式提供的,会采用面向对象的思想开发API。因此我们先来了解一下OpenSL ES中对象和接口的概念:
对象:对象是对一组资源及其状态的抽象,每个对象都有一个在其创建时指定的类型,类型决定了对象可以执行的任务集,对象有点类似于C++中类的概念。
接口:接口是对象提供的一组特征的抽象,这些抽象会为开发者提供一组方法以及每个接口的类型功能,在代码中,接口的类型由接口ID来标识。
需要重点理解的是,一个对象在代码中其实是没有实际的表示形式的,可以通过接口来改变对象的状态以及使用对象提供的功能。对象有可以有一个或者多个接口的实例,但是接口实例肯定只属于一个对象。
如果明白了OpenSL ES 中对象和接口的概念,那么下面我们就继续看看,在代码中是如何使用它们的。
上面我们也提到过,对象是没有实际的代码表示形式的,对象的创建也是通过接口来完成的。通过获取对象的方法来获取出对象,进而可以访问对象的其他的接口方法或者改变对象的状态,下面是使用对象和接口的相关说明。
OpenSL ES 开发最重要的接口类 SLObjectItf 通过SLObjectItf接口类我们可以创建所需要的各种类型的类接口,比如:
创建引擎接口对象:SLObjectItf engineObject
创建混音器接口对象:SLObjectItf outputMixObject
创建播放器接口对象:SLObjectItf playerObject
以上等等都是通过SLObjectItf来创建的。
SLObjectItf 创建的具体的接口对象实例 OpenSL ES中也有具体的接口类,比如(引擎:SLEngineItf,播放器:SLPlayItf,声音控制器:SLVolumeItf等等)。
创建引擎并实现 OpenSL ES中开始的第一步都是声明SLObjectItf接口类型的引擎接口对象engineObject,然后用方法slCreateEngine创建一个引擎接口对象;创建好引擎接口对象后,需要用SLObjectItf的Realize方法来实现engineObject;最后用SLObjectItf的GetInterface方法来初始化SLEngnineItf对象实例。如:
1 2 3 4 5 6 7 8 9 10 SLObjectItf engineObject = NULL;//用SLObjectItf声明引擎接口对象 SLEngineItf engineEngine = NULL;//声明具体的引擎对象实例 void createEngine() { SLresult result;//返回结果 result = slCreateEngine(&engineObject, 0, NULL, 0, NULL, NULL);//第一步创建引擎 result = (*engineObject)->Realize(engineObject, SL_BOOLEAN_FALSE);//实现(Realize)engineObject接口对象 result = (*engineObject)->GetInterface(engineObject, SL_IID_ENGINE, &engineEngine);//通过engineObject的GetInterface方法初始化engineEngine }
利用引擎对象创建其他接口对象 其他接口对象(SLObjectItf outputMixObject,SLObjectItf playerObject)等都是用引擎接口对象创建的(具体的接口对象需要的参数这里就说了,可参照ndk例子里面的),如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 //混音器 SLObjectItf outputMixObject = NULL;//用SLObjectItf创建混音器接口对象 SLEnvironmentalReverbItf outputMixEnvironmentalReverb = NULL;////创建具体的混音器对象实例 result = (*engineEngine)->CreateOutputMix(engineEngine, &outputMixObject, 1, mids, mreq);//利用引擎接口对象创建混音器接口对象 result = (*outputMixObject)->Realize(outputMixObject, SL_BOOLEAN_FALSE);//实现(Realize)混音器接口对象 result = (*outputMixObject)->GetInterface(outputMixObject, SL_IID_ENVIRONMENTALREVERB, &outputMixEnvironmentalReverb);//利用混音器接口对象初始化具体混音器实例 //播放器 SLObjectItf playerObject = NULL;//用SLObjectItf创建播放器接口对象 SLPlayItf playerPlay = NULL;//创建具体的播放器对象实例 result = (*engineEngine)->CreateAudioPlayer(engineEngine, &playerObject, &audioSrc, &audioSnk, 3, ids, req);//利用引擎接口对象创建播放器接口对象 result = (*playerObject)->Realize(playerObject, SL_BOOLEAN_FALSE);//实现(Realize)播放器接口对象 result = (*playerObject)->GetInterface(playerObject, SL_IID_PLAY, &playerPlay);//初始化具体的播放器对象实例
最后就是使用创建好的具体对象实例来实现具体的功能。
OpenSL ES 使用示例 首先导入OpenSL ES和其他必须的库:
播放assets文件 创建引擎——>创建混音器——>创建播放器——>设置播放状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 JNIEXPORT void JNICALL Java_com_renhui_openslaudio_MainActivity_playAudioByOpenSL_1assets(JNIEnv *env, jobject instance, jobject assetManager, jstring filename) { release(); const char *utf8 = (*env)->GetStringUTFChars(env, filename, NULL); // use asset manager to open asset by filename AAssetManager* mgr = AAssetManager_fromJava(env, assetManager); AAsset* asset = AAssetManager_open(mgr, utf8, AASSET_MODE_UNKNOWN); (*env)->ReleaseStringUTFChars(env, filename, utf8); // open asset as file descriptor off_t start, length; int fd = AAsset_openFileDescriptor(asset, &start, &length); AAsset_close(asset); SLresult result; //第一步,创建引擎 createEngine(); //第二步,创建混音器 const SLInterfaceID mids[1] = {SL_IID_ENVIRONMENTALREVERB}; const SLboolean mreq[1] = {SL_BOOLEAN_FALSE}; result = (*engineEngine)->CreateOutputMix(engineEngine, &outputMixObject, 1, mids, mreq); (void)result; result = (*outputMixObject)->Realize(outputMixObject, SL_BOOLEAN_FALSE); (void)result; result = (*outputMixObject)->GetInterface(outputMixObject, SL_IID_ENVIRONMENTALREVERB, &outputMixEnvironmentalReverb); if (SL_RESULT_SUCCESS == result) { result = (*outputMixEnvironmentalReverb)->SetEnvironmentalReverbProperties(outputMixEnvironmentalReverb, &reverbSettings); (void)result; } //第三步,设置播放器参数和创建播放器 // 1、 配置 audio source SLDataLocator_AndroidFD loc_fd = {SL_DATALOCATOR_ANDROIDFD, fd, start, length}; SLDataFormat_MIME format_mime = {SL_DATAFORMAT_MIME, NULL, SL_CONTAINERTYPE_UNSPECIFIED}; SLDataSource audioSrc = {&loc_fd, &format_mime}; // 2、 配置 audio sink SLDataLocator_OutputMix loc_outmix = {SL_DATALOCATOR_OUTPUTMIX, outputMixObject}; SLDataSink audioSnk = {&loc_outmix, NULL}; // 创建播放器 const SLInterfaceID ids[3] = {SL_IID_SEEK, SL_IID_MUTESOLO, SL_IID_VOLUME}; const SLboolean req[3] = {SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE}; result = (*engineEngine)->CreateAudioPlayer(engineEngine, &fdPlayerObject, &audioSrc, &audioSnk, 3, ids, req); (void)result; // 实现播放器 result = (*fdPlayerObject)->Realize(fdPlayerObject, SL_BOOLEAN_FALSE); (void)result; // 得到播放器接口 result = (*fdPlayerObject)->GetInterface(fdPlayerObject, SL_IID_PLAY, &fdPlayerPlay); (void)result; // 得到声音控制接口 result = (*fdPlayerObject)->GetInterface(fdPlayerObject, SL_IID_VOLUME, &fdPlayerVolume); (void)result; //第四步,设置播放状态 if (NULL != fdPlayerPlay) { result = (*fdPlayerPlay)->SetPlayState(fdPlayerPlay, SL_PLAYSTATE_PLAYING); (void)result; } //设置播放音量 (100 * -50:静音 ) (*fdPlayerVolume)->SetVolumeLevel(fdPlayerVolume, 20 * -50); }
播放pcm文件 (集成到ffmpeg时,也是播放ffmpeg转换成的pcm格式的数据),这里为了模拟是直接读取的pcm格式的音频文件。
创建播放器和混音器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 //第一步,创建引擎 createEngine(); //第二步,创建混音器 const SLInterfaceID mids[1] = {SL_IID_ENVIRONMENTALREVERB}; const SLboolean mreq[1] = {SL_BOOLEAN_FALSE}; result = (*engineEngine)->CreateOutputMix(engineEngine, &outputMixObject, 1, mids, mreq); (void)result; result = (*outputMixObject)->Realize(outputMixObject, SL_BOOLEAN_FALSE); (void)result; result = (*outputMixObject)->GetInterface(outputMixObject, SL_IID_ENVIRONMENTALREVERB, &outputMixEnvironmentalReverb); if (SL_RESULT_SUCCESS == result) { result = (*outputMixEnvironmentalReverb)->SetEnvironmentalReverbProperties( outputMixEnvironmentalReverb, &reverbSettings); (void)result; } SLDataLocator_OutputMix outputMix = {SL_DATALOCATOR_OUTPUTMIX, outputMixObject}; SLDataSink audioSnk = {&outputMix, NULL};
设置pcm格式的频率位数等信息并创建播放器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 // 第三步,配置PCM格式信息 SLDataLocator_AndroidSimpleBufferQueue android_queue={SL_DATALOCATOR_ANDROIDSIMPLEBUFFERQUEUE,2}; SLDataFormat_PCM pcm={ SL_DATAFORMAT_PCM,//播放pcm格式的数据 2,//2个声道(立体声) SL_SAMPLINGRATE_44_1,//44100hz的频率 SL_PCMSAMPLEFORMAT_FIXED_16,//位数 16位 SL_PCMSAMPLEFORMAT_FIXED_16,//和位数一致就行 SL_SPEAKER_FRONT_LEFT | SL_SPEAKER_FRONT_RIGHT,//立体声(前左前右) SL_BYTEORDER_LITTLEENDIAN//结束标志 }; SLDataSource slDataSource = {&android_queue, &pcm}; const SLInterfaceID ids[3] = {SL_IID_BUFFERQUEUE, SL_IID_EFFECTSEND, SL_IID_VOLUME}; const SLboolean req[3] = {SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE}; result = (*engineEngine)->CreateAudioPlayer(engineEngine, &pcmPlayerObject, &slDataSource, &audioSnk, 3, ids, req); //初始化播放器 (*pcmPlayerObject)->Realize(pcmPlayerObject, SL_BOOLEAN_FALSE); // 得到接口后调用 获取Player接口 (*pcmPlayerObject)->GetInterface(pcmPlayerObject, SL_IID_PLAY, &pcmPlayerPlay);
设置缓冲队列和回调函数 1 2 3 4 // 注册回调缓冲区 获取缓冲队列接口 (*pcmPlayerObject)->GetInterface(pcmPlayerObject, SL_IID_BUFFERQUEUE, &pcmBufferQueue); //缓冲接口回调 (*pcmBufferQueue)->RegisterCallback(pcmBufferQueue, pcmBufferCallBack, NULL);
回调函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 void * pcmBufferCallBack(SLAndroidBufferQueueItf bf, void * context) { //assert(NULL == context); getPcmData(&buffer); // for streaming playback, replace this test by logic to find and fill the next buffer if (NULL != buffer) { SLresult result; // enqueue another buffer result = (*pcmBufferQueue)->Enqueue(pcmBufferQueue, buffer, 44100 * 2 * 2); // the most likely other result is SL_RESULT_BUFFER_INSUFFICIENT, // which for this code example would indicate a programming error } }
读取pcm格式的文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void getPcmData(void **pcm) { while(!feof(pcmFile)) { fread(out_buffer, 44100 * 2 * 2, 1, pcmFile); if(out_buffer == NULL) { LOGI("%s", "read end"); break; } else{ LOGI("%s", "reading"); } *pcm = out_buffer; break; } }
设置播放状态并手动开始调用回调函数 1 2 3 4 5 // 获取播放状态接口 (*pcmPlayerPlay)->SetPlayState(pcmPlayerPlay, SL_PLAYSTATE_PLAYING); // 主动调用回调函数开始工作 pcmBufferCallBack(pcmBufferQueue, NULL);
注意:
在回调函数中result = (pcmBufferQueue)->Enqueue(pcmBufferQueue, buffer, 44100 * 2 * 2),最后的“44100 22”是buffer的大小,因为我这里是指定了没读取一次就从pcm文件中读取了“44100 2*2”个字节,所以可以正常播放,如果是利用ffmpeg来获取pcm数据源,那么实际大小要根据每个AVframe的具体大小来定,这样才能正常播放出声音!(44100 * 2 * 2 表示:44100是频率HZ,2是立体声双通道,2是采用的16位采样即2个字节,所以总的字节数就是:44100 * 2 * 2)
Android OpenSL ES 开发:使用 OpenSL 播放 PCM 数据 OpenSL ES 是基于NDK也就是c语言的底层开发音频的公开API,通过使用它能够做到标准化, 高性能,低响应时间的音频功能实现方法。
这次是使用OpenSL ES来做一个音乐播放器,它能够播放m4a、mp3文件,并能够暂停和调整音量。
播放音乐需要做一些步骤:
创建声音引擎 首先创建声音引擎的对象接口
1 result = slCreateEngine(&engineObject, 0, NULL, 0, NULL, NULL);
然后实现它
1 result = (*engineObject)->Realize(engineObject, SL_BOOLEAN_FALSE);
从声音引擎的对象中抓取声音引擎
1 result = (*engineObject)->GetInterface(engineObject, SL_IID_ENGINE, &engineEngine);
创建”输出混音器”
1 result = (*engineEngine)->CreateOutputMix(engineEngine, &outputMixObject, 1, ids, req);
实现输出混合音
1 result = (*outputMixObject)->Realize(outputMixObject, SL_BOOLEAN_FALSE);
创建声音播放器 创建和实现播放器
1 2 3 4 5 6 7 8 9 // realize the player result = (*bqPlayerObject)->Realize(bqPlayerObject, SL_BOOLEAN_FALSE); assert(SL_RESULT_SUCCESS == result); (void)result; // get the play interface result = (*bqPlayerObject)->GetInterface(bqPlayerObject, SL_IID_PLAY, &bqPlayerPlay); assert(SL_RESULT_SUCCESS == result); (void)result;
设置播放缓冲 数据格式配置
1 2 3 SLDataFormat_PCM format_pcm = {SL_DATAFORMAT_PCM, 1, SL_SAMPLINGRATE_8, SL_PCMSAMPLEFORMAT_FIXED_16, SL_PCMSAMPLEFORMAT_FIXED_16, SL_SPEAKER_FRONT_CENTER, SL_BYTEORDER_LITTLEENDIAN};
数据定位器 就是定位要播放声音数据的存放位置,分为4种:内存位置,输入/输出设备位置,缓冲区队列位置,和midi缓冲区队列位置。
1 SLDataLocator_AndroidSimpleBufferQueue loc_bufq = {SL_DATALOCATOR_ANDROIDSIMPLEBUFFERQUEUE, 2};
得到了缓存队列接口,并注册
1 2 3 4 5 6 7 8 9 10 // get the buffer queue interface result = (*bqPlayerObject)->GetInterface(bqPlayerObject, SL_IID_BUFFERQUEUE, &bqPlayerBufferQueue); assert(SL_RESULT_SUCCESS == result); (void)result; // register callback on the buffer queue result = (*bqPlayerBufferQueue)->RegisterCallback(bqPlayerBufferQueue, bqPlayerCallback, NULL); assert(SL_RESULT_SUCCESS == result); (void)result;
获得其他接口用来控制播放 得到声音特效接口
1 2 3 4 5 // get the effect send interface result = (*bqPlayerObject)->GetInterface(bqPlayerObject, SL_IID_EFFECTSEND, &bqPlayerEffectSend); assert(SL_RESULT_SUCCESS == result); (void)result;
得到音量接口
1 2 3 4 5 6 7 8 9 // get the volume interface result = (*bqPlayerObject)->GetInterface(bqPlayerObject, SL_IID_VOLUME, &bqPlayerVolume); assert(SL_RESULT_SUCCESS == result); (void)result; // set the player's state to playing result = (*bqPlayerPlay)->SetPlayState(bqPlayerPlay, SL_PLAYSTATE_PLAYING); assert(SL_RESULT_SUCCESS == result); (void)result;
提供播放数据 打开音乐文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 // convert Java string to UTF-8 const char *utf8 = (*env)->GetStringUTFChars(env, filename, NULL); assert(NULL != utf8); // use asset manager to open asset by filename AAssetManager* mgr = AAssetManager_fromJava(env, assetManager); assert(NULL != mgr); AAsset* asset = AAssetManager_open(mgr, utf8, AASSET_MODE_UNKNOWN); // release the Java string and UTF-8 (*env)->ReleaseStringUTFChars(env, filename, utf8); // the asset might not be found if (NULL == asset) { return JNI_FALSE; } // open asset as file descriptor off_t start, length; int fd = AAsset_openFileDescriptor(asset, &start, &length); assert(0 <= fd); AAsset_close(asset);
设置播放数据
1 2 3 SLDataLocator_AndroidFD loc_fd = {SL_DATALOCATOR_ANDROIDFD, fd, start, length}; SLDataFormat_MIME format_mime = {SL_DATAFORMAT_MIME, NULL, SL_CONTAINERTYPE_UNSPECIFIED}; SLDataSource audioSrc = {&loc_fd, &format_mime};
播放音乐 播放音乐只需要通过播放接口改变播放状态就可以了,暂停也是,停止也是,但是暂停必须之前的播放缓存做了才行,否则那暂停就相当于停止了
1 result = (*fdPlayerPlay)->SetPlayState(fdPlayerPlay, isPlaying ? SL_PLAYSTATE_PLAYING : SL_PLAYSTATE_PAUSED);
调解音量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 SLVolumeItf getVolume() { if (fdPlayerVolume != NULL) return fdPlayerVolume; else return bqPlayerVolume; } void Java_com_renhui_openslaudio_MainActivity_setVolumeAudioPlayer(JNIEnv env, jclass clazz, jint millibel) { SLresult result; SLVolumeItf volumeItf = getVolume(); if (NULL != volumeItf) { result = (volumeItf)->SetVolumeLevel(volumeItf, millibel); assert(SL_RESULT_SUCCESS == result); (void)result; } }
释放资源 关闭app时释放占用资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void Java_com_renhui_openslaudio_MainActivity_shutdown(JNIEnv* env, jclass clazz) { // destroy buffer queue audio player object, and invalidate all associated interfaces if (bqPlayerObject != NULL) { (*bqPlayerObject)->Destroy(bqPlayerObject); bqPlayerObject = NULL; bqPlayerPlay = NULL; bqPlayerBufferQueue = NULL; bqPlayerEffectSend = NULL; bqPlayerMuteSolo = NULL; bqPlayerVolume = NULL; } // destroy file descriptor audio player object, and invalidate all associated interfaces if (fdPlayerObject != NULL) { (*fdPlayerObject)->Destroy(fdPlayerObject); fdPlayerObject = NULL; fdPlayerPlay = NULL; fdPlayerSeek = NULL; fdPlayerMuteSolo = NULL; fdPlayerVolume = NULL; } // destroy output mix object, and invalidate all associated interfaces if (outputMixObject != NULL) { (*outputMixObject)->Destroy(outputMixObject); outputMixObject = NULL; outputMixEnvironmentalReverb = NULL; } // destroy engine object, and invalidate all associated interfaces if (engineObject != NULL) { (*engineObject)->Destroy(engineObject); engineObject = NULL; engineEngine = NULL; } }
参考源码 https://github.com/renhui/OpenSL_Audio
Android OpenSL ES 开发:Android OpenSL 录制 PCM 音频数据 实现说明 OpenSL ES的录音要比播放简单一些,在创建好引擎后,再创建好录音接口基本就可以录音了。在这里我们做的是流式录音,所以需要用至少2个buffer来缓存录制好的PCM数据,这里我们可以动态创建一个二维数组,里面有2个buffer,然后每次录音取出一个,录制好后再写入文件就可以了,2个buffer依次来存储PCM数据,这样就可以连续录制流式音频数据了,二维数组里面自己维护了一个索引,来标识当前处于哪个buffer录制状态,暴露给外部的只是调用方法而已,细节对外也是隐藏的。
编码实现 编写缓存buffer队列:RecordBuffer.h、RecordBuffer.cpp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #ifndef OPENSLRECORD_RECORDBUFFER_H #define OPENSLRECORD_RECORDBUFFER_H class RecordBuffer { public: short **buffer; int index = -1; public: RecordBuffer(int buffersize); ~RecordBuffer(); /** * 得到一个新的录制buffer * @return */ short* getRecordBuffer(); /** * 得到当前录制buffer * @return */ short* getNowBuffer(); }; #endif //OPENSLRECORD_RECORDBUFFER_H
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include "RecordBuffer.h" RecordBuffer::RecordBuffer(int buffersize) { buffer = new short *[2]; for(int i = 0; i < 2; i++) { buffer[i] = new short[buffersize]; } } RecordBuffer::~RecordBuffer() { } short *RecordBuffer::getRecordBuffer() { index++; if(index > 1) { index = 0; } return buffer[index]; } short *RecordBuffer::getNowBuffer() { return buffer[index]; }
这个队列其实就是PCM存储的buffer,getRecordBuffer()为即将要录入PCM数据的buffer,getNowBuffer()是当前录制好的PCM数据的buffer,可以写入文件,即我们得到的PCM数据。
使用OpenSL ES录制PCM数据 过程分为:创建引擎->初始化IO设备(自动检测麦克风等音频输入设备)->设置缓存队列->设置录制PCM数据规格->设置录音器接口->设置队列接口并设置录音状态为录制->开始录音。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 const char *path = env->GetStringUTFChars(path_, 0); /** * PCM文件 */ pcmFile = fopen(path, "w"); /** * PCMbuffer队列 */ recordBuffer = new RecordBuffer(RECORDER_FRAMES * 2); SLresult result; /** * 创建引擎对象 */ result = slCreateEngine(&engineObject, 0, NULL, 0, NULL, NULL); result = (*engineObject)->Realize(engineObject, SL_BOOLEAN_FALSE); result = (*engineObject)->GetInterface(engineObject, SL_IID_ENGINE, &engineEngine); /** * 设置IO设备(麦克风) */ SLDataLocator_IODevice loc_dev = {SL_DATALOCATOR_IODEVICE, SL_IODEVICE_AUDIOINPUT, SL_DEFAULTDEVICEID_AUDIOINPUT, NULL}; SLDataSource audioSrc = {&loc_dev, NULL}; /** * 设置buffer队列 */ SLDataLocator_AndroidSimpleBufferQueue loc_bq = {SL_DATALOCATOR_ANDROIDSIMPLEBUFFERQUEUE, 2}; /** * 设置录制规格:PCM、2声道、44100HZ、16bit */ SLDataFormat_PCM format_pcm = {SL_DATAFORMAT_PCM, 2, SL_SAMPLINGRATE_44_1, SL_PCMSAMPLEFORMAT_FIXED_16, SL_PCMSAMPLEFORMAT_FIXED_16, SL_SPEAKER_FRONT_LEFT | SL_SPEAKER_FRONT_RIGHT, SL_BYTEORDER_LITTLEENDIAN}; SLDataSink audioSnk = {&loc_bq, &format_pcm}; const SLInterfaceID id[1] = {SL_IID_ANDROIDSIMPLEBUFFERQUEUE}; const SLboolean req[1] = {SL_BOOLEAN_TRUE}; /** * 创建录制器 */ result = (*engineEngine)->CreateAudioRecorder(engineEngine, &recorderObject, &audioSrc, &audioSnk, 1, id, req); if (SL_RESULT_SUCCESS != result) { return; } result = (*recorderObject)->Realize(recorderObject, SL_BOOLEAN_FALSE); if (SL_RESULT_SUCCESS != result) { return; } result = (*recorderObject)->GetInterface(recorderObject, SL_IID_RECORD, &recorderRecord); result = (*recorderObject)->GetInterface(recorderObject, SL_IID_ANDROIDSIMPLEBUFFERQUEUE, &recorderBufferQueue); finished = false; result = (*recorderBufferQueue)->Enqueue(recorderBufferQueue, recordBuffer->getRecordBuffer(), recorderSize); result = (*recorderBufferQueue)->RegisterCallback(recorderBufferQueue, bqRecorderCallback, NULL); LOGD("开始录音"); /** * 开始录音 */ (*recorderRecord)->SetRecordState(recorderRecord, SL_RECORDSTATE_RECORDING); env->ReleaseStringUTFChars(path_, path);
录音回调如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void bqRecorderCallback(SLAndroidSimpleBufferQueueItf bq, void *context) { // for streaming recording, here we would call Enqueue to give recorder the next buffer to fill // but instead, this is a one-time buffer so we stop recording LOGD("record size is %d", recorderSize); fwrite(recordBuffer->getNowBuffer(), 1, recorderSize, pcmFile); if(finished) { (*recorderRecord)->SetRecordState(recorderRecord, SL_RECORDSTATE_STOPPED); fclose(pcmFile); LOGD("停止录音"); } else{ (*recorderBufferQueue)->Enqueue(recorderBufferQueue, recordBuffer->getRecordBuffer(), recorderSize); } }
这样就完成了OPenSL ES的PCM音频数据录制,我们这里拿到了录制的PCM数据可以用mediacodec或ffmpeg来编码成aac格式的音频,也可以直接用推流到服务器来实现音频直播。
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 #include <jni.h> #include <string> #include "AndroidLog.h" #include "RecordBuffer.h" #include "unistd.h" extern "C" { #include <SLES/OpenSLES.h> #include <SLES/OpenSLES_Android.h> } //引擎接口 static SLObjectItf engineObject = NULL; //引擎对象 static SLEngineItf engineEngine; //录音器接口 static SLObjectItf recorderObject = NULL; //录音器对象 static SLRecordItf recorderRecord; //缓冲队列 static SLAndroidSimpleBufferQueueItf recorderBufferQueue; //录制大小设为4096 #define RECORDER_FRAMES (2048) static unsigned recorderSize = RECORDER_FRAMES * 2; //PCM文件 FILE *pcmFile; //录音buffer RecordBuffer *recordBuffer; bool finished = false; void bqRecorderCallback(SLAndroidSimpleBufferQueueItf bq, void *context) { // for streaming recording, here we would call Enqueue to give recorder the next buffer to fill // but instead, this is a one-time buffer so we stop recording LOGD("record size is %d", recorderSize); fwrite(recordBuffer->getNowBuffer(), 1, recorderSize, pcmFile); if(finished) { (*recorderRecord)->SetRecordState(recorderRecord, SL_RECORDSTATE_STOPPED); fclose(pcmFile); LOGD("停止录音"); } else{ (*recorderBufferQueue)->Enqueue(recorderBufferQueue, recordBuffer->getRecordBuffer(), recorderSize); } } extern "C" JNIEXPORT void JNICALL Java_com_renhui_openslrecord_MainActivity_rdSound(JNIEnv *env, jobject instance, jstring path_) { const char *path = env->GetStringUTFChars(path_, 0); /** * PCM文件 */ pcmFile = fopen(path, "w"); /** * PCMbuffer队列 */ recordBuffer = new RecordBuffer(RECORDER_FRAMES * 2); SLresult result; /** * 创建引擎对象 */ result = slCreateEngine(&engineObject, 0, NULL, 0, NULL, NULL); result = (*engineObject)->Realize(engineObject, SL_BOOLEAN_FALSE); result = (*engineObject)->GetInterface(engineObject, SL_IID_ENGINE, &engineEngine); /** * 设置IO设备(麦克风) */ SLDataLocator_IODevice loc_dev = {SL_DATALOCATOR_IODEVICE, SL_IODEVICE_AUDIOINPUT, SL_DEFAULTDEVICEID_AUDIOINPUT, NULL}; SLDataSource audioSrc = {&loc_dev, NULL}; /** * 设置buffer队列 */ SLDataLocator_AndroidSimpleBufferQueue loc_bq = {SL_DATALOCATOR_ANDROIDSIMPLEBUFFERQUEUE, 2}; /** * 设置录制规格:PCM、2声道、44100HZ、16bit */ SLDataFormat_PCM format_pcm = {SL_DATAFORMAT_PCM, 2, SL_SAMPLINGRATE_44_1, SL_PCMSAMPLEFORMAT_FIXED_16, SL_PCMSAMPLEFORMAT_FIXED_16, SL_SPEAKER_FRONT_LEFT | SL_SPEAKER_FRONT_RIGHT, SL_BYTEORDER_LITTLEENDIAN}; SLDataSink audioSnk = {&loc_bq, &format_pcm}; const SLInterfaceID id[1] = {SL_IID_ANDROIDSIMPLEBUFFERQUEUE}; const SLboolean req[1] = {SL_BOOLEAN_TRUE}; /** * 创建录制器 */ result = (*engineEngine)->CreateAudioRecorder(engineEngine, &recorderObject, &audioSrc, &audioSnk, 1, id, req); if (SL_RESULT_SUCCESS != result) { return; } result = (*recorderObject)->Realize(recorderObject, SL_BOOLEAN_FALSE); if (SL_RESULT_SUCCESS != result) { return; } result = (*recorderObject)->GetInterface(recorderObject, SL_IID_RECORD, &recorderRecord); result = (*recorderObject)->GetInterface(recorderObject, SL_IID_ANDROIDSIMPLEBUFFERQUEUE, &recorderBufferQueue); finished = false; result = (*recorderBufferQueue)->Enqueue(recorderBufferQueue, recordBuffer->getRecordBuffer(), recorderSize); result = (*recorderBufferQueue)->RegisterCallback(recorderBufferQueue, bqRecorderCallback, NULL); LOGD("开始录音"); /** * 开始录音 */ (*recorderRecord)->SetRecordState(recorderRecord, SL_RECORDSTATE_RECORDING); env->ReleaseStringUTFChars(path_, path); }extern "C" JNIEXPORT void JNICALL Java_com_renhui_openslrecord_MainActivity_rdStop(JNIEnv *env, jobject instance) { // TODO if(recorderRecord != NULL) { finished = true; } }
验证录制成果 有两种方法:
使用Android OpenSL ES 开发:使用 OpenSL 播放 PCM 数据 的demo进行播放。
使用 ffplay 命令播放,命令为:ffplay -f s16le -ar 44100 -ac 2 temp.pcm (命令由来:在录制代码里的参数为录制规格:PCM、2声道、44100HZ、16bit)
参考源码 https://github.com/renhui/OpenSLRecord
Android OpenSL ES 开发:OpenSL ES利用SoundTouch实现PCM音频的变速和变调 缘由 OpenSL ES 学习到现在已经知道 OpenSL ES 不仅能播放和录制PCM音频数据,还能改变声音大小、设置左声道或右声道播放、还能变速播放,可谓是播放音频的王者。但是变速有一点不好的就是,虽然播放音频的速度变了,但是相应的音调也随之变了,这样的用户体验就不那么好了。所以就想到了用开源的SoundTouch来实现PCM音频变速和变调,OpenSL ES只是单纯的播放PCM数据就可以了。
实现 移植SoundTouch(Android) 下载SoundTouch 源码,当前最新是:v2.0.1
在项目jni文件夹中创建include和SoundTouch文件夹,并把下载好的SoundTouch里面的include和SoundTouch的源码拷贝进去就可以了,目录结构如下:
用SoundTouch转码PCM源文件 因为SoundTouch默认是float(32bit)格式的数据,这里需要先改成short(16bit)的格式。打开STTypes.h文件,修改如下代码:
再注释掉下面这句,不然编译不通过(for x86模拟器):
这样SoundTouch里面处理PCM数据就是用的16bit的数据了。
SoundTouch使用流程 添加命名空间,并创建SoundTouch指针变量 1 2 using namespace soundtouch; SoundTouch *soundTouch;
设置SoundTouch参数 1 2 3 4 5 soundTouch = new SoundTouch(); soundTouch->setSampleRate(44100);//设置采样率,此处为44100,根据实际情况可变 soundTouch->setChannels(2);//声道,此处为立体声 soundTouch->setPitch(1);//变调不变速,如0.5、1.0、1.5等 soundTouch->setTempo(1);//变速不变调,如0.5、1.0、2.0等
向SoundTouch中传入获取到的PCM数据,使用:putSamples函数 1 2 size = fread(pcm_buffer, 1, 4096 * 2, pcmFile); soundTouch->putSamples((const SAMPLETYPE *) pcm_buffer, size / 4);
这里,pcm_buffer是u_int16_t *类型的,也就是说和SoundTouch处理的PCM数据位数是一致的(16bit),所以可以直接传入SoundTouch中。putSamples的第一个参数就是PCM数据指针,第二个参数是采样点的个数,由于是2声道16bit(2byte),所以PCM数据的采样点个数为:num = 大小(size)/ (2 * 2)。
获取SoundTouch输出的PCM数据:使用receiveSamples函数 1 num = soundTouch->receiveSamples(sd_buffer, size / 4);
这里,receiveSamples的第一个参数是SoundTouch(变速或变调)处理后的PCM数据存放的内存地址,第二个参数是可能的最大采样个数,可以和putSamples保持一致,其中sd_buffer是SAMPLETYPE * 类型的,记得要提前分配好内存大小,最后返回值就是SoundTouch处理后的PCM里面所包含的采样个数,由于可能有缓存,所以应循环读取receiveSamples,直到返回值为0为止。
OpenSL ES播放SoundTouch处理后的PCM音频数据 1 (*pcmBufferQueue)->Enqueue(pcmBufferQueue, sd_buffer, size * 4);
由于size是采样个数,所以sd_buffer的大小是:size * 2(声道) * 2(16bit==2字节)。
这样,我们听到的声音就是通过SoundTouch转码过后的了,如:变速不变调,变调不变速,变速又变调都可以自己设置。
思维发散 FFmpeg解码得到的PCM数据(uint_8 *)利用SoundTouch转码 这里要处理的就是把uint_8 *(8bit)的数据转换成short(16bit)的数据格式。这里其实就是做bit的位运算,原理如下如:
转换代码如下:
1 2 3 4 5 for (int i = 0; i < size / 2 + 1; i++) { sd_buffer[i] = (pcm_buffer[i * 2] | (pcm_buffer[i * 2 + 1] << 8)); } soundTouch->putSamples((const SAMPLETYPE *) pcm_buffer, size / 4);
后续操作和16bit的一样不变。
总结 虽然是简单的移植SoundTouch到Android来播放PCM数据,但是还是让我们了解到了数据在内存中怎么排列的,然后可以怎么操作最小单位的bit来达到我们的要求。
参考源码 SoundTouch_OpenSL_Android
Android音视频开发高级探究篇 音视频编解码技术 音视频编解码技术(一):MPEG-4/H.264 AVC 编解码标准 H264 概述 H.264,通常也被称之为H.264/AVC(或者H.264/MPEG-4 AVC或MPEG-4/H.264 AVC)
H.264视频编解码的意义 H.264的出现就是为了创建比以前的视频压缩标准更高效的压缩标准,使用更好高效的视频压缩算法来压缩视频的占用空间,提高存储和传输的效率,在获得有效的压缩效果的同时,使得压缩过程引起的失真最小。MPEG-4 AVC和H.264 是目前较为主流的编码标准。主要定义了两方面的内容:视频数据压缩形式的编码表示和用重建视频信息的语法来描述编码方法。目的是为了保证兼容的编码器能够成功的交互工作,同时也允许制造厂商自由的开发具有竞争力的创新产品。制造厂商只需要注意的事情就是能够获得和标准中采用的方法同样的结果。
H.264编解码的理论依据 提到H.264编解码,我们先简单说一下视频压缩算法。视频压缩算法是通过去除时间、空间的冗余来实现的。在一段时间内,相邻的图像的像素、亮度与色温的差别很小,我们没比要对每一个图像进行完成的编码,而是可以选取这段时间的第一张图(也就是第一帧)作为完整的编码,而后面一段时间的图像只需要记录与第一张图(第一帧)在像素、亮度、色温等方面的差别数据即可。通过去除不同类型的冗余,可以明显的压缩数据,代价就是一部分信息失真。
H.264编解码在整个视频数据处理过程中,属于视频数据处理的编解码层,具体的可以查看本人总结的编解码流程图中的解码部分:Thinking-in-AV / 音视频编解码 / 音视频解码流程概览.png 。编码部分将流程反过来进行理解即可。
H.264相关概念 H.264 的基本单位 在H.264定义的结构中,一个视频图像编码后的数据叫做一帧。 一帧是由一个或多个片(slice)组成的,一个片是由一个或多个宏块(MB)组成的(宏块是H264编码的基本单位),一个宏块是由16x16的yuv数据组成的。
帧类型 在H.264的协议中,定义了三类帧,分别是I帧、B帧和P帧。其中I帧就是之前我们所说的一个完整的图像帧,而B帧和P帧对应的就是之前说的不对全部图像做编码的帧。B帧和P帧的差别在于,P帧是参考之前的I帧生成的,B帧是参考前后的图像帧生成的。
在视频画面播放过程中,若I帧丢失了,则后面的P帧也就随着解不出来,就会出现视频画面黑屏的现象;若P帧丢失了,则视频画面会出现花屏、马赛克等现象。
GOP(画面组) 一个GOP(Group Of Picture)就是一组连续的画面。GOP结构一般有两个数字,其中一个是GOP的长度(即两个I帧之间的B帧和P帧数),另一个数字为I帧和P帧之间的间隔距离(即B帧数)。在一个GOP内I帧解码不依赖任何的其它帧,P帧解码则依赖前面的I帧或P帧,B帧解码依赖前面的I帧或P帧及其后最近的一个P帧。
注意:在码率不变的前提下,GOP值越大,P、B帧的数量会越多,平均每个I、P、B帧所占用的字节数就越多,也就更容易获取较好的图像质量;Reference越大,B帧的数量越多,同理也更容易获得较好的图像质量。但是通过提高GOP值来提高图像质量是有限度的。H264编码器在遇到场景切换的情况时,会自动强制插入一个I帧,此时实际的GOP值被缩短了。另一方面,在一个GOP中,P、B帧是由I帧预测得到的,当I帧的图像质量比较差时,会影响到一个GOP中后续P、B帧的图像质量,直到下一个GOP开始才有可能得以恢复,所以GOP值也不宜设置过大。同时,由于P、B帧的复杂度大于I帧,所以过多的P、B帧会影响编码效率,使编码效率降低。另外,过长的GOP还会影响Seek操作的响应速度,由于P、B帧是由前面的I或P帧预测得到的,所以Seek操作需要直接定位,解码某一个P或B帧时,需要先解码得到本GOP内的I帧及之前的N个预测帧才可以,GOP值越长,需要解码的预测帧就越多,seek响应的时间也越长。
IDR 帧 GOP中的I帧又分为普通I帧和IDR帧,IDR帧就是GOP的第一个I帧,这样区分视为了方便控制编码和解码的流程。 IDR帧一定是I帧,但是I帧不一定是IDR帧。
IDR帧因为附带SPS、PPS等信息,解码器在收到 IDR 帧时,需要做的工作就是:把所有的 PPS 和 SPS 参数进行更新。
可以看出来IDR帧的作用是让解码器立刻刷新相关数据信息,避免出现较大的解码错误问题。
引入IDR帧机制是为了解码的重同步,当解码器解码到 IDR帧时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现错误,在这里可以获得重新同步的机会。IDR帧之后的帧永远不会使用IDR帧之前的数据来解码。
H.264 压缩方式 H.264 压缩算法 H264 的核心压缩算法是帧内压缩和帧间压缩,帧内压缩是生成I帧的算法,帧间压缩是生成B帧和P帧的算法。
而帧间压缩也称为时间压缩(Temporalcompression),它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩是无损的,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
H.264压缩方式说明 H.264压缩视频数据时的具体方式如下:
a). 分组,也就是将一系列变换不大的图像归为一个组,即一个GOP;
b). 定义帧,将每组的图像帧归分为I帧、P帧和B帧三种类型;
c). 预测帧, 以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧;
d). 数据传输, 最后将I帧数据与预测的差值信息进行存储和传输。
H.264 分层结构 H.264的主要目标是为了有高的视频压缩比和良好的网络亲和性,H264将系统框架分为两个层面,分别是视频编码层面(VCL)和网络抽象层面(NAL)。
VLC层(Video Coding Layer) VLC层:包括核心压缩引擎和块,宏块和片的语法级别定义,设计目标是尽可能地独立于网络进行高效的编码;
NAL层(Network Abstraction Layer) NAL层:负责将VCL产生的比特字符串适配到各种各样的网络和多元环境中,覆盖了所有片级以上的语法级别。
NALU (NAL Unit) H.264原始码流(裸流)是由一个接一个NALU组成,结构如下图,一个NALU = 一组对应于视频编码的NALU头部信息 + 一个原始字节序列负荷(RBSP,Raw Byte Sequence Payload)。
一个原始的H.264 NALU 单元常由 [StartCode] [NALU Header] [NALU Payload] 三部分组成。
Start Code Start Code 用于标示这是一个NALU 单元的开始,必须是”00 00 00 01” 或”00 00 01”。
NAL Header由三部分组成,forbidden_bit(1bit),nal_reference_bit(2bits)(优先级),nal_unit_type(5bits)(类型)。
RBSP(Raw Byte Sequence Payload)) 下图是RBSP的序列的样例及相关类型参数的描述表:
SPS是序列参数集,包含的是针对一连续编码视频序列的参数,如标识符 seq_parameter_set_id、帧数及 POC 的约束、参考帧数目、解码图像尺寸和帧场编码模式选择标识等等。
PPS是图像参数集,对应的是一个序列中某一幅图像或者某几幅图像,其参数如标识符 pic_parameter_set_id、可选的 seq_parameter_set_id、熵编码模式选择标识、片组数目、初始量化参数和去方块滤波系数调整标识等等。
参数集是一个独立的数据单位,不依赖于参数集之外的其他句法元素。一个参数集不对应某一个特定的图像或者序列,同一个序列参数集可以被一个或者多个图像参数集引用。同理,一个图像参数集也可以被一个或者多个图像引用。只有在编码器认为需要更新参数集的内容时,才会发出新的参数集。
H.264 局限性 随着数字视频应用产业链的快速发展,视频应用向以下几个方向发展的趋势愈加明显:
(1) 高清晰度(HigherDefinition):数字视频的应用格式从720P向1080P全面升级,而且现在4K的数字视频格式也已经成为常见。
(2) 高帧率(Higherframe rate ):数字视频帧率从30fps向60fps、120fps甚至240fps的应用场景升级;
(3) 高压缩率(HigherCompression rate ):传输带宽和存储空间一直是视频应用中最为关键的资源,因此,在有限的空间和管道中获得最佳的视频体验一直是用户的不懈追求。
但是面对视频应用不断向高清晰度、高帧率、高压缩率方向发展的趋势,当前主流的视频压缩标准协议H.264的局限性不断凸显。主要体现在:
(1) 宏块个数的爆发式增长,会导致用于编码宏块的预测模式、运动矢量、参考帧索引和量化级等宏块级参数信息所占用的码字过多,用于编码残差部分的码字明显减少。
(2) 由于分辨率的大大增加,单个宏块所表示的图像内容的信息大大减少,这将导致相邻的4 x 4或8 x 8块变换后的低频系数相似程度也大大提高,导致出现大量的冗余。
(3) 由于分辨率的大大增加,表示同一个运动的运动矢量的幅值将大大增加,H.264中采用一个运动矢量预测值,对运动矢量差编码使用的是哥伦布指数编码,该编码方式的特点是数值越小使用的比特数越少。因此,随着运动矢量幅值的大幅增加,H.264中用来对运动矢量进行预测以及编码的方法压缩率将逐渐降低。
(4) H.264的一些关键算法例如采用CAVLC和CABAC两种基于上下文的熵编码方法、deblock滤波等都要求串行编码,并行度比较低。针对GPU/DSP/FPGA/ASIC等并行化程度非常高的CPU,H.264的这种串行化处理越来越成为制约运算性能的瓶颈。
于是面向更高清晰度、更高帧率、更高压缩率视频应用的HEVC(H.265)协议标准应运而生。H.265在H.264标准2~4倍的复杂度基础上,将压缩效率提升一倍以上。
(注意:实际使用过程中,不能忽视265专利费用这个重要的问题。专利问题参考:H.265成超级提款机 一场围绕专利授权的战争已经爆发 )
音视频编解码技术(二):AAC 音频编码技术 AAC编码概述 AAC是高级音频编码(Advanced Audio Coding)的缩写,出现于1997年,最初是基于MPEG-2的音频编码技术,目的是取代MP3格式。2000年,MPEG-4标准出台,AAC重新集成了其它技术包括SBR或PS特性,目前AAC可以定义为⼀种由 MPEG-4 标准定义的有损音频压缩格式
AAC编码规格简述 AAC共有9种规格,以适应不同的场合的需要:
MPEG-2 AAC LC 低复杂度规格(Low Complexity) 注:比较简单,没有增益控制,但提高了编码效率,在中等码率的编码效率以及音质方面,都能找到平衡点
MPEG-2 AAC Main 主规格
MPEG-2 AAC SSR 可变采样率规格(Scaleable Sample Rate)
MPEG-4 AAC LC 低复杂度规格(Low Complexity)—现在的手机比较常见的MP4文件中的音频部份就包括了该规格音频文件
MPEG-4 AAC Main 主规格 注:包含了除增益控制之外的全部功能,其音质最好
MPEG-4 AAC SSR 可变采样率规格(Scaleable Sample Rate)
MPEG-4 AAC LTP 长时期预测规格(Long Term Predicition)
MPEG-4 AAC LD 低延迟规格(Low Delay)
MPEG-4 AAC HE 高效率规格(High Efficiency)—这种规格适合用于低码率编码,有Nero ACC 编码器支持
流行的Nero AAC编码程序只支持LC,HE,HEv2这三种规格,编码后的AAC音频,规格显示都是LC。HE其实就是AAC(LC)+ SBR技术,HEv2就是AAC(LC)+ SBR + PS技术;
这里再说明一下HE和HEv2的相关内容:
HE: HE-AAC v1(又称AACPlusV1,SBR),用容器的方法实现了AAC(LC)+SBR技术。SBR其实代表的是Spectral Band Replication(频段复制)。简要叙述一下,音乐的主要频谱集中在低频段,高频段幅度很小,但很重要,决定了音质。如果对整个频段编码,若是为了保护高频就会造成低频段编码过细以致文件巨大;若是保存了低频的主要成分而失去高频成分就会丧失音质。SBR把频谱切割开来,低频单独编码保存主要成分,高频单独放大编码保存音质,“统筹兼顾”了,在减少文件大小的情况下还保存了音质,完美的化解这一矛盾。
HEv2: 用容器的方法包含了HE-AAC v1和PS技术。PS指“parametric stereo”(参数立体声)。原来的立体声文件文件大小是一个声道的两倍。但是两个声道的声音存在某种相似性,根据香农信息熵编码定理,相关性应该被去掉才能减小文件大小。所以PS技术存储了一个声道的全部信息,然后,花很少的字节用参数描述另一个声道和它不同的地方。
AAC编码的特点 (1). AAC是一种高压缩比的音频压缩算法,但它的压缩比要远超过较老的音频压缩算法,如AC-3、MP3等。并且其质量可以同未压缩的CD音质相媲美。
(2). 同其他类似的音频编码算法一样,AAC也是采用了变换编码算法,但AAC使用了分辨率更高的滤波器组,因此它可以达到更高的压缩比。
(3). AAC使用了临时噪声重整、后向自适应线性预测、联合立体声技术和量化哈夫曼编码等最新技术,这些新技术的使用都使压缩比得到进一步的提高。
(4). AAC支持更多种采样率和比特率、支持1个到48个音轨、支持多达15个低频音轨、具有多种语言的兼容能力、还有多达15个内嵌数据流。
(5). AAC支持更宽的声音频率范围,最高可达到96kHz,最低可达8KHz,远宽于MP3的16KHz-48kHz的范围。
(6). 不同于MP3及WMA,AAC几乎不损失声音频率中的甚高、甚低频率成分,并且比WMA在频谱结构上更接近于原始音频,因而声音的保真度更好。
(7). AAC采用优化的算法达到了更高的解码效率,解码时只需较少的处理能力。
AAC音频文件格式 ACC 音频文件格式类型 AAC的音频文件格式有ADIF & ADTS:
ADIF :Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行,这种格式常用在磁盘文件中。
ADTS :Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。
简单说,ADTS可以在任意帧解码,也就是说它每一帧都有头信息。ADIF只有一个统一的头,所以必须得到所有的数据后解码。这两种的header的格式也是不同的,一般编码后的和抽取出的都是ADTS格式的音频流。
AAC的ADIF文件格式如下:
header()
raw_data_stream()
AAC的ADTS文件中一帧的格式如下:
…
syncword
header()
error_check()
raw_data_block()
…
ADTS格式中两边的空白矩形表示当前一帧前后的数据。
ADIF 的头信息如下图:
ADIF头信息位于AAC文件的起始处,接下来就是连续的 Raw Data Blocks。
一个 AAC 原始数据块长度是可变的,对原始帧加上 ADTS 头的封装,就形成了 ADTS 帧。ADTS 头中相对重要的信息有:采样率,声道数,帧长度 ,每一个带 ADTS 头信息的 AAC 流会清晰的告诉解码器它需要的这些信息,解码器才能解析读取。一般情况下 ADTS 的头信息都是 7 个字节,分为 2 部分:
ADTS 的固定头信息:
Syncword: 总是0xFFF,代表一个ADTS帧的开始, 用于同步,解码器可通过0xFFF确定每个ADTS的开始位置.因为它的存在,解码可以在这个流中任何位置开始, 即可以在任意帧解码**。
ID: MPEG Version: 0 for MPEG-4, 1 for MPEG-2
Layer: always: ‘00’
Protection_absent: Warning, set to 1 if there is no CRC and 0 if there is CRC
Profile: 表示使用哪个级别的AAC,如profile的值等于 Audio Object Type的值减1,即profile = MPEG-4 Audio Object Type - 1
sampling_frequency_index : 采样率的下标
channel_configuration :声道数. 比如2表示立体声双声道.
aac_frame_length: 一个ADTS帧的长度包括ADTS头和AAC原始流.
adts_buffer_fullness: 0x7FF 说明是码率可变的码流.
number_of_raw_data_blocks_in_frame: 表示ADTS帧中有number_of_raw_data_blocks_in_frame + 1个AAC原始帧.
在实际开发AAC编解码的时候,尤其是封装ADTS帧的时候,如何设置相关的Header的值,可以参考如下wiki内容:
注意: ACC LC和HE在采样率设置方面不同,LC格式的为正常索引,HE格式的索引为除2后对应的采样索引,这是因为:HE使用了SBR技术,即 Spectral Band Replication(频段复制),所以存储同样的音频内容,HE文件较小。使用时采样率为LC的一半。
ADTS的可变头信息:
(1)Syncword 存在的目的是为了找出帧头在比特流中的位置,ADTS格式的帧头同步字为12比特的“1111 1111 1111”.
(2)ADTS的头信息为两部分组成,其一为固定头信息,紧接着是可变头信息。固定头信息中的数据每一帧都相同,而可变头信息则在帧与帧之间可变。
AAC文件处理流程 (1). 判断文件格式,确定为ADIF或ADTS
(2). 若为ADIF,解ADIF头信息,跳至第6步。
(3). 若为ADTS,寻找同步头。
(4). 解ADTS帧头信息。
(5). 若有错误检测,进行错误检测。
(6). 解块信息。
(7). 解元素信息。
注意: 有时候在处理AAC音频流的时候 (比如:把 AAC 音频的 ES 流从 FLV 封装格式中抽出来送给硬件解码器),编码后的 AAC 文件在PC或者手机上不能播放,导致播放错误,很大可能的原因是 AAC 文件的每一帧缺少 ADTS 头信息文件的包装拼接,这时需要加上头文件 ADTS 即可。
开源AAC解码器 a). 开源AAC解码器faad官方网站:http://www.audiocoding.com/
b). faad2源代码(VC工程)下载地址:http://download.csdn.net/detail/leixiaohua1020/6374877
流媒体协议 流媒体协议(一):HLS 协议 HLS 概述 HLS 全称是 HTTP Live Streaming,是一个由 Apple 公司提出的基于 HTTP 的媒体流传输协议,用于实时音视频流的传输。目前HLS协议被广泛的应用于视频点播和直播领域。
原理介绍: 通过将整条流切割成一个小的可以通过 HTTP 下载的媒体文件, 然后提供一个配套的媒体列表文件, 提供给客户端, 让客户端顺序地拉取这些媒体文件播放, 来实现看上去是在播放一条流的效果.由于传输层协议只需要标准的 HTTP 协议, HLS 可以方便的透过防火墙或者代理服务器, 而且可以很方便的利用 CDN 进行分发加速, 并且客户端实现起来也很方便.
整体架构 HLS的架构分为三部分:Server,CDN,Client 。即服务器、分发组件和客户端。
下面是 HLS 整体架构图:
服务器用于接收媒体输入流,对它们进行编码,封装成适合于分发的格式,然后准备进行分发。
分发组件为标准的 Web 服务器。它们用于接收客户端请求,传递处理过的媒体,把资源和客户端联系起来。
客户端软件决定请求何种合适的媒体,下载这些资源,然后把它们重新组装成用户可以观看的连续流。
HLS 播放 播放未加密HLS HLS格式的视频,只有安卓4.0以上才支持,目前基本4.0一下的机子基本可以考虑不兼容了,所以为了减少工作量,这里继续使用MediaPlayer来进行播放。http://devimages.apple.com/iphone/samples/bipbop/gear1/prog_index.m3u8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ####EXTM3U ####EXT-X-TARGETDURATION:10 ####EXT-X-MEDIA-SEQUENCE:0 ####EXTINF:10, no desc fileSequence0.ts ####EXTINF:10, no desc fileSequence1.ts ####EXTINF:10, no desc fileSequence2.ts ####EXTINF:10, no desc fileSequence3.ts ####EXTINF:10, no desc fileSequence4.ts ####EXTINF:10, no desc fileSequence5.ts ####EXTINF:10, no desc fileSequence6.ts ####EXTINF:10, no desc fileSequence7.ts
我们可以看到里面他又一个一个ts视频片段,这个一个一个视频片段就是我们需要的播放,那么他是如何被播放器识别播放的呢。
实现这种未加密的缓存还是比较好实现的,大概可以分为这几步:
播放加密HLS 看下加密的m3u8文件的格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ####EXTM3U ####EXT-X-VERSION:3 ####EXT-X-KEY:METHOD=AES-128,URI="http://xxxxxx:5555//test/1102/test/segments.key" ####EXT-X-MEDIA-SEQUENCE:0 ####EXT-X-ALLOW-CACHE:YES ####EXT-X-TARGETDURATION:19 ####EXTINF:13.966667, http://xxxxxx:5555/test/1102/test/segments0.ts ####EXTINF:10.000000, http://xxxxxx:5555/test/1102/test/segments1.ts ####EXTINF:10.000000, http://xxxxxx:5555/test/1102/test/segments2.ts ####EXTINF:10.000000, http://xxxxxx.cn:5555/test/1102/test/segments3.ts ####EXTINF:10.000000, http://xxxxxxn.cn:5555/test/1102/test/segments4.ts ####EXTINF:7.033333, http://xxxxxx:5555/test/1102/test/segments5.ts ####EXTINF:10.000000,
我们看到了多了个字段EXT-X-KEY,这个也是m3u8给规定好的加密字段,如果包含这个字段播放器就会先去请求这个key,然后拿这个这个key去访问加密的TS视频就可以播放了。 其实看到这我们就因该有思路怎么去做,加密的缓存播放了。
实现播放加密缓存的思路:
HLS 协议总结 优点:
客户端支持简单, 只需要支持 HTTP 请求即可, HTTP 协议无状态, 只需要按顺序下载媒体片段即可.
使用 HTTP 协议网络兼容性好, HTTP 数据包也可以方便地通过防火墙或者代理服务器, CDN 支持良好.
Apple 的全系列产品支持,不需要安装任何插件就可以原生支持播放 HLS, 目前Android 也加入了对 HLS 的支持.
自带多码率自适应机制。
缺点:
相比 RTMP 这类长连接协议, 延时较高, 难以用到互动直播场景.
对于点播服务来说, 由于 TS 切片通常较小, 海量碎片在文件分发, 一致性缓存, 存储等方面都有较大挑战.
改进 由于客户端每次请求 TS 或 M3U8 有可能一个新的连接请求, 无法有效的标识客户端, 一旦出现问题, 基本无法有效的定位问题。
流媒体协议(二):RTMP协议 概念与摘要 RTMP协议从属于应用层,被设计用来在适合的传输协议(如TCP)上复用和打包多媒体传输流(如音频、视频和互动内容)。RTMP提供了一套全双工的可靠的多路复用消息服务,类似于TCP协议[RFC0793],用来在一对结点之间并行传输带时间戳的音频流,视频流,数据流。通常情况下,不同类型的消息会被分配不同的优先级,当网络传输能力受限时,优先级用来控制消息在网络底层的排队顺序。
RTMP块流 实时消息传递协议块流(RTMP块流)。它作为一款高级多媒体流协议提供了流的多路复用和打包服务。RTMP块流被设计用来传输实时消息协议,它可以使用任何协议来发送消息流。每个消息都包含时间戳和有效类型标识。RTMP块流和RTMP适用于各种视听传播的应用程序,包括一对一的,和一对多的视频直播、点播服务、互动会议应用程序。
当使用一个可靠的传输协议如TCP[RFC0793]时,RTMP块流提供了一种可以在多个流中,基于时间戳的端到端交付所有消息的方法。RTMP块流不提供任何优先级或类似形式的控制,但可以使用更高级别的协议来提供这样的优先级。例如,一个视频服务器可以根据发送的时间或确认每个消息的时间,来决定为一个网络差的用户丢弃视频信息,以确保音频信息的及时接收。
RTMP块流不仅包含了自己的协议控制信息,同时也提供了一个更高级别的协议机制,用来嵌入用户控制信息。
消息格式 消息格式可以被分割成多个块,用来在更高的协议中支持多路复用。在创建块消息格式时,应该包含以下字段:
时间戳
长度
类型ID
消息流ID
握手 RTMP连接从握手开始。它包含三个固定大小的块,不像其他的协议,是由头部大小可变的块组成的。
客户端(初始化连接的一端)和服务端发送同样的三个块。为了方便描述,客户端发送的三个块命名为C0,C1,C2;服务端发送的三个块命名为S0,S1,S2。
握手序列 客户端通过发送C0和C1消息来启动握手过程。客户端必须接收到S1消息,然后发送C2消息。客户端必须接收到S2消息,然后发送其他数据。
服务端必须接收到C0或者C1消息,然后发送S0和S1消息。服务端必须接收到C1消息,然后发送S2消息。服务端必须接收到C2消息,然后发送其他数据。
C0和S0格式 C0和S0包由一个字节组成,下面是C0/S0包内的字段:
123450 1 2 3 4 5 6 7
版本(8比特)
C1和S1格式 C1和S1包长度为1536字节,包含以下字段:
12345678910111213140 1 2 3
时间(4字节)
零(4字节)
随机数据(1528字节)
C2和S2格式 C2和S2包长度为1536字节,作为C1和S1的回应,包含以下字段:
12345678910111213140 1 2 3
时间(4字节)
时间(4字节)
随机数据(1528字节)
RMTP握手 握手过程示意图
1
+——————+ +——————+
下面是握手示意图中提到的状态:
未初始化 注: 在”C0和S0格式”章节中提及,如果服务器不支持客户端的版本号,可以选择降到版本3或中止。
发送版本
握手完成
多媒体文件格式 多媒体文件格式(一):MP4 格式 在互联网常见的格式中,跨平台最好的应该就属MP4文件了。因为MP4文件既可以在PC平台的Flashplayer中播放,又可以在移动平台的Android、iOS等平台中进行播放,而且使用系统默认的播放器即可以播放。
MP4格式是最常见的多媒体文件格式。
MP4 格式标准介绍 MP4格式标准为ISO-14496 Part 12、ISO-14496 Part 14,标准内容不是很多,下面我们来介绍一下格式标准中一些重要的信息。
MP4是一种描述较为全面的容器格式,被认为可以在其中嵌入任何形式的数据,各种编码的视频、音频等都不在话下,常见的大部分的MP4文件存放的AVC(H.264)或MPEG-4(Part 2)编码的视频和AAC编码的音频。MP4格式的官方文件后缀名是“.mp4”,还有其他的以mp4为基础进行的扩展或者是阉割版的格式,如:M4V, 3GP, F4V等。
MP4是由一个个“Box”组成的,大Box中存放小Box,一级嵌套一级来存放媒体信息。下面我们来楚关于Box的几个概念:
MP4文件由许多个Box与FullBox组成。
每个Box由Header和Data两部分组成。
FullBox是Box的扩展,其在Box结构的基础上,在Header中增加8位version标志和24的flags标志。
Header包含了整个Box的长度的大小(size)和类型(type),当size等于0时,代表这个Box是文件的最后一个Box。当size等于1时,说明Box长度需要更多的位来描述,在后面会自定义一个64位的largesize用来描述Box的长度。当type等于uuid时,说明这个Box中的数据是用户自定义扩展类型。
Data为Box的实际数据,可以是纯数据,也可以是更多的子Box。
当一个Box中Data是一系列的子Box时,这个Box又可以称为Container(容器)Box。
MP4常用参考标准Box排列方式 :https://github.com/renhui/Thinking-in-AV/tree/master/多媒体格式/MP4。
介绍了MP4的格式标准后,下面我们来介绍是三个MP4分析工具,为后续理解MP4文件一些关键信息做辅助工具。
MP4分析工具 可以用来分析MP4封装格式的工具比较多,除了FFmpeg、FFprobe之外,还有一些常用的工具,如Elecard StreamEye、mp4box、mp4info等;下面简单介绍一下这几款常用的工具:
Elecard StreamEye Elecard StreamEye是一款非常强大的视频信息查看工具,能够查看帧的排列信息,将I帧、P帧、B帧以不同颜色的柱状展现出来,而且柱的长短将根据帧的大小展示。还能够通过Elecard StreamEye分析MP4的封装的内容信息,包括流信息、宏块的信息、文件头顶额信息、图像的信息以及文件的信息等。还能根据每一帧的顺序逐帧查看,可以看到每一帧的详细信息与状态。
示例如图:
mp4box mp4box 是GPAC项目中的一个组件,可以通过mp4box针对媒体文件进行合成、拆解等操作。
官网地址:https://gpac.wp.imt.fr/mp4box/。
其使用时的常用命令如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 1) mp4box -h 查看mp4box中的所有帮助信息 2) mp4box -h general 查看mp4box中的通用帮助信息 3) mp4box -info test.mp4 查看test.mp4文件是否有问题 4) mp4box -add test.mp4 test-new.mp4 修复test.mp4文件格式不标准的问题,并把新文件保存在test-new.mp4中 5) mp4box -inter 10000 test-new.mp4 解决开始播放test-new.mp4卡一下的问题,为HTTP下载快速播放有效,10000ms 6) mp4box -add file.avi new_file.mp4 把avi文件转换为mp4文件 7) mp4box -hint file.mp4 为RTP准备,此指令将为文件创建RTP提示跟踪信息。这使得经典的流媒体服务器像darwinstreamingserver或QuickTime的流媒体服务器通过RTSP/RTP传输文件 8) mp4box -cat test1.mp4 -cat test2.mp4 -new test.mp4 把test1.mp4和test2.mp4合并到一个新的文件test.mp4中,要求编码参数一致 9) mp4box -force-cat test1.mp4 -force-cat test2.mp4 -new test.mp4 把test1.mp4和test2.mp4强制合并到一个新的文件test.mp4中,有可能不能播放 10) mp4box -add video1.264 -cat video2.264 -cat video3.264 -add audio1.aac -cat audio2.aac -cat audio3.aac -new muxed.mp4 -fps 24 合并多段音视频并保持同步 11) mp4box -split *time_sec* test.mp4 切取test.mp4中的前面time_sec秒的视频文件 12) mp4box -split-size *size *test.mp4 切取前面大小为size KB的视频文件 13) mp4box -split-chunk *S:E* test.mp4 切取起始为S少,结束为E秒的视频文件 14) mp4box -add 1.mp4####video -add 2.mp4####audio -new test.mp4 test.mp4由1.mp4中的视频与2.mp4中的音频合并生成
而通过mp4box也可以查看mp4的信息,其输出内容格式非常类似ffprobe查看的信息,不过想对ffprobe更完善。
mp4info mp4info是一个不错的MP4分析工具,而且是可视化的工具,可以将MP4中的各个Box解析出来,并将其中的数据展现出来。分析MP4文件内容时使用mp4info将会更方便。
结合着此工具,理解MP4的Box会更方便,更直观。
MP4格式重要Box ftyp(File Type Box) 该Box有且只有1个,并且只能被包含在文件层,而不能被其他Box包含。该Box应该被放在文件的最开始,指示该MP4文件应用的相关信息。
“ftyp” body依次包括1个32位的major brand(4个字符),1个32位的minor version(整数)和1个以32位(4个字符)为单位元素的数组Compatible Brands。
moov(Movie Box) 该box包含了文件媒体的metadata信息,“moov”是一个container box,具体内容信息由子box诠释。同File Type Box一样,该box有且只有一个,且只被包含在文件层。一般情况下,“moov”会紧随“ftyp”出现。
moov定义了一个MP4文件中的数据信息,类型是moov,是一个容器Atom,其至少必须包含一下三种Atom中的一种:mvhd标签、cmov标签、rmra标签。
mvhd标签:Movie Header Atom,存放未压缩过的影片信息的头容器。
cmov标签:Compressed Movie Atom,压缩鬼哦的电影信息容器,此容器不常用。
rmra标签:Reference Movie Atom,参考电影信息容器,此容器不常用。
一般情况下,“moov”中会包含1个“mvhd”和若干个“trak”。其中“mvhd”为Header Box,一般作为“moov”的第一个子Box出现(对于其他Container Box来说,Header Box都应作为首个子box出现)。“trak”包含了一个track的相关信息,是一个Container Box。
trak(Track Box) “trak”也是一个container box,其子box包含了该track的媒体数据引用和描述(hint track除外)。一个MP4文件中的媒体可以包含多个track,且至少有一个track,这些track之间彼此独立,有自己的时间和空间信息。“trak”必须包含一个“tkhd”和一个“mdia”,此外还有很多可选的box(略)。其中“tkhd”为track header box,“mdia”为media box,该box是一个包含一些track媒体数据信息box的container box。
mdat(Meida Data Box) 该box包含于文件层,可以有多个,也可以没有(当媒体数据全部为外部文件引用时),用来存储媒体数据。数据直接跟在box type字段后面,具体数据结构的意义需要参考metadata(主要在sample table中描述)。
free或skip(Free Space Box) “free”中的内容是无关紧要的,可以被忽略。该box被删除后,不会对播放产生任何影响。
stbl(Sample Table Box) “stbl”几乎是普通的MP4文件中最复杂的一个box了,首先需要回忆一下sample的概念。sample是媒体数据存储的单位,存储在media的chunk中,chunk和sample的长度均可互不相同,如下图所示。
普通MP4文件的结构重要的部分就讲完了,理解起来可能比较乱,下面这张图是常见的box的树结构图,可以用来大致了解MP4文件的构造。
在MP4文件中,Box的结构与上图中所描述的一般没太大的差别。
MP4格式 与 FFmpeg实战 在FFmpeg中的输出MP4的Demuxer信息 使用命令行 ffmpeg -h demuxder=mp4 查看MP4文件的Demuxer信息:
1 2 Demuxer mov,mp4,m4a,3gp,3g2,mj2 [QuickTime / MOV]: Common extensions: mov,mp4,m4a,3gp,3g2,mj2.
通过FFmepg faststart参数的使用,来理解mdat和moov的顺序的意义 正常情况下,ffmpeg生成的moov是在mdat写完成后再写入的。
下面是一个例子:
1 ffmpeg -i 好汉歌.flv -c copy -f mp4 好汉歌.mp4
使用mp4info查看容器出现的顺序,如图:
可以看出moov box是在mdat的下面。这时,我们可以使用faststart将上图的moov移动到mdat前面。
使用如下命令行:
1 ffmpeg -i 好汉歌.flv -c copy -f mp4 -movflags faststart 好汉歌.mp4
然后使用mp4info查看MP4的容器顺序,就可以看到moov被移动到mdat前面了。如下图所示:
因为MP4的标准中描述的moov与mdat的存放位置前后并没有强制要求,所有有些时候moov这个Box在mdat的后面,有时候在mdat的前面。
在互联网的视频点播中,如果希望MP4文件被快速打开,则需要moov存放在mdat的前面;如果放在后面,则需要将MP4文件下载完成后才可以进行播放。
多媒体文件格式(二):FLV 格式 在网络的直播与点播场景中,FLV也是一种常见的格式,FLV是Adobe发布的一种可以作为直播也可以作为点播的封装格式,其封装格式非常简单,均以FLVTAG的形式存在,并且每一个TAG都是独立存在的,接下来就详细介绍一下FLV标准。
FLV 格式标准介绍 FLV包括文件头(File Header)和文件体(File Body)两部分,其中文件体由一系列的Tag组成。FLV文件的结构如下图:
Header 部分记录了FLV的类型、版本等信息,是FLV的开头。一般差不多占9bytes。具体格式如下:
文件标识(3B):总是为”FLV”, 0x46 0x4c 0x56
版本(1B):目前为0x01
流信息(1B):文件的标志位说明。前5位保留,必须为0;第6位为音频Tag:1表示有音频;第七位保留,为0; 第8位为视频Tag:1表示有视频
Header长度(4B):整个Header的长度,一般为9(版本为0x01时);大于9表示下面还有扩展信息。即0x00000009。
下图是使用工具FlvAnalyzer获取到的FLV的Header的详细信息:
文件体 FLV Body 文件体由一系列的Tag组成。
其中,每个Tag前面还包含了Previous Tag Size字段,表示前面一个Tag的大小。Tag的类型可以是视频、音频和Script,每个Tag只能包含以上三种类型的数据中的一种。
下图是使用FlvAnalyzer获取到的Body信息:
Tag 每个Tag由也是由两部分组成的:Tag Header和Tag Data。Tag Header里存放的是当前Tag的类型、数据区(Tag Data)长度等信息,具体如下:
Tag类型(1):0x08:音频; 0x09:视频; 0x12:脚本; 其他:保留
数据区长度(3):数据区的长度
时间戳(3):整数,单位是毫秒。对于脚本型的tag总是0 (CTS)
时间戳扩展(1):将时间戳扩展为4bytes,代表高8位。很少用到
StreamsID(3):总是0
数据区(由数据区长度决定):数据实体
下面是三个Tag类型说明:
Audio Tag Data结构(音频类型) :音频Tag Data区域开始的第一个字节包含了音频数据的参数信息,从第二个字节开始为音频流数据。
video Tag Data结构(视频类型):视频Tag Data开始的第一个字节包含视频数据的参数信息,从第二个字节开始为视频流数据。
Script Tag Data结构(脚本类型、帧类型):该类型Tag又被称为MetaData Tag,存放一些关于FLV视频和音频的元信息,比如:duration、width、height等。通常该类型Tag会作为FLV文件的第一个tag,并且只有一个,跟在File Header后。
FLV 分析工具 在上节的内容中,我们介绍了FLV的格式信息,同时也提到了FlvAnalyzer工具,下面我们就介绍两个工具,帮助大家整理和学习FLV相关知识:
FlvAnalyzer 通过FlvAnalyzer可以很清晰的看到FLV文件的基本结构,这样能够结合上面了解的FLV的知识,更清晰的查看FLV的格式及结构。
工具地址:https://github.com/renhui/Thinking-in-AV/blob/master/多媒体格式/FLV/FlvAnalyzer.exe
工具使用如图:
左侧树状结构显示flv的信息,可以清楚了解flv文件的结构;
点击左侧节点,右侧显示对应hex与ascii信息,这样就不必打开二进制编辑器了;
通过此工具可以查看audio tag与video tag各个字节(精确到bit)的详细信息,了解每个tag是如何构造的,同时右下角黑色输出框显示某个值的意义;
此工具是雷霄骅整理flvparse的开源代码,制作的flvformatanalysis工具,此工具可以用来帮助学习FLV封装格式结构。此外它还支持分离FLV中的视频流和音频流。
工具地址:https://github.com/renhui/Thinking-in-AV/blob/master/多媒体格式/FLV/SpecialFFLV.exe
工具使用如图:
FLV格式 与 FFmpeg 实战 使用FFmpeg生成带关键索引信息的FLV 在网络视频点播文件为FLV格式文件时,人们经常用工具先对FLV文件进行一次转换,主要是将FLV文件中的关键帧建立一个索引,并将索引写到Metadata头中,这个步骤用FFmpeg可以实现,使用参数add_keyframe_index即可:
1 ffmpeg -i 好汉歌.mp4 -c copy -f flv -flvflags add_keyframe_index out.flv
生成FLV包含了关键帧索引信息,这些关键帧索引信息并不是FLV的标准字段,但是我们在实际应用中,特别是现在直播的应用中,我们往往需要向FLV格式中写入关键帧索引,并将这些索引文件写在Metadata 中,这些我们再次播放的时候,可以很快通过这些关键帧索引站到对应的位置,然后准确快速渲染播放。
使用ffprobe查看FLV关键帧索引相关信息 除了在第二节介绍的两个工具,我们也可以使用ffprobe来解析FLV文件,并且还能将关键帧索引的相关信息打印出来,命令如下:
1 ffprobe -v trace -i out.flv
输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 [NULL @ 0x7fc669002a00] Opening 'out.flv' for reading [file @ 0x7fc667f00480] Setting default whitelist 'file,crypto' Probing flv score:100 size:2048 Probing mp3 score:1 size:2048 [flv @ 0x7fc669002a00] Format flv probed with size=2048 and score=100 [flv @ 0x7fc669002a00] Before avformat_find_stream_info() pos: 13 bytes read:32768 seeks:0 nb_streams:0 [flv @ 0x7fc669002a00] type:18, size:1184, last:-1, dts:0 pos:21 [flv @ 0x7fc669002a00] keyframe stream hasn't been created [flv @ 0x7fc669002a00] type:9, size:45, last:-1, dts:0 pos:1220 [flv @ 0x7fc669002a00] keyframe filepositions = 1296 times = 0 [flv @ 0x7fc669002a00] keyframe filepositions = 159283 times = 3000 [flv @ 0x7fc669002a00] keyframe filepositions = 258004 times = 4000 [flv @ 0x7fc669002a00] keyframe filepositions = 272776 times = 4000 [flv @ 0x7fc669002a00] keyframe filepositions = 405340 times = 6000 [flv @ 0x7fc669002a00] keyframe filepositions = 1215104 times = 16000 [flv @ 0x7fc669002a00] keyframe filepositions = 2529035 times = 26000 [flv @ 0x7fc669002a00] keyframe filepositions = 3198814 times = 36000 [flv @ 0x7fc669002a00] keyframe filepositions = 3623757 times = 41000 [flv @ 0x7fc669002a00] keyframe filepositions = 4882191 times = 51000 [flv @ 0x7fc669002a00] keyframe filepositions = 5951597 times = 61000 [flv @ 0x7fc669002a00] keyframe filepositions = 6256906 times = 63000 [flv @ 0x7fc669002a00] keyframe filepositions = 7235927 times = 73000 [flv @ 0x7fc669002a00] keyframe filepositions = 8175324 times = 83000 [flv @ 0x7fc669002a00] keyframe filepositions = 9203399 times = 93000 [flv @ 0x7fc669002a00] keyframe filepositions = 9936528 times = 103000 [flv @ 0x7fc669002a00] keyframe filepositions = 11056393 times = 113000 [flv @ 0x7fc669002a00] keyframe filepositions = 12183978 times = 123000 [flv @ 0x7fc669002a00] keyframe filepositions = 13014068 times = 133000 [flv @ 0x7fc669002a00] keyframe filepositions = 13610750 times = 143000 [flv @ 0x7fc669002a00] keyframe filepositions = 14628601 times = 153000 [flv @ 0x7fc669002a00] keyframe filepositions = 15873046 times = 163000 [flv @ 0x7fc669002a00] keyframe filepositions = 17112198 times = 173000 [flv @ 0x7fc669002a00] keyframe filepositions = 18301365 times = 182000 [flv @ 0x7fc669002a00] keyframe filepositions = 18604436 times = 186000 [flv @ 0x7fc669002a00] 0 17 0 [flv @ 0x7fc669002a00] type:8, size:9, last:-1, dts:0 pos:1280 [flv @ 0x7fc669002a00] 1 AF 0 [flv @ 0x7fc669002a00] type:9, size:2117, last:-1, dts:0 pos:1304 [flv @ 0x7fc669002a00] 0 17 0 [NULL @ 0x7fc668809e00] nal_unit_type: 7, nal_ref_idc: 3 [NULL @ 0x7fc668809e00] nal_unit_type: 8, nal_ref_idc: 3 [NULL @ 0x7fc668809e00] user data:"x264 - core 142 r2 dd79a61 - H.264/MPEG-4 AVC codec - Copyleft 2003-2014 - http://www.videolan.org/x264.html - options: cabac=1 ref=8 deblock=1:-1:-1 analyse=0x1:0x131 me=umh subme=9 psy=1 psy_rd=1.00:0.15 mixed_ref=1 me_range=24 chroma_me=1 trellis=2 8x8dct=0 cqm=0 deadzone=21,11 fast_pskip=0 chroma_qp_offset=-3 threads=24 lookahead_threads=2 sliced_threads=0 nr=0 decimate=1 interlaced=0 bluray_compat=0 stitchable=1 constrained_intra=0 bframes=3 b_pyramid=2 b_adapt=2 b_bias=0 direct=3 weightb=1 open_gop=0 weightp=2 keyint=250 keyint_min=25 scenecut=40 intra_refresh=0 rc_lookahead=60 rc=2pass mbtree=1 bitrate=680 ratetol=1.0 qcomp=0.60 qpmin=0 qpmax=69 qpstep=4 cplxblur=20.0 qblur=0.5 ip_ratio=1.40 aq=1:1.00" [h264 @ 0x7fc668809e00] nal_unit_type: 7, nal_ref_idc: 3 [h264 @ 0x7fc668809e00] nal_unit_type: 8, nal_ref_idc: 3 [h264 @ 0x7fc668809e00] nal_unit_type: 6, nal_ref_idc: 0 [h264 @ 0x7fc668809e00] nal_unit_type: 5, nal_ref_idc: 3 [h264 @ 0x7fc668809e00] user data:"x264 - core 142 r2 dd79a61 - H.264/MPEG-4 AVC codec - Copyleft 2003-2014 - http://www.videolan.org/x264.html - options: cabac=1 ref=8 deblock=1:-1:-1 analyse=0x1:0x131 me=umh subme=9 psy=1 psy_rd=1.00:0.15 mixed_ref=1 me_range=24 chroma_me=1 trellis=2 8x8dct=0 cqm=0 deadzone=21,11 fast_pskip=0 chroma_qp_offset=-3 threads=24 lookahead_threads=2 sliced_threads=0 nr=0 decimate=1 interlaced=0 bluray_compat=0 stitchable=1 constrained_intra=0 bframes=3 b_pyramid=2 b_adapt=2 b_bias=0 direct=3 weightb=1 open_gop=0 weightp=2 keyint=250 keyint_min=25 scenecut=40 intra_refresh=0 rc_lookahead=60 rc=2pass mbtree=1 bitrate=680 ratetol=1.0 qcomp=0.60 qpmin=0 qpmax=69 qpstep=4 cplxblur=20.0 qblur=0.5 ip_ratio=1.40 aq=1:1.00" [h264 @ 0x7fc668809e00] Reinit context to 576x432, pix_fmt: yuv420p [h264 @ 0x7fc668809e00] no picture [flv @ 0x7fc669002a00] type:9, size:1653, last:-1, dts:40 pos:3436 [flv @ 0x7fc669002a00] 0 27 0(省略......) [flv @ 0x7fc669002a00] 1 AF 0 [flv @ 0x7fc669002a00] type:9, size:88, last:-1, dts:1600 pos:31870 [flv @ 0x7fc669002a00] 0 27 0 [flv @ 0x7fc669002a00] All info found [flv @ 0x7fc669002a00] stream 0: start_time: 0.080 duration: -9223372036854776.000 [flv @ 0x7fc669002a00] stream 1: start_time: 0.080 duration: -9223372036854776.000 [flv @ 0x7fc669002a00] format: start_time: 0.080 duration: 189.440 bitrate=787 kb/s [flv @ 0x7fc669002a00] After avformat_find_stream_info() pos: 31965 bytes read:32768 seeks:0 frames:74 Input #0, flv, from 'out.flv': Metadata: major_brand : isom minor_version : 512 compatible_brands: isomiso2avc1mp41 artist : yinyuetai.com album : Yinyuetai date : 04/01/15 15:51:32 comment : Yinyuetai-1TR1026 encoder : Lavf57.83.100 hasVideo : true hasKeyframes : true hasAudio : true hasMetadata : true canSeekToEnd : true datasize : 18639072 videosize : 16303552 audiosize : 2335015 lasttimestamp : 189 lastkeyframetimestamp: 187 lastkeyframelocation: 18603951 Duration: 00:03:09.44, start: 0.080000, bitrate: 787 kb/s Stream #0:0, 41, 1/1000: Video: h264 (Main), 1 reference frame, yuv420p(progressive, left), 576x432, 0/1, 684 kb/s, 25 fps, 25 tbr, 1k tbn, 50 tbc Stream #0:1, 33, 1/1000: Audio: aac (HE-AAC), 44100 Hz, stereo, fltp, 95 kb/s [h264 @ 0x7fc668824400] nal_unit_type: 7, nal_ref_idc: 3 [h264 @ 0x7fc668824400] nal_unit_type: 8, nal_ref_idc: 3 [AVIOContext @ 0x7fc667f005c0] Statistics: 32768 bytes read, 0 seeks
从以上内容可以看到,输出信息包含了keyframe关键帧存储在文件中的偏移位置及时间戳。
多媒体文件格式(三):M3U8 格式 M3U8 格式标准介绍 M3U8文件是指UTF-8编码格式的M3U文件。M3U文件是记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。
M3U8是一种常见的流媒体格式,主要以文件列表的形式存在,既支持直播又支持点播,尤其在Android、iOS等平台最为常用。
下面是CCTV6直播播放地址:http://ivi.bupt.edu.cn/hls/cctv6hd.m3u8的M3U8的文件列表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #EXTM3U #EXT-X-VERSION:3 #EXT-X-MEDIA-SEQUENCE:35232 #EXT-X-TARGETDURATION:10 #EXTINF:10.000, cctv6hd-1549272376000.ts #EXTINF:10.000, cctv6hd-1549272386000.ts #EXTINF:10.000, cctv6hd-1549272396000.ts #EXTINF:10.000, cctv6hd-1549272406000.ts #EXTINF:10.000, cctv6hd-1549272416000.ts #EXTINF:10.000, cctv6hd-1549272426000.ts
下面我们来分别说明一下相关的几个字段:
EXTM3U:这个是M3U8文件必须包含的标签,并且必须在文件的第一行,所有的M3U8文件中必须包含这个标签。
EXT-X-VERSION:M3U8文件的版本,常见的是3(目前最高版本应该是7)。
EXT-X-TARGETDURATION:该标签指定了媒体文件持续时间的最大值,播放文件列表中的媒体文件在EXTINF标签中定义的持续时间必须小于或者等于该标签指定的持续时间。该标签在播放列表文件中必须出现一次。
EXT-X-MEDIA-SEQUENCE:M3U8直播是的直播切换序列,当播放打开M3U8时,以这个标签的值作为参考,播放对应的序列号的切片。
EXTINF:EXTINF为M3U8列表中每一个分片的duration,如上面例子输出信息中的第一片的duration为10秒。在EXTINF标签中,除了duration值,还可以包含可选的描述信息,主要为标注切片信息,使用逗号分隔开。
关于客户端播放M3U8的标准还有更多的讲究,下面我们来介绍一些:
分片必须是动态改变的,序列不能相同,并且序列必须是增序的。
当M3U8没有出现EXT-X-ENDLIST标签时,无论这个M3U8列表中有多少分片,播放分片都是从倒数第三片开始播放,如果不满三片则不应该播放。当然如果有些播放器做了特别定制了,则可以不遵照这个原则。
以播放当前分片的duration时间刷新M3U8列表,然后做对应的加载动作。
前一片分片和后一片分片有不连续的时候,播放可能会出错,那么需要X-DISCONTINUTY标签来解决这个错误。
如果播放列表在刷新之后与之前的列表相同,那么在播放当前分片duration一半的时间内在刷新一次。
在上面,我们提到了,一些上面例子没有出现的一些标签字段,下面我们针对一些额外的标签做一些补充说明:
EXT-X-ENDLIST:若出现EXT-X-ENDLIST标签,则表明M3U8文件不会再产生更多的切片,可以理解为该M3U8已停止更新,并且播放分片到这个标签后结束。M3U8不仅仅是可以作为直播,也可以作为点播存在,在M3U8文件中保存所有切片信息最后使用EXT-X-ENDLIST结尾,这个M3U8即为点播M3U8。EXT-X-ENDLIST标签可能会出现在播放列表文件的任何地方,但是不能出现两次或以上。
EXT-X-STREAM-INF:EXT-X-STREAM-INF标签出现在M3U8时,主要是出现在多级M3U8文件中时,例如M3U8中包含子M3U8列表,或者主M3U8中包含多码率M3U8时;该标签后需要跟一些属性,下面就来逐一说明一下这些属性:
BANDWIDTH:BANDWIDTH的值为最高码率值,当播放EXT-X-STREAM-INF下对应的M3U8时占用的最大码率(必要参数)。
AVERAGE-BANDWIDTH:AVERAGE-BANDWIDTH的值为平均码率值,当播放EXT-X-STREAM-INF下对应的M3U8时占用的平均码率。(可选参数)。
CODECS:CODECS的值用于声明EXT-X-STREAM-INF下面对应M3U8里面的音视频编码、视频编码的信息(可选参数)。
RESOLUTION:M3U8中视频的宽高信息描述(可选参数)。
FRAME-RATE:子M3U8中的视频帧率(可选参数)。
HLS 与 M3U8 HLS(全称:Http Live Streaming)是由Apple公司定义的用于实时流传输的协议,HLS基于HTTP协议实现,传输内容包括两部分,一是M3U8描述文件,二是TS媒体文件。
HLS的优势为:自适应码率流播(adaptive streaming)。效果就是客户端会根据网络状况自动选择不同码率的视频流,条件允许的情况下使用高码率,网络繁忙的时候使用低码率,并且能够自动在二者之间随意切换。这对移动设备网络状况不稳定的情况下保障流畅播放非常有帮助。实现方法是服务器端提供多码率视频流,并且在列表文件中注明,播放器根据播放进度和下载速度进行自动调整。
为什么要用 TS 而不是 MP4?这是因为两个 TS 片段可以无缝拼接,播放器能连续播放,而 MP4 文件由于编码方式的原因,两段 MP4 不能无缝拼接,播放器连续播放两个 MP4 文件会出现破音和画面间断,影响用户体验。而且如果要在一段长达一小时的视频中跳转,如果使用单个 MP4 格式的视频文件,并且也是用 HTTP 协议,那么需要代理服务器支持 HTTP range request 获取大文件中的一部分。这样的话,对于代理服务器的性能来说要求较高。而 HTTP Live Streaming 则只需要根据列表文件中的时间轴找出对应的 TS 片段下载即可,不需要 range request,对代理服务器的要求小很多。所有代理服务器都支持小文件的高效缓存。
FFmpeg转HLS文件(M3U8)实战 FFmpeg转MP4为HLS(M3U8)文件 将MP4文件转换成HLS(M3U8)命令行:
1 ffmpeg -re -i 好汉歌.mp4 -c copy -f hls -bsf:v h264_mp4toannexb output.m3u8
可以看到生成的M3U8及相应的ts文件:
查看一下生成的M3U8文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:10 #EXT-X-MEDIA-SEQUENCE:19 #EXTINF:10.000000, output19.ts #EXTINF:10.000000, output20.ts #EXTINF:9.280000, output21.ts #EXTINF:4.120000, output22.ts #EXTINF:2.440000, output23.ts #EXT-X-ENDLIST
细心的人可能发现一个问题,就是生成的m3u8文件里只有最后的五个片段的信息。这是因为ffmpeg 默认的list size 为5,所以只获得最后的5个片段。为了解决这个问题,需要指定参数-hls_list_size 0,这样就能包含所有的片段。
下面是优化后的命令行:
1 ffmpeg -re -i 好汉歌.mp4 -c copy -f hls -hls_list_size 0 -bsf:v h264_mp4toannexb output.m3u8
这时,我们可以看到从output0.ts到output23.ts的文件列表了。
可能有人会发现,无论是优化之前的命令行,还是优化后的命令行都有一个参数-bsf:v h264_mp4toannexb,这个参数的作用是将MP4中的H.264数据转换成为H.264 AnnexB标准的编码,AnnexB标准的编码常见于实时传输流中。如果源文件为FLV、TS等可以作为直播传输流的视频,则不需要这个参数。
下面我们逐一介绍下使用FFmpeg生成HLS时还可以配置的其他参数。
FFmpeg 转 HLS (M3U8) 文件命令参数 start_number 参数 start_number 参数用于设置M3U8列表中的第一片的序列数。
下面的例子中,我们使用start_number参数设置M3U8中的第一片序列书为100,命令行如下:
1 ffmpeg -re -i huijia.mp4 -c copy -f hls -start_number 100 -hls_list_size 0 -bsf:v h264_mp4toannexb output.m3u8
输出的M3U8内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:3 #EXT-X-MEDIA-SEQUENCE:100 #EXTINF:3.000000, output100.ts #EXTINF:3.000000, output101.ts #EXTINF:3.000000, output102.ts #EXTINF:3.000000, output103.ts #EXTINF:3.000000, output104.ts #EXTINF:3.000000, output105.ts #EXTINF:3.000000, output106.ts #EXTINF:1.000000, output107.ts #EXT-X-ENDLIST
从输出可以看出,切片的第一片编号是100,上面的命令行参数的-start_number参数已生效。
hls_time 参数 hls_time参数用于设置M3U8列表中切片的duration。
下面的例子中,我们使用hls_time参数设置M3U8的TS文件的每一片时长为9秒左右。命令行如下:
1 ffmpeg -re -i huijia.mp4 -c copy -f hls -hls_time 9 -hls_list_size 0 -bsf:v h264_mp4toannexb output.m3u8
然后查看输出的M3U8内容如下:
1 2 3 4 5 6 7 8 9 10 11 #EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:9 #EXT-X-MEDIA-SEQUENCE:0 #EXTINF:9.000000, output0.ts #EXTINF:9.000000, output1.ts #EXTINF:4.000000, output2.ts #EXT-X-ENDLIST
可以看到TS的文件每一片的时常都是9秒左右,hls_time参数生效。
( 注意:hls_time设置后效果不一定准确,会受到关键帧大小及其他因素影响。)
如果需要相对非常准确的切片,可以添加hls_flags的子参数split_by_time来保证生成的切片能够与hls_time设置的切片时长差不多。
( 注意:split_by_time参数必须与hls_time配合使用,并且使用split_by_time参数有可能会影响首画面体验,例如花屏或者首画面显示慢的问题,因为视频的第一帧不一定是关键帧。)
hls_list_size 参数 hls_list_size参数用于为M3U8列表中的TS切片的个数。其中设置为0的时候,将包含所有。
这个命令,我们在第3节优化MP4转HLS文件的命令行时使用到了。
下面的例子中,我们使用hls_list_size参数设置只保留2片TS切片。命令行如下:
1 ffmpeg -re -i huijia.mp4 -c copy -f hls -hls_list_size 2 -bsf:v h264_mp4toannexb output.m3u8
查看输出的M3U8内容如下:
1 2 3 4 5 6 7 8 9 #EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:3 #EXT-X-MEDIA-SEQUENCE:6 #EXTINF:3.000000, output6.ts #EXTINF:1.000000, output7.ts #EXT-X-ENDLIST
从输出的M3U8内容可以看出,在M3U8文件中只保留了2片TS的文件信息,可以看出hls_list_size设置生效了。
hls_base_url参数 hls_base_url 参数用于为M3U8列表的文件路径设置前置基本路径参数,因为在FFmpeg中生成M3U8时写入的TS切片路径默认为M3U8生成的路径相同,但是实际上TS所存储的路径既可以为本地绝对路径,也可以为相对路径,还可以为网络路径,因此使用hls_base_url参数可以达到该效果,命令行如下:
1 ffmpeg -re -i huijia.mp4 -c copy -f hls -hls_base_url /Users/renhui/Desktop/test/ -bsf:v h264_mp4toannexb output.m3u8
查看输出的M3U8内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:3 #EXT-X-MEDIA-SEQUENCE:3 #EXTINF:3.000000, /Users/renhui/Desktop/test/output3.ts #EXTINF:3.000000, /Users/renhui/Desktop/test/output4.ts #EXTINF:3.000000, /Users/renhui/Desktop/test/output5.ts #EXTINF:3.000000, /Users/renhui/Desktop/test/output6.ts #EXTINF:1.000000, /Users/renhui/Desktop/test/output7.ts #EXT-X-ENDLIST
可以看到,TS的路径变为绝对路径了,使用ffplay output.m3u8播放,看到播放是能够正常播放的。这样就可以说明hls_base_url生效了。
多媒体文件格式(四):TS 格式 TS 格式标准介绍 TS是一种音视频封装格式,全称为MPEG2-TS。其中TS即”Transport Stream”的缩写。
先简要介绍一下什么是MPEG2-TS:
DVD的音视频格式为MPEG2-PS,全称是Program Stream。而TS的全称则是Transport Stream。MPEG2-PS主要应用于存储的具有固定时长的节目,如DVD电影,而MPEG-TS则主要应用于实时传送的节目,比如实时广播的电视节目。这两种格式的主要区别是什么呢?简单地打个比喻说,你将DVD上的VOB文件的前面一截cut掉(或者干脆就是数据损坏),那么就会导致整个文件无法解码了,而电视节目是你任何时候打开电视机都能解码(收看)的。
所以,MPEG2-TS格式的特点就是要求从视频流的任一片段开始都是可以独立解码的。
我们可以看出,TS格式是主要用于直播的码流结构,具有很好的容错能力。通常TS流的后缀是.ts、.mpg或者.mpeg,多数播放器直接支持这种格式的播放。TS流中不包含快速seek的机制,只能通过协议层实现seek。HLS协议基于TS流实现的。
TS格式分析工具:链接: https://pan.baidu.com/s/1mXPIyTt6dzuDUaTRqRMgCw 提取码: je5m
TS 格式详解 TS文件(流)可以分为三层:TS层(Transport Stream)、PES层(Packet Elemental Stream)、ES层(Elementary Stream)。
ES层就是音视频数据,PES层是在音视频数据上加了时间戳等对数据帧的说明信息,TS层是在PES层上加入了数据流识别和传输的必要信息。TS文件(码流)由多个TS Packet组成的。
下图是TS文件(码流)的分层结构图:
原图可以在:https://github.com/renhui/Thinking-in-AV/blob/master/多媒体格式/TS/1.TS分层结构.jpg 查看。
TS层 TS包大小固定为188字节,TS层分为三个部分:TS Header、Adaptation Field、Payload。
TS Header固定4个字节;Adaptation Field可能存在也可能不存在,主要作用是给不足188字节的数据做填充;Payload是PES数据。
TS包的包头提供关于传输方面的信息。
TS包的包头长度不固定,前4个字节是固定的,后面可能跟有自适应字段(适配域)。4个字节是最小包头。
包头的结构体字段如下:
sync_byte(同步字节):固定为0x47;该字节由解码器识别,使包头和有效负载可相互分离。
transport_error_indicator(传输错误标志):‘1’表示在相关的传输包中至少有一个不可纠正的错误位。当被置1后,在错误被纠正之前不能重置为0。
payload_unit_start_indicator(负载起始标志):为1时,表示当前TS包的有效载荷中包含PES或者PSI的起始位置;在前4个字节之后会有一个调整字节,其的数值为后面调整字段的长度length。因此有效载荷开始的位置应再偏移1+[length]个字节。
transport_priority(传输优先级标志):‘1’表明当前TS包的优先级比其他具有相同PID, 但此位没有被置‘1’的TS包高。
PID:指示存储与分组有效负载中数据的类型。
transport_scrambling_control(加扰控制标志):表示TS流分组有效负载的加密模式。空包为‘00’,如果传输包包头中包括调整字段,不应被加密。其他取值含义是用户自定义的。
adaptation_field_control(适配域控制标志):表示包头是否有调整字段或有效负载。‘00’为ISO/IEC未来使用保留;‘01’仅含有效载荷,无调整字段;‘10’ 无有效载荷,仅含调整字段;‘11’ 调整字段后为有效载荷,调整字段中的前一个字节表示调整字段的长度length,有效载荷开始的位置应再偏移[length]个字节。空包应为‘10’。
continuity_counter(连续性计数器):随着每一个具有相同PID的TS流分组而增加,当它达到最大值后又回复到0。范围为0~15。
TS Adaptation Field Adaptation Field的长度要包含传输错误指示符标识的一个字节。
PCR是节目时钟参考,PCR、DTS、PTS都是对同一个系统时钟的采样值,PCR是递增的,因此可以将其设置为DTS值,音频数据不需要PCR。
打包TS流时PAT和PMT表是没有Adaptation Field的,不够的长度直接补0xff即可。
视频流和音频流都需要加adaptation field,通常加在一个帧的第一个ts包和最后一个ts包里,中间的ts包不加。
TS Payload TS包中Payload所传输的信息包括两种类型:视频、音频的PES包以及辅助数据;节目专用信息PSI。
TS包也可以是空包。空包用来填充TS流,可能在重新进行多路复用时被插入或删除。
视频、音频的ES流需进行打包形成视频、音频的 PES流。辅助数据(如图文电视信息)不需要打成PES包。
PES层 & ES 层 PES层 PES结构如图:
从上面的结构图可以看出,PES层是在每一个视频/音频帧上加入了时间戳等信息,PES包内容很多,下面我们说明一下最常用的字段:
pes start code:开始码,固定为0x000001。
stream id:音频取值(0xc0-0xdf),通常为0xc0;视频取值(0xe0-0xef),通常为0xe0。
pes packet length:后面pes数据的长度,0表示长度不限制,只有视频数据长度会超过0xffff。
pes data length:后面数据的长度,取值5或10。
pts:33bit值
dts:33bit值
关于时间戳PTS和DTS的说明:
PTS是显示时间戳、DTS是解码时间戳。
视频数据两种时间戳都需要,音频数据的PTS和DTS相同,所以只需要PTS。
有PTS和DTS两种时间戳是B帧引起的,I帧和P帧的PTS等于DTS。如果一个视频没有B帧,则PTS永远和DTS相同。
从文件中顺序读取视频帧,取出的帧顺序和DTS顺序相同。DTS算法比较简单,初始值 + 增量即可,PTS计算比较复杂,需要在DTS的基础上加偏移量。
音频的PES中只有PTS(同DTS),视频的I、P帧两种时间戳都要有,视频B帧只要PTS(同DTS)。
ES 层 ES层指的就是音视频数据。
一般的,视频为H.264视频,音频为AAC音频。
TS流生成及解析流程 TS 流生成流程
将原始音视频数据压缩之后,压缩结果组成一个基本码流(ES)。
对ES(基本码流)进行打包形成PES。
在PES包中加入时间戳信息(PTS/DTS)。
将PES包内容分配到一系列固定长度的传输包(TS Packet)中。
在传输包中加入定时信息(PCR)。
在传输包中加入节目专用信息(PSI) 。
连续输出传输包形成具有恒定比特率的MPEG-TS流。
TS 流解析流程
复用的MPEG-TS流中解析出TS包;
从TS包中获取PAT及对应的PMT;
从而获取特定节目的音视频PID;
通过PID筛选出特定音视频相关的TS包,并解析出PES;
从PES中读取到PTS/DTS,并从PES中解析出基本码流ES;
将ES交给解码器,获得压缩前的原始音视频数据。
多媒体文件格式(五):PCM / WAV 格式 名词解析 PCM(Pulse Code Modulation)也被称为脉码编码调制,PCM中的声音数据没有被压缩,它是由模拟信号经过采样、量化、编码转换成的标准的数字音频数据。采样转换方式参考下图进行了解:
音频采样包含以下几大要素:
采样率 采样率表示音频信号每秒的数字快照数。该速率决定了音频文件的频率范围。采样率越高,数字波形的形状越接近原始模拟波形。低采样率会限制可录制的频率范围,这可导致录音表现原始声音的效果不佳。根据奈奎斯特采样定理,为了重现给定频率,采样率必须至少是该频率的两倍。例如,一般CD唱片的采样率为每秒 44,100 个采样,因此可重现最高为 22,050 Hz 的频率,此频率刚好超过人类的听力极限 20,000 Hz。
图中A是低采样率的音频信号,其效果已经将原始声波进行了扭曲,B则是完全重现原始声波的高采样率的音频信号。
数字音频常用的采样率如下:
位深度 位深度决定动态范围。采样声波时,为每个采样指定最接近原始声波振幅的振幅值。较高的位深度可提供更多可能的振幅值,产生更大的动态范围、更低的噪声基准和更高的保真度。
位深度越高,提供的动态范围越大。
PCM 在上面的名词解析中我们应该对PCM有了一定的理解和认识,下面我们将对PCM做更多的讲解。
PCM音频数据存储方式 如果是单声道的文件,采样数据按时间的先后顺序依次存入。如果是单声道的音频文件,采样数据按时间的先后顺序依次存入(也可能采用 LRLRLR 方式存储,只是另一个声道的数据为 0)。
如果是双声道的话通常按照 LRLRLR 的方式存储,存储的时候还和机器的大小端有关。(关于字节序大小端的相关内容可参考《字节序问题之大小端模式讲解 》进行了解)
PCM的存储方式为小端模式,存储Data数据排列如下图所示:
PCM 音频数据的参数 描述 PCM 音频数据的参数的时候有如下描述方式:
1 2 3 44100HZ 16bit stereo: 每秒钟有 44100 次采样, 采样数据用 16 位(2 字节)记录, 双声道(立体声) 22050HZ 8bit mono: 每秒钟有 22050 次采样, 采样数据用 8 位(1 字节)记录, 单声道 48000HZ 32bit 51ch: 每秒钟有 48000 次采样, 采样数据用 32 位(4 字节浮点型)记录, 5.1 声道
44100Hz 指的是采样率,它的意思是每秒取样 44100 次。采样率越大,存储数字音频所占的空间就越大。
16bit 指的是采样精度,意思是原始模拟信号被采样后,每一个采样点在计算机中用 16 位(两个字节)来表示。采样精度越高越能精细地表示模拟信号的差异。
Stereo 指的是声道数,也即采样时用到的麦克风的数量,麦克风越多就越能还原真实的采样环境(当然麦克风的放置位置也是有规定的)。
WAV WAV 是 Microsoft 和 IBM 为 PC 开发的一种声音文件格式,它符合 RIFF(Resource Interchange File Format)文件规范,用于保存 Windows 平台的音频信息资源,被 Windows 平台及其应用程序所广泛支持。WAVE 文件通常只是一个具有单个 “WAVE” 块的 RIFF 文件,该块由两个子块(”fmt” 子数据块和 ”data” 子数据块),它的格式如下图所示:
WAV 格式定义
该格式的实质就是在 PCM 文件的前面加了一个文件头,每个字段的的含义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 typedef struct { char ChunkID[4]; //内容为"RIFF" unsigned long ChunkSize; //存储文件的字节数(不包含ChunkID和ChunkSize这8个字节) char Format[4]; //内容为"WAVE“ } WAVE_HEADER; typedef struct { char Subchunk1ID[4]; //内容为"fmt" unsigned long Subchunk1Size; //存储该子块的字节数(不含前面的Subchunk1ID和Subchunk1Size这8个字节) unsigned short AudioFormat; //存储音频文件的编码格式,例如若为PCM则其存储值为1。 unsigned short NumChannels; //声道数,单声道(Mono)值为1,双声道(Stereo)值为2,等等 unsigned long SampleRate; //采样率,如8k,44.1k等 unsigned long ByteRate; //每秒存储的bit数,其值 = SampleRate * NumChannels * BitsPerSample / 8 unsigned short BlockAlign; //块对齐大小,其值 = NumChannels * BitsPerSample / 8 unsigned short BitsPerSample; //每个采样点的bit数,一般为8,16,32等。 } WAVE_FMT; typedef struct { char Subchunk2ID[4]; //内容为“data” unsigned long Subchunk2Size; //接下来的正式的数据部分的字节数,其值 = NumSamples * NumChannels * BitsPerSample / 8 } WAVE_DATA;
WAV 文件头解析
这里是一个 WAVE 文件的开头 72 字节,字节显示为十六进制数字:
1 2 3 4 5 6 52 49 46 46 | 24 08 00 00 | 57 41 56 45 66 6d 74 20 | 10 00 00 00 | 01 00 02 00 22 56 00 00 | 88 58 01 00 | 04 00 10 00 64 61 74 61 | 00 08 00 00 | 00 00 00 00 24 17 1E F3 | 3C 13 3C 14 | 16 F9 18 F9 34 E7 23 A6 | 3C F2 24 F2 | 11 CE 1A 0D
字段解析如下图:
PCM & WAV 开发实践 PCM格式转为WAV格式(基于C语言) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 int simplest_pcm16le_to_wave(const char *pcmpath,int channels,int sample_rate,const char *wavepath) { typedef struct WAVE_HEADER{ char fccID[4]; unsigned long dwSize; char fccType[4]; }WAVE_HEADER; typedef struct WAVE_FMT{ char fccID[4]; unsigned long dwSize; unsigned short wFormatTag; unsigned short wChannels; unsigned long dwSamplesPerSec; unsigned long dwAvgBytesPerSec; unsigned short wBlockAlign; unsigned short uiBitsPerSample; }WAVE_FMT; typedef struct WAVE_DATA{ char fccID[4]; unsigned long dwSize; }WAVE_DATA; if(channels==0||sample_rate==0){ channels = 2; sample_rate = 44100; } int bits = 16; WAVE_HEADER pcmHEADER; WAVE_FMT pcmFMT; WAVE_DATA pcmDATA; unsigned short m_pcmData; FILE *fp,*fpout; fp=fopen(pcmpath, "rb"); if(fp == NULL) { printf("open pcm file error\n"); return -1; } fpout=fopen(wavepath, "wb+"); if(fpout == NULL) { printf("create wav file error\n"); return -1; } //WAVE_HEADER memcpy(pcmHEADER.fccID,"RIFF",strlen("RIFF")); memcpy(pcmHEADER.fccType,"WAVE",strlen("WAVE")); fseek(fpout,sizeof(WAVE_HEADER),1); //WAVE_FMT pcmFMT.dwSamplesPerSec=sample_rate; pcmFMT.dwAvgBytesPerSec=pcmFMT.dwSamplesPerSec*sizeof(m_pcmData); pcmFMT.uiBitsPerSample=bits; memcpy(pcmFMT.fccID,"fmt ",strlen("fmt ")); pcmFMT.dwSize=16; pcmFMT.wBlockAlign=2; pcmFMT.wChannels=channels; pcmFMT.wFormatTag=1; fwrite(&pcmFMT,sizeof(WAVE_FMT),1,fpout); //WAVE_DATA; memcpy(pcmDATA.fccID,"data",strlen("data")); pcmDATA.dwSize=0; fseek(fpout,sizeof(WAVE_DATA),SEEK_CUR); fread(&m_pcmData,sizeof(unsigned short),1,fp); while(!feof(fp)){ pcmDATA.dwSize+=2; fwrite(&m_pcmData,sizeof(unsigned short),1,fpout); fread(&m_pcmData,sizeof(unsigned short),1,fp); } pcmHEADER.dwSize=44+pcmDATA.dwSize; rewind(fpout); fwrite(&pcmHEADER,sizeof(WAVE_HEADER),1,fpout); fseek(fpout,sizeof(WAVE_FMT),SEEK_CUR); fwrite(&pcmDATA,sizeof(WAVE_DATA),1,fpout); fclose(fp); fclose(fpout); return 0; }
注意:函数里声明的数据类型unsigned long在有些C编译器上是64位的,这时候要改成unsigned int才可以,否则wav头有88bytes,标准的是44bytes,改完就正常了,对C还不熟悉的人小小的心得,另外,声道数和采样率也要注意,一般采样率有44100/16000/8000,要确认是哪个,声道是1还是2,这两个参数要设置好才会有正确的转换结果。
PCM降低某个声道的音量(基于C语言) 一般来说 PCM 数据中的波形幅值越大,代表音量越大,对于 PCM 音频数据而言,它的幅值(即该采样点采样值的大小)代表音量的大小。
如果我们需要降低某个声道的音量,可以通过减小某个声道的数据的值来实现降低某个声道的音量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int pcm16le_half_volume_left( char *url ) { FILE *fp_in = fopen( url, "rb+" ); FILE *fp_out = fopen( "output_half_left.pcm", "wb+" ); unsigned char *sample = ( unsigned char * )malloc(4); // 一次读取一个sample,因为是2声道,所以是4字节 while ( !feof( fp_in ) ){ fread( sample, 1, 4, fp_in ); short* sample_num = ( short* )sample; // 转成左右声道两个short数据 *sample_num = *sample_num / 2; // 左声道数据减半 fwrite( sample, 1, 2, fp_out ); // L fwrite( sample + 2, 1, 2, fp_out ); // R } free( sample ); fclose( fp_in ); fclose( fp_out ); return 0; }
上述代码做的事情是:在读出左声道的 2 Byte 的取样值之后,将其转成了 C 语言中的一个 short 类型的变量。将该数值除以 2 之后写回到了 PCM 文件中。
分离PCM音频数据左右声道的数据 因为PCM音频数据是按照LRLRLR的方式来存储左右声道的音频数据的,所以我们可以通过将它们交叉的读出来的方式来分离左右声道的数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int simplest_pcm16le_split(char *url) { FILE *fp=fopen(url,"rb+"); FILE *fp1=fopen("output_l.pcm","wb+"); FILE *fp2=fopen("output_r.pcm","wb+"); unsigned char *sample=(unsigned char *)malloc(4); while(!feof(fp)){ fread(sample,1,4,fp); //L fwrite(sample,1,2,fp1); //R fwrite(sample+2,1,2,fp2); } free(sample); fclose(fp); fclose(fp1); fclose(fp2); return 0; }
从PCM16LE单声道音频采样数据中截取一部分数据 本程序中的函数可以从PCM16LE单声道数据中截取一段数据,并输出截取数据的样值。函数的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 /** * Cut a 16LE PCM single channel file. * @param url Location of PCM file. * @param start_num start point * @param dur_num how much point to cut */ int simplest_pcm16le_cut_singlechannel(char *url,int start_num,int dur_num){ FILE *fp=fopen(url,"rb+"); FILE *fp1=fopen("output_cut.pcm","wb+"); FILE *fp_stat=fopen("output_cut.txt","wb+"); unsigned char *sample=(unsigned char *)malloc(2); int cnt=0; while(!feof(fp)){ fread(sample,1,2,fp); if(cnt>start_num&&cnt<=(start_num+dur_num)){ fwrite(sample,1,2,fp1); short samplenum=sample[1]; samplenum=samplenum*256; samplenum=samplenum+sample[0]; fprintf(fp_stat,"%6d,",samplenum); if(cnt%10==0) fprintf(fp_stat,"\n",samplenum); } cnt++; } free(sample); fclose(fp); fclose(fp1); fclose(fp_stat); return 0; }
将PCM16LE双声道音频采样数据转换为PCM8音频采样数据 本程序中的函数可以通过计算的方式将PCM16LE双声道数据16bit的采样位数转换为8bit。函数的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 /** * Convert PCM-16 data to PCM-8 data. * @param url Location of PCM file. */ int simplest_pcm16le_to_pcm8(char *url){ FILE *fp=fopen(url,"rb+"); FILE *fp1=fopen("output_8.pcm","wb+"); int cnt=0; unsigned char *sample=(unsigned char *)malloc(4); while(!feof(fp)){ short *samplenum16=NULL; char samplenum8=0; unsigned char samplenum8_u=0; fread(sample,1,4,fp); //(-32768-32767) samplenum16=(short *)sample; samplenum8=(*samplenum16)>>8; //(0-255) samplenum8_u=samplenum8+128; //L fwrite(&samplenum8_u,1,1,fp1); samplenum16=(short *)(sample+2); samplenum8=(*samplenum16)>>8; samplenum8_u=samplenum8+128; //R fwrite(&samplenum8_u,1,1,fp1); cnt++; } printf("Sample Cnt:%d\n",cnt); free(sample); fclose(fp); fclose(fp1); return 0; }
PCM16LE格式的采样数据的取值范围是-32768到32767,而PCM8格式的采样数据的取值范围是0到255。所以PCM16LE转换到PCM8需要经过两个步骤:第一步是将-32768到32767的16bit有符号数值转换为-128到127的8bit有符号数值,第二步是将-128到127的8bit有符号数值转换为0到255的8bit无符号数值。在本程序中,16bit采样数据是通过short类型变量存储的,而8bit采样数据是通过unsigned char类型存储的。
将PCM16LE双声道音频采样数据的声音速度提高一倍 本程序中的函数可以通过抽象的方式将PCM16LE双声道数据的速度提高一倍,采用采样每个声道奇(偶)数点的样值的方式,函数的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 /** * Re-sample to double the speed of 16LE PCM file * @param url Location of PCM file. */ int simplest_pcm16le_doublespeed(char *url){ FILE *fp=fopen(url,"rb+"); FILE *fp1=fopen("output_doublespeed.pcm","wb+"); int cnt=0; unsigned char *sample=(unsigned char *)malloc(4); while(!feof(fp)){ fread(sample,1,4,fp); if(cnt%2!=0){ //L fwrite(sample,1,2,fp1); //R fwrite(sample+2,1,2,fp1); } cnt++; } printf("Sample Cnt:%d\n",cnt); free(sample); fclose(fp); fclose(fp1); return 0; }
FFmpeg FFmpeg命令行工具(一):查看媒体文件头信息工具ffprobe 简述 ffprobe是ffmpeg命令行工具中相对简单的,此命令是用来查看媒体文件格式的工具。
命令格式 在命令行中输入如下格式的命令:
使用ffprobe查看mp3格式的文件 本文使用的是歌曲《社会摇》,执行的命令为:
输出内容为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Input #0, mp3, from 'shy.mp3': Metadata: genre : Blues encoder : Lavf56.4.101 comment : 163 key(Don't modify):L64FU3W4YxX3ZFTmbZ+8/UO6KmVXLfTij3uZN/wCXE4a00XHtvOwccwFlS+8ednRD4MnrdUH+aUYZFVY8bObsrabtBM2Ps/UAWPJtsmW/3RXnn6eJcNUHrPALM0003fIpQnn6MOWbdXqog6WFDLpaZJhoPMnFy9u41HxCalUwMEc+mkHNn+nSLlioJfpv4wPBwUhxfLNmOScmXPzOary2k37A/brRx7QUlMD9rkaZ album : 社会摇 title : 社会摇 artist : 萧全 track : 1 Duration: 00:04:09.34, start: 0.025056, bitrate: 323 kb/s Stream #0:0: Audio: mp3, 44100 Hz, stereo, s16p, 320 kb/s Stream #0:1: Video: mjpeg, yuvj444p(pc, bt470bg/unknown/unknown), 500x500 [SAR 72:72 DAR 1:1], 90k tbr, 90k tbn, 90k tbc Metadata: comment : Media (e.g. label side of CD)
首先我们看以下这行信息:
1 Duration: 00:04:09.34, start: 0.025056, bitrate: 323 kb/s
这行信息表示,该视频文件的时长是4分9秒340毫秒,开始播放时间是0.025056,整个文件的比特率是256Kbit/s,然后我们看下一行信息:
1 Stream ####0:0: Audio: mp3, 44100 Hz, stereo, s16p, 320 kb/s
这行信息表示,第一个流是音频流,编码格式是MP3格式,采样率是44.1KHz,声道是立体声,采样表示格式是SInt16(short)的planner(平铺格式),这路流的比特率320Kbit/s。
使用ffprobe查看mp4格式的文件 本文使用的是视频《泡沫》,执行的命令为:
输出内容为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'pm.mp4': Metadata: major_brand : isom minor_version : 1 compatible_brands: isomavc1 creation_time : 2016-12-17T16:02:05.000000Z album : Yinyuetai artist : yinyuetai.com comment : Yinyuetai-1TR1151 date : 12/18/16 00:02:05 Duration: 00:04:33.51, start: 0.000000, bitrate: 1104 kb/s Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 960x540, 1008 kb/s, 25 fps, 25 tbr, 25k tbn, 50 tbc (default) Metadata: creation_time : 2016-12-17T16:02:05.000000Z handler_name : 264@GPAC0.5.1-DEV-rev5472 Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 92 kb/s (default) Metadata: creation_time : 2016-12-17T15:50:54.000000Z handler_name : Sound Media Handler
首先我们看以下这行信息:
1 Duration: 00:04:33.51, start: 0.000000, bitrate: 1104 kb/s
这行信息表示,该视频文件的时长是4分33秒510毫秒,开始播放时间是0,整个文件的比特率是1104Kbit/s,然后我们看下一行信息:
1 Stream ####0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 960x540, 1008 kb/s, 25 fps, 25 tbr, 25k tbn, 50 tbc (default)
这行信息表示,第一个流是视频流,编码格式是H264格式(封装格式为AVC1),每一帧的数据表示为yuv420p,分辨率为960x540,这路流的比特率为1108Kbit/s,帧率为每秒钟25帧。
接下来我们看下一行:
1 Stream ####0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 92 kb/s (default)
这行信息表示第二个流是音频流,编码方式为ACC(封装格式为MP4A),并且采用的Profile是LC规格,采样率是44.1KHz,声道是立体声,这路流的比特率92Kbit/s。
到此为止,我们就掌握了使用ffprobe提取媒体的头文件信息的方式,并了解了提取出来的信息的含义
ffprobe高级使用方式
输出格式信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 appledeMacBook-Pro:Desktop renhui$ ffprobe -show_format pm.mp4 ffprobe version 3.4.2 Copyright (c) 2007-2018 the FFmpeg developers built with Apple LLVM version 9.0.0 (clang-900.0.39.2) configuration: --prefix=/usr/local/Cellar/ffmpeg/3.4.2 --enable-shared --enable-pthreads --enable-version3 --enable-hardcoded-tables --enable-avresample --cc=clang --host-cflags= --host-ldflags= --disable-jack --enable-gpl --enable-libmp3lame --enable-libx264 --enable-libxvid --enable-opencl --enable-videotoolbox --disable-lzma libavutil 55. 78.100 / 55. 78.100 libavcodec 57.107.100 / 57.107.100 libavformat 57. 83.100 / 57. 83.100 libavdevice 57. 10.100 / 57. 10.100 libavfilter 6.107.100 / 6.107.100 libavresample 3. 7. 0 / 3. 7. 0 libswscale 4. 8.100 / 4. 8.100 libswresample 2. 9.100 / 2. 9.100 libpostproc 54. 7.100 / 54. 7.100 Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'pm.mp4': Metadata: major_brand : isom minor_version : 1 compatible_brands: isomavc1 creation_time : 2016-12-17T16:02:05.000000Z album : Yinyuetai artist : yinyuetai.com comment : Yinyuetai-1TR1151 date : 12/18/16 00:02:05 Duration: 00:04:33.51, start: 0.000000, bitrate: 1104 kb/s Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 960x540, 1008 kb/s, 25 fps, 25 tbr, 25k tbn, 50 tbc (default) Metadata: creation_time : 2016-12-17T16:02:05.000000Z handler_name : 264@GPAC0.5.1-DEV-rev5472 Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 92 kb/s (default) Metadata: creation_time : 2016-12-17T15:50:54.000000Z handler_name : Sound Media Handler [FORMAT] filename=pm.mp4 nb_streams=2 nb_programs=0 format_name=mov,mp4,m4a,3gp,3g2,mj2 format_long_name=QuickTime / MOV start_time=0.000000 duration=273.506667 size=37776599 bit_rate=1104955 probe_score=100 TAG:major_brand=isom TAG:minor_version=1 TAG:compatible_brands=isomavc1 TAG:creation_time=2016-12-17T16:02:05.000000Z TAG:album=Yinyuetai TAG:artist=yinyuetai.com TAG:comment=Yinyuetai-1TR1151 TAG:date=12/18/16 00:02:05 [/FORMAT]
输出每个流的具体信息(以JSON格式)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 appledeMacBook-Pro:Desktop renhui$ ffprobe -print_format json -show_streams pm.mp4 ffprobe version 3.4.2 Copyright (c) 2007-2018 the FFmpeg developers built with Apple LLVM version 9.0.0 (clang-900.0.39.2) configuration: --prefix=/usr/local/Cellar/ffmpeg/3.4.2 --enable-shared --enable-pthreads --enable-version3 --enable-hardcoded-tables --enable-avresample --cc=clang --host-cflags= --host-ldflags= --disable-jack --enable-gpl --enable-libmp3lame --enable-libx264 --enable-libxvid --enable-opencl --enable-videotoolbox --disable-lzma libavutil 55. 78.100 / 55. 78.100 libavcodec 57.107.100 / 57.107.100 libavformat 57. 83.100 / 57. 83.100 libavdevice 57. 10.100 / 57. 10.100 libavfilter 6.107.100 / 6.107.100 libavresample 3. 7. 0 / 3. 7. 0 libswscale 4. 8.100 / 4. 8.100 libswresample 2. 9.100 / 2. 9.100 libpostproc 54. 7.100 / 54. 7.100 { Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'pm.mp4': Metadata: major_brand : isom minor_version : 1 compatible_brands: isomavc1 creation_time : 2016-12-17T16:02:05.000000Z album : Yinyuetai artist : yinyuetai.com comment : Yinyuetai-1TR1151 date : 12/18/16 00:02:05 Duration: 00:04:33.51, start: 0.000000, bitrate: 1104 kb/s Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 960x540, 1008 kb/s, 25 fps, 25 tbr, 25k tbn, 50 tbc (default) Metadata: creation_time : 2016-12-17T16:02:05.000000Z handler_name : 264@GPAC0.5.1-DEV-rev5472 Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 92 kb/s (default) Metadata: creation_time : 2016-12-17T15:50:54.000000Z handler_name : Sound Media Handler "streams": [ { "index": 0, "codec_name": "h264", "codec_long_name": "H.264 / AVC / MPEG-4 AVC / MPEG-4 part 10", "profile": "Main", "codec_type": "video", "codec_time_base": "1/50", "codec_tag_string": "avc1", "codec_tag": "0x31637661", "width": 960, "height": 540, "coded_width": 960, "coded_height": 540, "has_b_frames": 2, "sample_aspect_ratio": "0:1", "display_aspect_ratio": "0:1", "pix_fmt": "yuv420p", "level": 31, "chroma_location": "left", "refs": 1, "is_avc": "true", "nal_length_size": "4", "r_frame_rate": "25/1", "avg_frame_rate": "25/1", "time_base": "1/25000", "start_pts": 0, "start_time": "0.000000", "duration_ts": 6835000, "duration": "273.400000", "bit_rate": "1008649", "bits_per_raw_sample": "8", "nb_frames": "6835", "disposition": { "default": 1, "dub": 0, "original": 0, "comment": 0, "lyrics": 0, "karaoke": 0, "forced": 0, "hearing_impaired": 0, "visual_impaired": 0, "clean_effects": 0, "attached_pic": 0, "timed_thumbnails": 0 }, "tags": { "creation_time": "2016-12-17T16:02:05.000000Z", "language": "und", "handler_name": "264@GPAC0.5.1-DEV-rev5472" } }, { "index": 1, "codec_name": "aac", "codec_long_name": "AAC (Advanced Audio Coding)", "profile": "LC", "codec_type": "audio", "codec_time_base": "1/44100", "codec_tag_string": "mp4a", "codec_tag": "0x6134706d", "sample_fmt": "fltp", "sample_rate": "44100", "channels": 2, "channel_layout": "stereo", "bits_per_sample": 0, "r_frame_rate": "0/0", "avg_frame_rate": "0/0", "time_base": "1/44100", "start_pts": 0, "start_time": "0.000000", "duration_ts": 12061696, "duration": "273.507846", "bit_rate": "92649", "max_bit_rate": "136240", "nb_frames": "11779", "disposition": { "default": 1, "dub": 0, "original": 0, "comment": 0, "lyrics": 0, "karaoke": 0, "forced": 0, "hearing_impaired": 0, "visual_impaired": 0, "clean_effects": 0, "attached_pic": 0, "timed_thumbnails": 0 }, "tags": { "creation_time": "2016-12-17T15:50:54.000000Z", "language": "und", "handler_name": "Sound Media Handler" } } ] }
显示帧信息
1 ffprobe -show_frames pm.mp4
查看包信息
1 ffprobe -show_packets pm.mp4
FFmpeg命令行工具(二):播放媒体文件的工具ffplay 简述 ffplay是以FFmpeg框架为基础,外加渲染音视频的库libSDL构建的媒体文件播放器。
在使用ffplay之前必须要安装到系统中,MAC的安装教程为:http://www.cnblogs.com/renhui/p/8458150.html
命令格式 在安装了在命令行中输入如下格式的命令:
主要选项 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 '-x width' 强制以 "width" 宽度显示 '-y height' 强制以 "height" 高度显示 '-an' 禁止音频 '-vn' 禁止视频 '-ss pos' 跳转到指定的位置(秒) '-t duration' 播放 "duration" 秒音/视频 '-bytes' 按字节跳转 '-nodisp' 禁止图像显示(只输出音频) '-f fmt' 强制使用 "fmt" 格式 '-window_title title' 设置窗口标题(默认为输入文件名) '-loop number' 循环播放 "number" 次(0将一直循环) '-showmode mode' 设置显示模式 可选的 mode : '0, video' 显示视频 '1, waves' 显示音频波形 '2, rdft' 显示音频频带 默认值为 'video',你可以在播放进行时,按 "w" 键在这几种模式间切换 '-i input_file' 指定输入文件
一些高级选项 1 2 3 4 5 6 7 8 '-sync type' 设置主时钟为音频、视频、或者外部。默认为音频。主时钟用来进行音视频同步 '-threads count' 设置线程个数 '-autoexit' 播放完成后自动退出 '-exitonkeydown' 任意键按下时退出 '-exitonmousedown' 任意鼠标按键按下时退出 '-acodec codec_name' 强制指定音频解码器为 "codec_name" '-vcodec codec_name' 强制指定视频解码器为 "codec_name" '-scodec codec_name' 强制指定字幕解码器为 "codec_name"
一些快捷键 1 2 3 4 5 6 7 8 9 'q, ESC' 退出 'f' 全屏 'p, SPC' 暂停 'w' 切换显示模式(视频/音频波形/音频频带) 's' 步进到下一帧 'left/right' 快退/快进 10 秒 'down/up' 快退/快进 1 分钟 'page down/page up' 跳转到前一章/下一章(如果没有章节,快退/快进 10 分钟) 'mouse click' 跳转到鼠标点击的位置(根据鼠标在显示窗口点击的位置计算百分比)
ffplay 播放音频 播放音频文件的命令:
这时候就会弹出来一个窗口,一边播放MP3文件,一边将播放音频的图画到该窗口上。针对该窗口的操作如下:
点击该窗口的任意一个位置,ffplay会按照点击的位置计算出时间的进度,然后seek到计算出来的时间点继续播放。
按下键盘的左键默认快退10s,右键默认快进10s,上键默认快进1min,下键默认快退1min。
按ESC就退出播放进程,按W会绘制音频的波形图。
ffplay 播放视频 播放视频文件的命令:
这时候,就会在新弹出的窗口上播放该视频了。
如果想要同时播放多个文件,只需在多个命令行下同时执行ffplay就可以了。
如果按s键就可以进入frame-step模式,即按s键一次就会播放下一帧图像。
ffplay 高级使用方式 循环播放 上述命令代表播放视频结束之后会从头再次播放,共循环播放10次。
播放 pm.mp4 ,播放完成后自动退出 以 320 x 240 的大小播放 test.mp4 1 ffplay -x 320 -y 240 pm.mp4
将窗口标题设置为 “myplayer”,循环播放 2 次 1 ffplay -window_title myplayer -loop 2 pm.mp4
播放 双通道 32K 的 PCM 音频数据 1 ffplay -f s16le -ar 32000 -ac 2 test.pcm
ffplay音画同步 ffplay也是一个视频播放器,所以不得不提出来的一个问题是:音画同步。ffplay的音画同步的实现方式其实有三种,分别是:以音频为主时间轴作为同步源,以视频为主时间轴作为同步源,以外部时钟为主时间轴作为同步源。
下面就以音频为主时间轴来作为同步源来作为案例进行讲解,而且ffplay默认也是以音频为基准进行对齐的,那么以音频作为对齐基准是如何实现的呢?
首先需要说明的是,播放器接收到的视频帧或者音频帧,内部都是会有时间戳(PTS时钟)来标识它实际应该在什么时刻展示,实际的对齐策略如下:比较视频当前的播放时间和音频当前的播放时间,如果视频播放过快,则通过加大延迟或者重复播放来降低视频播放速度,如果视频播放满了,则通过减小延迟或者丢帧来追赶音频播放的时间点。关键就在于音视频时间的比较和延迟的计算,当前在比较的过程中会设置一个阈值,如果超过预设的阈值就应该作出调整(丢帧或者重复渲染),这就是整个对齐策略。
在使用ffplay的时候,我们可以明确的指定使用那种对齐方式,比如:
1 ffplay pm.mp4 -sync audio
上面这个命令显式的指定了使用以音频为基准进行音视频同步的方式播放视频文件,当然这也是ffplay的默认播放设置。
1 ffplay pm.mp4 -sync video
上面这个命令显式的指定了使用以视频为基准进行音视频同步的方式播放视频文件。
上面这个命令显式的指定了使用外部时钟为基准进行音视频同步的方式播放视频文件。
大家可以分别使用这三种方式进行播放,尝试听一听,做一些快进或者seek的操作,看看不同的对齐策略对最终的播放会产生什么样的影响。
FFmpeg命令行工具(三):媒体文件转换工具ffmpeg 简述 ffmpeg是一个非常强大的工具,它可以转换任何格式的媒体文件,并且还可以用自己的AudioFilter以及VideoFilter进行处理和编辑。有了它,我们就可以对媒体文件做很多我们想做的事情了。
命令行参数 通用参数
-f fmt : 指定格式
-i filename:指定输入文件名
-y:覆盖已有文件
-t duration:指定时长
-fs limit_size:设置文件大小的上限
-ss time_off: 从指定的时间开始
-re:代表按照时间戳读取或发送数据,尤其在作为推流工具的时候一定要加上该参数,否则ffpmeg会按照最高速率向流媒体不停的发送数据。
-map:指定输出文件的流映射关系。例如:“-map 1:0 -map 1:1”要求按照第二个输入的文件的第一个流和第二个流写入输出文件。如果没有设置此项,则ffpmeg采用默认的映射关系。
视频参数
-b:指定比特率(bit/s),ffmpeg默认采用的是VBR的,若指定的该参数,则使用平均比特率。
-bitexact:使用标准比特率。
-vb:指定视频比特率(bit/s)
-r rate:帧速率(fps)
-s size:指定分辨率(320x240)
-aspect aspect:设置视频长宽比(4:3、16:9或1.33333、1.77777)
-croptop size:设置顶部切除尺寸(in pixels)
-cropleft size:设置左切除尺寸(in pixels)
-cropbottom size:设置地步切除尺寸(in pixels)
-cropright size:设置右切除尺寸(in pixels)
-padtop size:设置顶部补齐尺寸(in pixels)
-padleft size:设置左补齐尺寸(in pixels)
-padbottom size:设置地步补齐尺寸(in pixels)
-padright size:设置右补齐尺寸(in pixels)
-padcolor color:设置补齐颜色
-vn:取消视频的输出
-vcodec codec:强制使用codec编码方式
音频参数
-ab:设置比特率(bit/s),对于MP3的格式,想要听到较高品质的声音,建议设置160Kbit/s(单声道80Kbit/s)以上。
-aq quality:设置音频质量
-ar ratre:设置音频采样率(Hz)
-ac channels:设置声道数,1就是单声道,2就是立体声
-an:取消音频输出
-acodec codec:强制使用codec编码方式
-vol volume:设置录制音量大小
以上就是在日常开发中经常用到的音视频参数及通用参数。下面会针对常见的开发场景进行实践和说明。
实践学习 列出ffmpeg支持的所有格式 相关命令:
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 File formats: D. = Demuxing supported .E = Muxing supported -- D 3dostr 3DO STR E 3g2 3GP2 (3GPP2 file format) E 3gp 3GP (3GPP file format) D 4xm 4X Technologies E a64 a64 - video for Commodore 64 D aa Audible AA format files D aac raw ADTS AAC (Advanced Audio Coding) DE ac3 raw AC-3 省略...... D xbin eXtended BINary text (XBIN) D xmv Microsoft XMV D xpm_pipe piped xpm sequence D xvag Sony PS3 XVAG D xwma Microsoft xWMA D yop Psygnosis YOP DE yuv4mpegpipe YUV4MPEG pipe
剪切一段媒体文件,可以是音频或者视频文件 相关命令:
1 ffmpeg -i pm.mp4 -ss 00:00:50.0 -codec copy -t 20 output.mp4
命令说明:
表示将文件pm.mp4从第50s开始剪切20s的时间,输出到output.mp4中,其中-ss指定偏移时间(time Offset),-t指定的时长(duration)。
但是直接这样执行命令,固然我们能截取出来音视频的文件,但是当我们播放的时候,我们会发现虽然ffmepg剪切视频,很方便,但是也有很大缺陷:
(1). 剪切时间点不精确
造成这些问题的原因是ffmpeg无法seek到非关键帧上。
命令层面定位的话就是如果把-ss, -t参数放在-i参数之后,是对输出文件执行的seek操作
所以:我们优化了一下上面的那个命令,让视频的剪切更加精确:
1 ffmpeg -ss 10 -t 15 -accurate_seek -i pm.mp4 -codec copy output.mp4
注意:accurate_seek必须放在-i参数之前。
但是,可能又会有人发现,还是存在剪切不准确的现象,那是因为,上述命令只是进行了数据的转封装,会受到关键帧的影响,所以如果需要特别准确的剪切,只能使用ffmpeg进行重新编解码的操作了,命令行如下:
1 ffmpeg -i input.mp4 -ss 00:00:03.123 -t 10 -c:v libx264 -c:a aac out.mp4
此命令行相对上面的转封装的剪切来说,速度明显变慢,是因为对视频数据重新编解码了,但是精度相对转封装来说是大大提高了。
提取视频文件中的音频数据,并保存为文件 相关命令:
1 ffmpeg -i pm.mp4 -vn -acodec copy output.m4a
命令说明:
将文件pm.mp4的视频流禁用掉(参数为:-vn,如果禁用音频流参数为-an,禁用字母流参数为-sn )。
然后将pm.mp4中的音频流的数据封装到output.m4a文件中,音频流的编码格式不变。
将视频中的音频静音,只保留视频 相关命令:
1 ffmpeg -i pm.mp4 -an -vcodec copy output.mp4
命令说明:
将文件pm.mp4的音频流禁用掉(参数为:-an )。
然后将pm.mp4中的视频流的数据封装到output.mp4文件中,视频流的编码格式不变。
从mp4文件中抽取视频流导出为裸H264数据: 相关命令:
1 ffmpeg -i pm.mp4 -an -vcodec copy -bsf:v h264_mp4toannexb output.h264
命令说明:
在指令中,我们舍弃了音频数据(-an),视频数据使用mp4toannexb这个bitstreasm filter来转换为原始的H264数据。(注:同一编码也会有不同的封装格式)。
验证播放:
可以使用ffplay命令进行尝试播放,如果能播放成功,则说明生效。
将视频推送到流媒体服务器上: 1 ffmpeg -re -i pm.mp4 -acodec copy -vcodec copy -f flv rtmp://127.0.0.1/rh/mylive
命令说明:
将mp4文件的音视频数据的编码格式不变,按照rtmp的方式,将视频推送到流媒体服务器上。
将流媒体服务器上的流dump到本地: 1 ffmpeg -i rtmp://127.0.0.1/rh/mylive -acodec copy -vcodec copy -f flv test.flv
命令说明:
将流媒体服务器的数据,不进行转码,通过转封装的方式保存到本地。
给视频添加水印 1 ffmpeg -i pm.mp4 -i xxx.png -filter_complex "overlay=5:5" out.mp4
命令说明:
使用ffmpeg滤镜功能,将对mp4添加水印。
倒放音视频 1 2 3 4 5 6 7 8 // 1.视频倒放,无音频 ffmpeg.exe -i inputfile.mp4 -filter_complex [0:v]reverse[v] -map [v] -preset superfast reversed.mp4 // 2.视频倒放,音频不变 ffmpeg.exe -i inputfile.mp4 -vf reverse reversed.mp4 // 3.音频倒放,视频不变 ffmpeg.exe -i inputfile.mp4 -map 0 -c:v copy -af "areverse" reversed_audio.mp4 // 4.音视频同时倒放 ffmpeg.exe -i inputfile.mp4 -vf reverse -af areverse -preset superfast reversed.mp4
将几个MP4视频文件合并为1个视频. 实现思路:
1.先将MP4文件转化为同样编码形式的ts流(ts流支持concate)
2.第二步,连接(concate)ts流
3.最后,把连接好的ts流转化为MP4.
1 2 3 4 5 6 7 8 // 转换为ts流ffmpeg -i 0.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 0.ts ffmpeg -i 1.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 1.ts ffmpeg -i 2.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 2.ts ffmpeg -i 3.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 3.ts ffmpeg -i 4.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 4.ts ffmpeg -i 5.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 5.ts // 合并ts流为mp4 ffmpeg -i "concat:0.ts|1.ts|2.ts|3.ts|4.ts|5.ts" -acodec copy -vcodec copy -absf aac_adtstoasc FileName.mp4
FFmpeg命令行工具(四):FFmpeg 调整音视频播放速度 FFmpeg对音频、视频播放速度的调整的原理不一样。下面简单的说一下各自的原理及实现方式:
调整视频速率 调整视频速率的原理为:修改视频的pts,dts
实现:
1 ffmpeg -i input.mkv -an -filter:v "setpts=0.5*PTS" output.mkv
注意:视频调整的速度倍率范围为:[0.25, 4]
如果只调整视频的话最好把音频禁掉。
对视频进行加速时,如果不想丢帧,可以用-r 参数指定输出视频FPS,方法如下:
1 ffmpeg -i input.mkv -an -r 60 -filter:v "setpts=2.0*PTS" output.mkv
调整音频速率 调整视频速率的原理为:简单的方法是调整音频采样率,但是这种方法会改变音色, 一般采用通过对原音进行重采样,差值 等方法。
1 ffmpeg -i input.mkv -filter:a "atempo=2.0" -vn output.mkv
注意:倍率调整范围为[0.5, 2.0]
如果需要调整4倍可采用以下方法:
1 ffmpeg -i input.mkv -filter:a "atempo=2.0,atempo=2.0" -vn output.mkv
如果需要同时调整,可以采用如下的方式来实现:*
1 ffmpeg -i input.mkv -filter_complex "[0:v]setpts=0.5*PTS[v];[0:a]atempo=2.0[a]" -map "[v]" -map "[a]" output.mkv
参考文献 [http://trac.ffmpeg.org/wiki/How%20to%20speed%20up%20/%20slow%20down%20a%20video] (http://trac.ffmpeg.org/wiki/How to speed up / slow down a video)
FFmpeg(一):FFmpeg 简介 FFmpeg 介绍 FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库。
FFmpeg 组成
libavformat:用于各种音视频封装格式 的生成和解析,包括获取解码所需信息以生成解码上下文结构和读取音视频帧等功能;
libavcodec:用于各种类型声音/图像编解码;
libavutil:包含一些公共的工具函数;
libswscale:用于视频场景比例缩放、色彩映射转换;
libpostproc:用于后期效果处理;
ffmpeg:该项目提供的一个工具,可用于格式转换、解码或电视卡 即时编码等;
ffsever:一个 HTTP 多媒体即时广播串流服务器;
ffplay:是一个简单的播放器,使用ffmpeg 库解析和解码,通过SDL显示;
FFmpeg包含类库说明 类库说明
libavformat - 用于各种音视频封装格式的生成和解析,包括获取解码所需信息、读取音视频数据等功能。各种流媒体协议代码(如rtmpproto.c等)以及音视频格式的(解)复用代码(如flvdec.c、flvenc.c等)都位于该目录下。
libavcodec - 音视频各种格式的编解码。各种格式的编解码代码(如aacenc.c、aacdec.c等)都位于该目录下。
libavutil - 包含一些公共的工具函数的使用库,包括算数运算,字符操作等。
libswscale - 提供原始视频的比例缩放、色彩映射转换、图像颜色空间或格式转换的功能。
libswresample - 提供音频重采样,采样格式转换和混合等功能。
libavfilter - 各种音视频滤波器。
libpostproc - 用于后期效果处理,如图像的去块效应等。
libavdevice - 用于硬件的音视频采集、加速和显示。
如果您之前没有阅读FFmpeg代码的经验,建议优先阅读libavformat、libavcodec以及libavutil下面的代码,它们提供了音视频开发的最基本功能,应用范围也是最广的。
常用结构 FFmpeg里面最常用的数据结构,按功能可大致分为以下几类(以下代码行数,以branch: origin/release/3.4为准):
封装格式
AVFormatContext - 描述了媒体文件的构成及基本信息,是统领全局的基本结构体,贯穿程序始终,很多函数都要用它作为参数;
AVInputFormat - 解复用器对象,每种作为输入的封装格式(例如FLV、MP4、TS等)对应一个该结构体,如libavformat/flvdec.c的ff_flv_demuxer;
AVOutputFormat - 复用器对象,每种作为输出的封装格式(例如FLV, MP4、TS等)对应一个该结构体,如libavformat/flvenc.c的ff_flv_muxer;
AVStream - 用于描述一个视频/音频流的相关数据信息。
编解码
AVCodecContext - 描述编解码器上下文的数据结构,包含了众多编解码器需要的参数信息;
AVCodec - 编解码器对象,每种编解码格式(例如H.264、AAC等)对应一个该结构体,如libavcodec/aacdec.c的ff_aac_decoder。每个AVCodecContext中含有一个AVCodec;
AVCodecParameters - 编解码参数,每个AVStream中都含有一个AVCodecParameters,用来存放当前流的编解码参数。
网络协议
AVIOContext - 管理输入输出数据的结构体;
URLProtocol - 描述了音视频数据传输所使用的协议,每种传输协议(例如HTTP、RTMP)等,都会对应一个URLProtocol结构,如libavformat/http.c中的ff_http_protocol;
URLContext - 封装了协议对象及协议操作对象。
数据存放
AVPacket - 存放编码后、解码前的压缩数据,即ES数据;
AVFrame - 存放编码前、解码后的原始数据,如YUV格式的视频数据或PCM格式的音频数据等;
FFmpeg(二):Mac下安装FFmpeg 安装ffmpeg 分为两种安装方式:
命令行安装 下载压缩包安装 去 http://evermeet.cx/ffmpeg/ 下载7z压缩包,解压缩后,将ffmpeg文件拷贝到一个地方,然后在bash_profile里面配置好环境变量
安装ffplay 分为两种安装方式:
命令行安装 执行下面的命令就可以进行安装操作
1 brew install ffmpeg --with-ffplay
注:目前使用此安装方式安装后,执行ffplay会出现command not found的问题,可能是因为SDL的配置问题导致的。
下载压缩包安装 去 http://evermeet.cx/ffmpeg/ 下载7z压缩包,解压缩后,将ffplay文件拷贝到一个地方,然后在bash_profile里面配置好环境变量
附言 在上面我们接触到了命令行安装ffmpeg的方法,除了安装选项 –with-ffplay外还有更多的选项如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 –with-fdk-aac (Enable the Fraunhofer FDK AAC library) –with-ffplay (Enable FFplay media player) –with-freetype (Build with freetype support) –with-frei0r (Build with frei0r support) –with-libass (Enable ASS/SSA subtitle format) –with-libcaca (Build with libcaca support) –with-libvo-aacenc (Enable VisualOn AAC encoder) –with-libvorbis (Build with libvorbis support) –with-libvpx (Build with libvpx support) –with-opencore-amr (Build with opencore-amr support) –with-openjpeg (Enable JPEG 2000 image format) –with-openssl (Enable SSL support) –with-opus (Build with opus support) –with-rtmpdump (Enable RTMP protocol) –with-schroedinger (Enable Dirac video format) –with-speex (Build with speex support) –with-theora (Build with theora support) –with-tools (Enable additional FFmpeg tools) –without-faac (Build without faac support) –without-lame (Disable MP3 encoder) –without-x264 (Disable H.264 encoder) –without-xvid (Disable Xvid MPEG-4 video encoder) –devel (install development version 2.1.1) –HEAD (install HEAD version)
FFmpeg(三):将 FFmpeg 移植到 Android平台 首先需要去FFmpeg的官网http://www.ffmpeg.org/去下载FFmpeg的源码,目前的版本号为FFmpeg3.3(Hilbert)。
下载的文件为压缩包,解压后得到ffmpeg-3.3目录。
修改ffmpeg-3.3的configure文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 原来的配置内容: SLIBNAME_WITH_MAJOR='$(SLIBNAME).$(LIBMAJOR)' LIB_INSTALL_EXTRA_CMD='$$(RANLIB)"$(LIBDIR)/$(LIBNAME)"' SLIB_INSTALL_NAME='$(SLIBNAME_WITH_VERSION)' SLIB_INSTALL_LINKS='$(SLIBNAME_WITH_MAJOR)$(SLIBNAME)' #替换后的内容: SLIBNAME_WITH_MAJOR='$(SLIBPREF)$(FULLNAME)-$(LIBMAJOR)$(SLIBSUF)' LIB_INSTALL_EXTRA_CMD='$$(RANLIB)"$(LIBDIR)/$(LIBNAME)"' SLIB_INSTALL_NAME='$(SLIBNAME_WITH_MAJOR)' SLIB_INSTALL_LINKS='$(SLIBNAME)'
原因:如果不修改配置,直接进行编译出来的so文件类似libavcodec.so.55.39.101,文件的版本号位于so之后,这样在Android上无法加载,所以需要修改!
编写build_android.sh脚本文件:
在编译FFmpeg之前需要进行配置,设置相应的环境变量等。所有的配置选项都在ffmpeg-3.3/configure这个脚本文件中,执行如下命令可查看所有的配置选项:
$ ./configure –help
下面将配置项和环境变量设置写成一个sh脚本文件来运行以便编译出Android平台需要的so文件出来。
build_android.sh的内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #!/bin/bash NDK=/Users/renhui/framework/android-ndk-r14b SYSROOT=$NDK/platforms/android-9/arch-arm/ TOOLCHAIN=$NDK/toolchains/arm-linux-androideabi-4.9/prebuilt/darwin-x86_64 function build_one { ./configure \ --prefix=$PREFIX \ --enable-shared \ --disable-static \ --disable-doc \--enable-cross-compile \ --cross-prefix=$TOOLCHAIN/bin/arm-linux-androideabi- \ --target-os=linux \ --arch=arm \ --sysroot=$SYSROOT \ --extra-cflags="-Os -fpic $ADDI_CFLAGS" \ --extra-ldflags="$ADDI_LDFLAGS" \ $ADDITIONAL_CONFIGURE_FLAG } CPU=arm PREFIX=$(pwd)/android/$CPU ADDI_CFLAGS="-marm" build_one
需要确定的是NDK,SYSROOT和TOOLCHAIN是否是本地的环境,并确定cross-prefix指向的路径存在。
保存脚本文件后,将脚本的权限提升:
1 chmod 777 build_android.sh
然后执行脚本,该脚本会完成对ffmpeg的配置,并生成config.h等配置文件,后面的编译会用到。如果未经过配置直接进行编译会提示无法找到config.h文件等错误。
然后执行下面两个命令:
至此,会在ffmpeg-3.3目录下生成一个android目录,其/android/arm/lib目录下的so库文件就是能够在Android上运行的so库。
创建Demo工程,测试上面生成的so文件能否正常使用:
创建一个新的Android工程
在工程根目录下创建jni文件夹
在jni下创建prebuilt目录,然后:将上面编译成功的so文件放入到该目录下
创建包含native方法的类,先在src下创建cn.renhui包,然后创建FFmpegNative.java类文件。主要包括加载so库文件和一个native测试方法两部分,其内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package cn.renhui; public class FFmpegNative { static { System.loadLibrary("avutil-55"); System.loadLibrary("avcodec-57"); System.loadLibrary("swresample-2"); System.loadLibrary("avformat-57"); System.loadLibrary("swscale-4"); System.loadLibrary("avfilter-6"); System.loadLibrary("avdevice-57"); System.loadLibrary("ffmpeg_codec"); } public native int avcodec_find_decoder(int codecID); }
用javah创建.头文件: classes目录,执行:javah-jni cn.renhui.FFmpegNative,会在当前目录产生cn_renhui_FFmpegNative.h的C头文件;
根据头文件名,建立相同名字c文件cn_renhui_FFmpegNative.c,在这个源文件中实现头文件中定义的方法,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include "cn_renhui_FFmpegNative.h" #ifdef __cplusplus extern "C" { #endif JNIEXPORT jint JNICALL Java_cn_renhui_FFmpegNative_avcodec_1find_1decoder (JNIEnv *env, jobject obj, jint codecID) { AVCodec *codec = NULL; /* register all formats and codecs */ av_register_all(); codec = avcodec_find_decoder(codecID); if (codec != NULL) { return 0; } else { return -1; } } #ifdef __cplusplus } #endif
编写Android.mk,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 LOCAL_PATH := $(call my-dir) include $(CLEAR_VARS) LOCAL_MODULE := avcodec-57-prebuilt LOCAL_SRC_FILES := prebuilt/libavcodec-57.so include $(PREBUILT_SHARED_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := avdevice-57-prebuilt LOCAL_SRC_FILES := prebuilt/libavdevice-57.so include $(PREBUILT_SHARED_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := avfilter-6-prebuilt LOCAL_SRC_FILES := prebuilt/libavfilter-6.so include $(PREBUILT_SHARED_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := avformat-57-prebuilt LOCAL_SRC_FILES := prebuilt/libavformat-57.so include $(PREBUILT_SHARED_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := avutil-55-prebuilt LOCAL_SRC_FILES := prebuilt/libavutil-55.so include $(PREBUILT_SHARED_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := avswresample-2-prebuilt LOCAL_SRC_FILES := prebuilt/libswresample-2.so include $(PREBUILT_SHARED_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := swscale-4-prebuilt LOCAL_SRC_FILES := prebuilt/libswscale-4.so include $(PREBUILT_SHARED_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := ffmpeg_codec LOCAL_SRC_FILES := cn_dennishucd_FFmpegNative.c LOCAL_LDLIBS := -llog -ljnigraphics -lz -landroid LOCAL_SHARED_LIBRARIES := avcodec-57-prebuilt avdevice-57-prebuilt avfilter-6-prebuilt avformat-57-prebuilt avutil-55-prebuilt include $(BUILD_SHARED_LIBRARY)
编译so文件,执行ndk-build
新建一个Activity,进行测试,测试核心代码:
1 2 3 4 5 6 7 8 9 10 11 FFmpegNative ffmpeg = new FFmpegNative(); int codecID = 28; int res = ffmpeg.avcodec_find_decoder(codecID); if (res == 0) { tv.setText("Success!"); } else { tv.setText("Failed!"); }
28是H264的编解码ID,可以在ffmpeg的源代码中找到,它是枚举类型定义的。在C语言中,可以换算为整型值。这里测试能否找到H264编解码,如果能找到,说明调用ffmpeg的库函数是成功的,这也表明我们编译的so文件是基本可用。
FFmpeg(四):FFmpeg API 介绍与通用 API 分析 FFmpeg 编解码流程 FFmpeg编解码流程图如下,此图包含了整体的解封装、编解码的基本流程。
下面我们要介绍的术语及相关API都是围绕这个流程图展开的。
FFmpeg 相关术语 1. 容器/文件(Container/File) :即特定格式的多媒体文件,比如MP4,flv,mov等。
2. 媒体流(Stream) :表示在时间轴上的一段连续的数据,比如一段声音数据、一段视频数据或者一段字母数据,可以是压缩的,也可以是非压缩的,压缩的数据需要关联特定的编解码器。
3. 数据帧/数据包(Frame/Packet) :通常一个媒体流是由大量的数据帧组成的,对于压缩数据,帧对应着编解码器的最小处理单元,分属于不同媒体流的数据帧交错存储与容器之中。
4. 编解码器 :编解码器是以帧为单位实现压缩数据和原始数据之间的相互转换的。
前面介绍的术语,就是FFmpeg中抽象出来的概念。其中:
1. AVFormatContext :就是对容器或者媒体文件层次的抽象。
2. AVStream :在文件中(容器里面)包含了多路流(音频流、视频流、字幕流),AVStream 就是对流的抽象。
3. AVCodecContext 与 AVCodec :在每一路流中都会描述这路流的编码格式,对编解码器格式以及编解码器的抽象就是AVCodecContext 与 AVCodec。
4. AVPacket 与 AVFrame :对于编码器或者解码器的输入输出部分,也就是压缩数据以及原始数据的抽象就是AVPacket与AVFrame。
5. AVFilte r:除了编解码之外,对音视频的处理肯定是针对于原始数据的处理,也就是针对AVFrame的处理,使用的就是AVFilter。
FFmpeg 通用 API 分析 av_register_all 分析 在最开始编译FFmpeg的时候,我们做了一个configure的配置,其中开启或者关闭了很多选项。configure的配置会生成两个文件:config.mk和config.h。
config.mk:就是makefile文件需要包含进去的子模块,会作用在编译阶段,帮助开发者编译出正确的库。
config.h:作用在运行阶段,主要是确定需要注册那些容器及编解码格式到FFmpeg框架中。
调用 av_register_all 就可以注册config.h里面开发的编解码器,然后会注册所有的Muxer和Demuxer(封装格式),最后注册所有的Protocol(协议)。
这样在configure时开启或者关闭的选项就作用到了运行时,该函数的源码分析设计的源码文件包括:url.c、allformats.c、mux.c、format.c 等文件。已经将这几个源码文件单独提出来了,并放在百度网盘上了,地址:https://pan.baidu.com/s/1p8-ish6oeRTaUs84juQtHg。
av_find_codec 分析 这个方法包含了两部分的内容:一部分是寻找解码器,一部分是寻找编码器。其实在av_register_all的函数执行时,就已经把编码器和解码器都存放到一个链表中了。这里寻找编解码器就是从上一步构造的链表中遍历,通过Codec的ID或者name进行条件匹配,最终返回对于的Codec。
avcodec_open2 分析 该函数是打开编解码器(Codec)的函数,无论是编码过程还是解码过程,都会用到这个函数。该函数的输入参数有三个:第一个是AVCodecContext,解码过程由FFmpeg引擎填充,编码过程由开发者自己构造,如果想传入私有参数,则为它的priv_data设置参数;第二个参数是上一步通过av_find_codec寻找出来的编解码器(Codec);第三个参数一般传NULL。
avcodec_close 分析 如果理解了avcodec_open,那么对应的close就是一个逆过程,找到对应的实现文件中的close函数指针所只指向的函数,然后该函数会调用对应第三方库的API来关闭掉对应的编码库。
总结 本文主要是讲述了FFmpeg的相关术语,并讲解了一下通用的API的分析,不难看出其实FFmpeg所做的事情就是透明化所有的编解码库,用自己的封装来为开发者提供统一的接口。开发者使用不同的编码库时,只需要指明要用哪一个即可,这也充分体现了面向对象编程中的封装特性
FFmpeg(五):FFmpeg 编解码 API 分析 在上一篇文章 FFmpeg(四):FFmpeg API 介绍与通用 API 分析 中,我们简单的讲解了一下FFmpeg 的API基本概念,并分析了一下通用API,本文我们将分析 FFmpeg 在编解码时使用的API。
FFmpeg 解码 API 分析 函数 avformat_open_input 会根据所提供的文件路径判断文件的格式,其实就是通过这一步来决定到底是使用哪个Demuxer。
举个例子:如果是flv,那么Demuxer就会使用对应的ff_flv_demuxer,所以对应的关键生命周期的方法read_header、read_packet、read_seek、read_close都会使用该flv的Demuxer中函数指针指定的函数。read_header会将AVStream结构体构造好,以方便后续的步骤继续使用AVStream作为输入参数。
该方法的作用就是把所有的Stream的MetaData信息填充好。方法内部会先查找对于的解码器,然后打开对应的解码器,紧接着会利用Demuxer中的read_packet函数读取一段数据进行解码,当然,解码的数据越多,分析出来的流信息就越准确,如果是本地资源,那么很快就可以得到准确的信息了。但是对于网络资源来说,则会比较慢,因此该函数有几个参数可以控制读取数据的长度,一个是probe size,一个是max_analyze_duration, 还有一个就是fps_probe_size,这三个参数共同控制解码数据的长度,如果配置的这几个参数的数值越小,那么这个函数执行的时间就会越快,但会导致AVStream结构体里面的信息(视频的宽、高、fps、编码类型)不准确。
av_read_frame 分析 该方法读取出来的数据是AVPacket,在FFmpeg的早期版本中开发给开发者的函数其实就是av_read_packet,但是需要开发者自己来处理AVPacket中的数据不能被解码器处理完的情况,即需要把未处理完的压缩数据缓存起来的问题。所以在新版本的FFmpeg中,提供了该函数,用于处理此状况。 该函数的实现首先会委托到Demuxer的read_packet方法中,当然read_packet通过解服用层和协议层的处理后,会将数据返回到这里,在该函数中进行数据缓冲处理。
对于音频流,一个AVPacket可能会包含多个AVFrame,但是对于一个视频流,一个AVPacket只包含一个AVFrame,该函数最终只会返回一个AVPacket结构体。
avcodec_decode分析 该方法包含了两部分内容:一部分是解码视频,一部分是解码音频。在上面的函数分析中,我们知道,解码是会委托给对应的解码器来实施的,在打开解码器的时候就找到了对应的解码器的实现,比如对于解码H264来讲,会找到ff_h264_decoder,其中会有对应的生命周期函数的实现,最重要的就是init,decode,close三个方法,分别对应于打开解码器、解码及关闭解码器的操作,而解码过程就是调用decode方法。
该函数负责释放对应的资源,首先会调用对应的Demuxer中的生命周期read_close方法,然后释放掉,AVFormatContext,最后关闭文件或者远程网络链接。
FFmpeg 编码 API 分析 avformat_alloc_output_context2 分析 该函数内部需要调用方法avformat_alloc_context来分配一个AVFormatContext结构体,当然最关键的还是根据上一步注册的Muxer和Demuxer部分(也就是封装格式部分)去找对应的格式。有可能是flv格式、MP4格式、mov格式,甚至是MP3格式等,如果找不到对应的格式(应该是因为在configure选项中没有打开这个格式的开关),那么这里会返回找不到对于的格式的错误提示。在调用API的时候,可以使用av_err2str把返回的整数类型的错误代码转换为肉眼可读的字符串,这是个在调试中非常有用的工具函数。该函数最终会将找出来的格式赋值给AVFormatContext类型的oformat。
avio_open2 分析 首先会调用函数ffurl_open,构造出URLContext结构体,这个结构体中包含了URLProtocol(需要去第一步register_protocol中已经注册的协议链表)中去寻找;接着会调用avio_alloc_contex方法,分配出AVIOContext结构体,并将上一步构造出来的URLProtocol传递进来;然后把上一步分配出来的AVIOContext结构体赋值给AVFormatContext属性。
下面就是针对上面的描述总结的结构之间的构架图,各位可以参考此图进行进一步的理解:
avio_open2的过程也恰好是在上面我们分析avformat_open_input过程的一个逆过程。编码过程和解码过程从逻辑上来讲,也是一个逆过程,所以在FFmpeg实现的过程中,他们也互为逆过程。
编码其他API(步骤)分析 编码的其他步骤也是解码的一个逆过程,解码过程中的avformat_find_stream_info对应到编码就是avformat_new_stream和avformat_write_header。
avformat_new_stream函数会将音频流或者视频流的信息填充好,分配出AVStream结构体,在音频流中分配声道、采样率、表示格式、编码器等信息,在视频中分配宽、高、帧率、表示格式、编码器等信息。
avformat_write_header函数与解码过程中的read_header恰好是一个逆过程,这里就不多赘述了。
接下来就是编码阶段了:
将手动封装好的AVFrame结构体,作为avcodec_encodec_video方法的输入,然后将其编码成为AVPacket,然后调用av_write_frame方法输出到媒体文件中。
av_write_frame 方法会将编码后的AVPacket结构体作为Muxer中的write_packet生命周期方法的输入,write_packet会加上自己封装格式的头信息,然后调用协议层,写到本地文件或者网络服务器上。
最后一步就是av_write_trailer(该函数有一个非常大的坑,如果没执行write_header操作,就直接执行write_trailer操作,程序会直接Carsh掉,所以这两个函数必须成对出现),av_write_trailer会把没有输出的AVPacket全部丢给协议层去做输出,然后会调用Muxer的write_trailer生命周期方法(不同的格式,写出的尾部也不一样)。
FFmpeg 解码 API 超时设置 当视频流地址能打开,但是视频流中并没有流内容的时候,可能会导致整体执行流程阻塞在 avformat_open_input 或者 av_read_frame 方法上。
主要原因就是avformat_open_input 和av_read_frame 这两个方法是阻塞的。
av_read_frame() -> read_frame_internal() -> ff_read_packet() -> s->iformat->read_packet() -> read_from_url() -> ffurl_read() -> retry_transfer_wrapper() (此方法会堵塞)
虽然我们可以通过设置 ic->flags |= AVFMT_FLAG_NONBLOCK; 将操作设置为非阻塞,但这样设置是不推荐的,会导致后续的其他操作出现问题。
一般情况下,我们推荐另外两种机制进行设置:
设置开流的超时时间 在设置开流超时时间的时候,需要注意 不同的协议设置的方式是不一样的。
12方法: timeout –> 单位:(http:ms udp:s)
设置udp、http 超时的示例代码如下:
1 2 3 AVDictionary* opts = NULL; av_dict_set(&opts, "timeout", "3000000", 0);//单位 如果是http:ms 如果是udp:s int ret = avformat_open_input(&ctx, url, NULL, &opts);
设置rtsp超时的示例代码如下:
1 2 3 4 AVDictionary* opts = NULL; av_dict_set(&opts, "rtsp_transport", m_bTcp ? "tcp" : "udp", 0); //设置tcp or udp,默认一般优先tcp再尝试udp av_dict_set(&opts, "stimeout", "3000000", 0);//单位us 也就是这里设置的是3s ret = avformat_open_input(&ctx, url, NULL, &opts);
设置interrupt_callback定义返回机制 设置回调,监控read超时情况,回调方法为:
1 2 3 4 5 6 7 8 9 10 int64_t lastReadPacktTime; static int interrupt_cb(void *ctx) { int timeout = 3; if (av_gettime() - lastReadPacktTime > timeout * 1000 * 1000) { return -1; } return 0; }
回调函数中返回0则代表ffmpeg继续阻塞直到ffmpeg正常工作为止,否则就代表ffmpeg结束阻塞可以将操纵权交给用户线程并返回错误码。
对指定的 AVFormatContext 进行设置,并在需要调用的设置的时间之前,记录当前的时间,这样在回调的时候就能根据时间差,判断执行相应的逻辑:
avformat_open_input 设置方式:
1 2 3 4 inputContext = avformat_alloc_context(); lastReadPacktTime = av_gettime(); inputContext->interrupt_callback.callback = interrupt_cb; int ret = avformat_open_input(&inputContext, inputUrl.c_str(), nullptr, nullptr);
av_read_frame 设置方式:
1 2 lastReadPacktTime = av_gettime(); ret = av_read_frame(inputContext, packet);
在实际开发中,只是设计这个机制,很容易出现超时,但如果超时时间设置过程,又容易阻塞线程。一般推荐的方案为:在超时的机制上增加连续读流的时长统计,当连续读流超时超过一定时间时就通知当前读流操作已失败。
libavformat的主要组成与层次调用关系如下图:
AVFromatContext是API层直接接触到的结构体,它会进行格式的封装和解封装,它的数据部分由底层提供,底层使用了AVIOContext,这个AVIOContext实际上就是为普通的I/O增加了一层Buffer缓冲区,再往底层就是URLContext,也就是达到了协议层,协议层的实现由很多,如rtmp、http、hls、file等,这个就是libavformat的内部封装结构了。
libavcodec介绍 libavcodec模块的主要组成和数据结构图如下:
对于开发者来说,这个模块我们能接触到的最顶层的数据结构就是AVCodecContext,该结构体包含的就是与实际的编解码有关的部分。
首先AVCodecContext是包含在一个AVStream里面的,即描述了这路流的编码格式是什么,然后利用该编码器或者解码器进行AVPacket与AVFrame之间的转换(实际上就是编码或者解码的过程),这是FFmpeg中最重要的一部分。
FFmpeg 结构体(一): AVFormatContext 分析 在 FFmpeg (六):FFmpeg 核心模块 libavformat 与 libavcodec 分析 中,我们分析了FFmpeg中最重要的两个模块以及重要的结构体之间的关系。
后面的文章,我们先不去继续了解其他模块,先针对在之前的学习中接触到的结构体进行分析,然后在根据功能源码,继续了解FFmpeg。
AVFormatContext是包含码流参数较多的结构体。本文将会详细分析一下该结构体里每个变量的含义和作用。
源码整理 首先我们先看一下结构体AVFormatContext的定义的结构体源码(位于libavformat/avformat.h,本人已经将相关注释翻译成中文,方便大家理解):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 typedef struct AVFormatContext { const AVClass *av_class; struct AVInputFormat *iformat; struct AVOutputFormat *oformat; void *priv_data; AVIOContext *pb; int ctx_flags; unsigned int nb_streams; AVStream **streams; #if FF_API_FORMAT_FILENAME attribute_deprecated char filename[1024 ]; #endif char *url; int64_t start_time; int64_t duration; int64_t bit_rate; unsigned int packet_size; int max_delay; int flags; #define AVFMT_FLAG_* 0x**** int64_t probesize; int64_t max_analyze_duration; const uint8_t *key; int keylen; unsigned int nb_programs; AVProgram **programs; enum AVCodecID video_codec_id; enum AVCodecID audio_codec_id; enum AVCodecID subtitle_codec_id; unsigned int max_index_size; unsigned int max_picture_buffer; unsigned int nb_chapters; AVChapter **chapters; AVDictionary *metadata; int64_t start_time_realtime; int fps_probe_size; int error_recognition; AVIOInterruptCB interrupt_callback; int debug; #define FF_FDEBUG_TS 0x0001 int64_t max_interleave_delta; int strict_std_compliance; int event_flags; #define AVFMT_EVENT_FLAG_METADATA_UPDATED 0x0001 int max_ts_probe; int avoid_negative_ts; #define AVFMT_AVOID_NEG_TS_* int ts_id; int audio_preload; int max_chunk_duration; int max_chunk_size; int use_wallclock_as_timestamps; int avio_flags; enum AVDurationEstimationMethod duration_estimation_method; int64_t skip_initial_bytes; unsigned int correct_ts_overflow; int seek2any; int flush_packets; int probe_score; int format_probesize; char *codec_whitelist; char *format_whitelist; ....... AVCodec *video_codec; AVCodec *audio_codec; AVCodec *subtitle_codec; AVCodec *data_codec; int metadata_header_padding; void *opaque; av_format_control_message control_message_cb; int64_t output_ts_offset; uint8_t *dump_separator; enum AVCodecID data_codec_id; #if FF_API_OLD_OPEN_CALLBACKS attribute_deprecated int (*open_cb) (struct AVFormatContext *s, AVIOContext **p, const char *url, int flags, const AVIOInterruptCB *int_cb, AVDictionary **options) ; #endif char *protocol_whitelist; int (*io_open)(struct AVFormatContext *s, AVIOContext **pb, const char *url, int flags, AVDictionary **options); void (*io_close)(struct AVFormatContext *s, AVIOContext *pb); char *protocol_blacklist; int max_streams; } AVFormatContext;
AVForamtContext 重点字段 在使用FFMPEG进行开发的时候,AVFormatContext是一个贯穿始终的数据结构,很多函数都要用到它作为参数。它是FFMPEG解封装(flv,mp4,rmvb,avi)功能的结构体。下面看几个主要变量的作用(在这里考虑解码的情况):
1 2 3 4 5 6 7 8 struct AVInputFormat *iformat:输入数据的封装格式 AVIOContext *pb:输入数据的缓存 unsigned int nb_streams:视音频流的个数 AVStream **streams:视音频流 char filename[1024]:文件名 int64_t duration:时长(单位:微秒us,转换为秒需要除以1000000) int bit_rate:比特率(单位bps,转换为kbps需要除以1000) AVDictionary *metadata:元数据
视频的时长可以转换成HH:MM:SS的形式,示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 AVFormatContext *pFormatCtx; CString timelong; ... //duration是以微秒为单位 //转换成hh:mm:ss形式 int tns, thh, tmm, tss; tns = (pFormatCtx->duration)/1000000; thh = tns / 3600; tmm = (tns % 3600) / 60; tss = (tns % 60); timelong.Format("%02d:%02d:%02d",thh,tmm,tss);
视频的原数据(metadata)信息可以通过AVDictionary获取。元数据存储在AVDictionaryEntry结构体中,如下所示:
1 2 3 4 typedef struct AVDictionaryEntry { char *key; char *value; } AVDictionaryEntry;
每一条元数据分为key和value两个属性。
在ffmpeg中通过av_dict_get()函数获得视频的原数据。
下列代码显示了获取元数据并存入meta字符串变量的过程,注意每一条key和value之间有一个”\t:”,value之后有一个”\r\n”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 //MetaData------------------------------------------------------------ //从AVDictionary获得 //需要用到AVDictionaryEntry对象 //CString author,copyright,description; CString meta=NULL,key,value; AVDictionaryEntry *m = NULL; //不用一个一个找出来 /* m=av_dict_get(pFormatCtx->metadata,"author",m,0); author.Format("作者:%s",m->value); m=av_dict_get(pFormatCtx->metadata,"copyright",m,0); copyright.Format("版权:%s",m->value); m=av_dict_get(pFormatCtx->metadata,"description",m,0); description.Format("描述:%s",m->value); */ //使用循环读出 //(需要读取的数据,字段名称,前一条字段(循环时使用),参数) while(m=av_dict_get(pFormatCtx->metadata,"",m,AV_DICT_IGNORE_SUFFIX)){ key.Format(m->key); value.Format(m->value); meta+=key+"\t:"+value+"\r\n" ; }
FFmpeg 结构体(二): AVStream 分析 在上文FFmpeg 结构体(一): AVFormatContext 分析 我们学习了AVFormatContext结构体的相关内容。本文,我们将讲述一下AVStream。
AVStream是存储每一个视频/音频流信息的结构体。下面我们来分析一下该结构体里重要变量的含义和作用。
源码整理 首先我们先看一下结构体AVStream的定义的结构体源码(位于libavformat/avformat.h):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 typedef struct AVStream { int index; int id; AVCodecContext *codec; AVRational r_frame_rate; void *priv_data; struct AVFrac pts; AVRational time_base; int64_t start_time; int64_t duration; int64_t nb_frames; int disposition; enum AVDiscard discard; AVRational sample_aspect_ratio; AVDictionary *metadata; AVRational avg_frame_rate; AVPacket attached_pic; #define MAX_STD_TIMEBASES (60 *12 +5 ) struct { int64_t last_dts; int64_t duration_gcd; int duration_count; double duration_error[2 ][2 ][MAX_STD_TIMEBASES]; int64_t codec_info_duration; int nb_decoded_frames; int found_decoder; } *info; int pts_wrap_bits; int64_t reference_dts; int64_t first_dts; int64_t cur_dts; int64_t last_IP_pts; int last_IP_duration; #define MAX_PROBE_PACKETS 2500 int probe_packets; int codec_info_nb_frames; int stream_identifier; int64_t interleaver_chunk_size; int64_t interleaver_chunk_duration; enum AVStreamParseType need_parsing; struct AVCodecParserContext *parser; struct AVPacketList *last_in_packet_buffer; AVProbeData probe_data; #define MAX_REORDER_DELAY 16 int64_t pts_buffer[MAX_REORDER_DELAY+1 ]; AVIndexEntry *index_entries; int nb_index_entries; unsigned int index_entries_allocated_size; int request_probe; } AVStream;
AVStream 重点字段 1 2 3 4 5 6 7 8 9 10 11 12 13 int index:标识该视频/音频流 AVCodecContext *codec:指向该视频/音频流的AVCodecContext(它们是一一对应的关系) AVRational time_base:时基。通过该值可以把PTS,DTS转化为真正的时间。FFMPEG其他结构体中也有这个字段,但是根据我的经验,只有AVStream中的time_base是可用的。PTS*time_base=真正的时间 int64_t duration:该视频/音频流长度 AVDictionary *metadata:元数据信息 AVRational avg_frame_rate:帧率(注:对视频来说,这个挺重要的) AVPacket attached_pic:附带的图片。比如说一些MP3,AAC音频文件附带的专辑封面。
FFmpeg 结构体(三): AVPacket 分析 在上文FFmpeg 结构体(二): AVStream 分析 我们学习了AVStream结构体的相关内容。本文,我们将讲述一下AVPacket。
AVPacket是存储压缩编码数据相关信息的结构体。下面我们来分析一下该结构体里重要变量的含义和作用。
源码整理 首先我们先看一下结构体AVPacket的定义的结构体源码(位于libavcodec/avcodec.h):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 typedef struct AVPacket { /** * Presentation timestamp in AVStream->time_base units; the time at which * the decompressed packet will be presented to the user. * Can be AV_NOPTS_VALUE if it is not stored in the file. * pts MUST be larger or equal to dts as presentation cannot happen before * decompression, unless one wants to view hex dumps. Some formats misuse * the terms dts and pts/cts to mean something different. Such timestamps * must be converted to true pts/dts before they are stored in AVPacket. */ int64_t pts; /** * Decompression timestamp in AVStream->time_base units; the time at which * the packet is decompressed. * Can be AV_NOPTS_VALUE if it is not stored in the file. */ int64_t dts; uint8_t *data; int size; int stream_index; /** * A combination of AV_PKT_FLAG values */ int flags; /** * Additional packet data that can be provided by the container. * Packet can contain several types of side information. */ struct { uint8_t *data; int size; enum AVPacketSideDataType type; } *side_data; int side_data_elems; /** * Duration of this packet in AVStream->time_base units, 0 if unknown. * Equals next_pts - this_pts in presentation order. */ int duration; void (*destruct)(struct AVPacket *); void *priv; int64_t pos; ///< byte position in stream, -1 if unknown /** * Time difference in AVStream->time_base units from the pts of this * packet to the point at which the output from the decoder has converged * independent from the availability of previous frames. That is, the * frames are virtually identical no matter if decoding started from * the very first frame or from this keyframe. * Is AV_NOPTS_VALUE if unknown. * This field is not the display duration of the current packet. * This field has no meaning if the packet does not have AV_PKT_FLAG_KEY * set. * * The purpose of this field is to allow seeking in streams that have no * keyframes in the conventional sense. It corresponds to the * recovery point SEI in H.264 and match_time_delta in NUT. It is also * essential for some types of subtitle streams to ensure that all * subtitles are correctly displayed after seeking. */ int64_t convergence_duration; } AVPacket;
AVPacket 重点字段 1 2 3 4 5 6 7 8 9 uint8_t *data:压缩编码的数据。 int size:data的大小 int64_t pts:显示时间戳 int64_t dts:解码时间戳 int stream_index:标识该AVPacket所属的视频/音频流。
针对data做一下说明:对于H.264格式来说,在使用FFMPEG进行视音频处理的时候,我们常常可以将得到的AVPacket的data数据直接写成文件,从而得到视音频的码流文件。
FFmpeg 结构体(四): AVFrame 分析 在上文FFmpeg 结构体(三): AVPacket 分析 我们学习了AVPacket结构体的相关内容。本文,我们将讲述一下AVFrame。
AVFrame是包含码流参数较多的结构体。下面我们来分析一下该结构体里重要变量的含义和作用。
源码整理 首先我们先看一下结构体AVFrame的定义的结构体源码(位于libavcodec/avcodec.h):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 typedef struct AVFrame { #define AV_NUM_DATA_POINTERS 8 uint8_t *data[AV_NUM_DATA_POINTERS]; int linesize[AV_NUM_DATA_POINTERS]; uint8_t **extended_data; int width, height; int nb_samples; int format; int key_frame; enum AVPictureType pict_type; uint8_t *base[AV_NUM_DATA_POINTERS]; AVRational sample_aspect_ratio; int64_t pts; int64_t pkt_pts; int64_t pkt_dts; int coded_picture_number; int display_picture_number; int quality; int reference; int8_t *qscale_table; int qstride; int qscale_type; uint8_t *mbskip_table; int16_t (*motion_val[2 ])[2 ]; uint32_t *mb_type; short *dct_coeff; int8_t *ref_index[2 ]; void *opaque; uint64_t error[AV_NUM_DATA_POINTERS]; int type; int repeat_pict; int interlaced_frame; int top_field_first; int palette_has_changed; int buffer_hints; AVPanScan *pan_scan; int64_t reordered_opaque; void *hwaccel_picture_private; struct AVCodecContext *owner; void *thread_opaque; uint8_t motion_subsample_log2; int sample_rate; uint64_t channel_layout; int64_t best_effort_timestamp; int64_t pkt_pos; int64_t pkt_duration; AVDictionary *metadata; int decode_error_flags; #define FF_DECODE_ERROR_INVALID_BITSTREAM 1 #define FF_DECODE_ERROR_MISSING_REFERENCE 2 int64_t channels; } AVFrame;
AVFrame 重点字段 AVFrame结构体一般用于存储原始数据(即非压缩数据,例如对视频来说是YUV,RGB,对音频来说是PCM),此外还包含了一些相关的信息。比如说,解码的时候存储了宏块类型表,QP表,运动矢量表等数据。编码的时候也存储了相关的数据。因此在使用FFMPEG进行码流分析的时候,AVFrame是一个很重要的结构体。
下面看几个主要变量的作用(在这里考虑解码的情况):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 uint8_t *data[AV_NUM_DATA_POINTERS]:解码后原始数据(对视频来说是YUV,RGB,对音频来说是PCM) int linesize[AV_NUM_DATA_POINTERS]:data中“一行”数据的大小。注意:未必等于图像的宽,一般大于图像的宽。 int width, height:视频帧宽和高(1920x1080,1280x720...) int nb_samples:音频的一个AVFrame中可能包含多个音频帧,在此标记包含了几个 int format:解码后原始数据类型(YUV420,YUV422,RGB24...) int key_frame:是否是关键帧 enum AVPictureType pict_type:帧类型(I,B,P...) AVRational sample_aspect_ratio:宽高比(16:9,4:3...) int64_t pts:显示时间戳 int coded_picture_number:编码帧序号 int display_picture_number:显示帧序号 int8_t *qscale_table:QP表 uint8_t *mbskip_table:跳过宏块表 int16_t (*motion_val[2])[2]:运动矢量表 uint32_t *mb_type:宏块类型表 short *dct_coeff:DCT系数,这个没有提取过 int8_t *ref_index[2]:运动估计参考帧列表(貌似H.264这种比较新的标准才会涉及到多参考帧) int interlaced_frame:是否是隔行扫描 uint8_t motion_subsample_log2:一个宏块中的运动矢量采样个数,取log的
其他的变量不再一一列举,源代码中都有详细的说明。在这里重点分析一下几个需要一定的理解的变量:
data[] 对于packed格式的数据(例如RGB24),会存到data[0]里面。
对于planar格式的数据(例如YUV420P),则会分开成data[0],data[1],data[2]…(YUV420P中data[0]存Y,data[1]存U,data[2]存V)
pict_type 包含以下类型:
1 2 3 4 5 6 7 8 9 10 enum AVPictureType { AV_PICTURE_TYPE_NONE = 0, ///< Undefined AV_PICTURE_TYPE_I, ///< Intra AV_PICTURE_TYPE_P, ///< Predicted AV_PICTURE_TYPE_B, ///< Bi-dir predicted AV_PICTURE_TYPE_S, ///< S(GMC)-VOP MPEG4 AV_PICTURE_TYPE_SI, ///< Switching Intra AV_PICTURE_TYPE_SP, ///< Switching Predicted AV_PICTURE_TYPE_BI, ///< BI type };
sample_aspect_ratio 宽高比是一个分数,FFMPEG中用AVRational表达分数:
1 2 3 4 5 6 7 /** * rational number numerator/denominator */ typedef struct AVRational{ int num; ///< numerator int den; ///< denominator } AVRational;
qscale_table QP表指向一块内存,里面存储的是每个宏块的QP值。宏块的标号是从左往右,一行一行的来的。每个宏块对应1个QP。
qscale_table[0]就是第1行第1列宏块的QP值;qscale_table[1]就是第1行第2列宏块的QP值;qscale_table[2]就是第1行第3列宏块的QP值。以此类推…
宏块的个数用下式计算:
注:宏块大小是16x16的。
每行宏块数:
1 int mb_stride = pCodecCtx->width/16+1
宏块的总数:
1 int mb_sum = ((pCodecCtx->height+15)>>4)*(pCodecCtx->width/16+1)
FFmpeg 结构体(五): AVCodec 分析 在上文FFmpeg 结构体(四): AVFrame 分析 我们学习了AVFrame结构体的相关内容。本文,我们将讲述一下AVCodec。
AVCodec是存储编解码器信息的结构体。下面我们来分析一下该结构体里重要变量的含义和作用。
源码整理 首先我们先看一下结构体AVCodec的定义的结构体源码(位于libavcodec/avcodec.h):
View Code
AVCodec 重点字段 下面说一下最主要的几个变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 const char *name:编解码器的名字,比较短 const char *long_name:编解码器的名字,全称,比较长 enum AVMediaType type:指明了类型,是视频,音频,还是字幕 enum AVCodecID id:ID,不重复 const AVRational *supported_framerates:支持的帧率(仅视频) const enum AVPixelFormat *pix_fmts:支持的像素格式(仅视频) const int *supported_samplerates:支持的采样率(仅音频) const enum AVSampleFormat *sample_fmts:支持的采样格式(仅音频) const uint64_t *channel_layouts:支持的声道数(仅音频) int priv_data_size:私有数据的大小
详细介绍几个变量:
AVMediaType定义如下:
1 2 3 4 5 6 7 8 9 enum AVMediaType { AVMEDIA_TYPE_UNKNOWN = -1, ///< Usually treated as AVMEDIA_TYPE_DATA AVMEDIA_TYPE_VIDEO, AVMEDIA_TYPE_AUDIO, AVMEDIA_TYPE_DATA, ///< Opaque data information usually continuous AVMEDIA_TYPE_SUBTITLE, AVMEDIA_TYPE_ATTACHMENT, ///< Opaque data information usually sparse AVMEDIA_TYPE_NB };
enum AVCodecID id AVCodecID定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 enum AVCodecID { AV_CODEC_ID_NONE, /* video codecs */ AV_CODEC_ID_MPEG1VIDEO, AV_CODEC_ID_MPEG2VIDEO, ///< preferred ID for MPEG-1/2 video decoding AV_CODEC_ID_MPEG2VIDEO_XVMC, AV_CODEC_ID_H261, AV_CODEC_ID_H263, AV_CODEC_ID_RV10, AV_CODEC_ID_RV20, AV_CODEC_ID_MJPEG, AV_CODEC_ID_MJPEGB, AV_CODEC_ID_LJPEG, AV_CODEC_ID_SP5X, AV_CODEC_ID_JPEGLS, AV_CODEC_ID_MPEG4, AV_CODEC_ID_RAWVIDEO, AV_CODEC_ID_MSMPEG4V1, AV_CODEC_ID_MSMPEG4V2, AV_CODEC_ID_MSMPEG4V3, AV_CODEC_ID_WMV1, AV_CODEC_ID_WMV2, AV_CODEC_ID_H263P, AV_CODEC_ID_H263I, AV_CODEC_ID_FLV1, AV_CODEC_ID_SVQ1, AV_CODEC_ID_SVQ3, AV_CODEC_ID_DVVIDEO, AV_CODEC_ID_HUFFYUV, AV_CODEC_ID_CYUV, AV_CODEC_ID_H264, ... }
AVPixelFormat定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 enum AVPixelFormat { AV_PIX_FMT_NONE = -1, AV_PIX_FMT_YUV420P, ///< planar YUV 4:2:0, 12bpp, (1 Cr & Cb sample per 2x2 Y samples) AV_PIX_FMT_YUYV422, ///< packed YUV 4:2:2, 16bpp, Y0 Cb Y1 Cr AV_PIX_FMT_RGB24, ///< packed RGB 8:8:8, 24bpp, RGBRGB... AV_PIX_FMT_BGR24, ///< packed RGB 8:8:8, 24bpp, BGRBGR... AV_PIX_FMT_YUV422P, ///< planar YUV 4:2:2, 16bpp, (1 Cr & Cb sample per 2x1 Y samples) AV_PIX_FMT_YUV444P, ///< planar YUV 4:4:4, 24bpp, (1 Cr & Cb sample per 1x1 Y samples) AV_PIX_FMT_YUV410P, ///< planar YUV 4:1:0, 9bpp, (1 Cr & Cb sample per 4x4 Y samples) AV_PIX_FMT_YUV411P, ///< planar YUV 4:1:1, 12bpp, (1 Cr & Cb sample per 4x1 Y samples) AV_PIX_FMT_GRAY8, ///< Y , 8bpp AV_PIX_FMT_MONOWHITE, ///< Y , 1bpp, 0 is white, 1 is black, in each byte pixels are ordered from the msb to the lsb AV_PIX_FMT_MONOBLACK, ///< Y , 1bpp, 0 is black, 1 is white, in each byte pixels are ordered from the msb to the lsb AV_PIX_FMT_PAL8, ///< 8 bit with PIX_FMT_RGB32 palette AV_PIX_FMT_YUVJ420P, ///< planar YUV 4:2:0, 12bpp, full scale (JPEG), deprecated in favor of PIX_FMT_YUV420P and setting color_range AV_PIX_FMT_YUVJ422P, ///< planar YUV 4:2:2, 16bpp, full scale (JPEG), deprecated in favor of PIX_FMT_YUV422P and setting color_range AV_PIX_FMT_YUVJ444P, ///< planar YUV 4:4:4, 24bpp, full scale (JPEG), deprecated in favor of PIX_FMT_YUV444P and setting color_range AV_PIX_FMT_XVMC_MPEG2_MC,///< XVideo Motion Acceleration via common packet passing AV_PIX_FMT_XVMC_MPEG2_IDCT, ...(代码太长,略) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 enum AVSampleFormat { AV_SAMPLE_FMT_NONE = -1, AV_SAMPLE_FMT_U8, ///< unsigned 8 bits AV_SAMPLE_FMT_S16, ///< signed 16 bits AV_SAMPLE_FMT_S32, ///< signed 32 bits AV_SAMPLE_FMT_FLT, ///< float AV_SAMPLE_FMT_DBL, ///< double AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar AV_SAMPLE_FMT_FLTP, ///< float, planar AV_SAMPLE_FMT_DBLP, ///< double, planar AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically };
每一个编解码器对应一个该结构体,查看一下ffmpeg的源代码,我们可以看一下H.264解码器的结构体如下所示(h264.c):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 AVCodec ff_h264_decoder = { .name = "h264", .type = AVMEDIA_TYPE_VIDEO, .id = CODEC_ID_H264, .priv_data_size = sizeof(H264Context), .init = ff_h264_decode_init, .close = ff_h264_decode_end, .decode = decode_frame, .capabilities = /*CODEC_CAP_DRAW_HORIZ_BAND |*/ CODEC_CAP_DR1 | CODEC_CAP_DELAY | CODEC_CAP_SLICE_THREADS | CODEC_CAP_FRAME_THREADS, .flush= flush_dpb, .long_name = NULL_IF_CONFIG_SMALL("H.264 / AVC / MPEG-4 AVC / MPEG-4 part 10"), .init_thread_copy = ONLY_IF_THREADS_ENABLED(decode_init_thread_copy), .update_thread_context = ONLY_IF_THREADS_ENABLED(decode_update_thread_context), .profiles = NULL_IF_CONFIG_SMALL(profiles), .priv_class = &h264_class, };
JPEG2000解码器结构体(j2kdec.c):
1 2 3 4 5 6 7 8 9 10 11 12 13 AVCodec ff_jpeg2000_decoder = { .name = "j2k", .type = AVMEDIA_TYPE_VIDEO, .id = CODEC_ID_JPEG2000, .priv_data_size = sizeof(J2kDecoderContext), .init = j2kdec_init, .close = decode_end, .decode = decode_frame, .capabilities = CODEC_CAP_EXPERIMENTAL, .long_name = NULL_IF_CONFIG_SMALL("JPEG 2000"), .pix_fmts = (const enum PixelFormat[]) {PIX_FMT_GRAY8, PIX_FMT_RGB24, PIX_FMT_NONE} };
下面简单介绍一下遍历ffmpeg中的解码器信息的方法(这些解码器以一个链表的形式存储):
1.注册所有编解码器:av_register_all();
2.声明一个AVCodec类型的指针,比如说AVCodec* first_c;
3.调用av_codec_next()函数,即可获得指向链表下一个解码器的指针,循环往复可以获得所有解码器的信息。注意,如果想要获得指向第一个解码器的指针,则需要将该函数的参数设置为NULL。
FFmpeg 结构体(六): AVCodecContext 分析 在上文FFmpeg 结构体(五): AVCodec 分析 我们学习了AVCodec结构体的相关内容。本文,我们将讲述一下AVCodecContext。
AVCodecContext是包含变量较多的结构体(感觉差不多是变量最多的结构体)。下面我们来分析一下该结构体里重要变量的含义和作用。
源码整理 首先我们先看一下结构体AVCodecContext的定义的结构体源码(位于libavcodec/avcodec.h):
View Code
AVCodecContext 重点字段 下面挑一些关键的变量来看看(这里只考虑解码):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 enum AVMediaType codec_type:编解码器的类型(视频,音频...) struct AVCodec *codec:采用的解码器AVCodec(H.264,MPEG2...) int bit_rate:平均比特率 uint8_t *extradata; int extradata_size:针对特定编码器包含的附加信息(例如对于H.264解码器来说,存储SPS,PPS等) AVRational time_base:根据该参数,可以把PTS转化为实际的时间(单位为秒s) int width, height:如果是视频的话,代表宽和高 int refs:运动估计参考帧的个数(H.264的话会有多帧,MPEG2这类的一般就没有了) int sample_rate:采样率(音频) int channels:声道数(音频) enum AVSampleFormat sample_fmt:采样格式 int profile:型(H.264里面就有,其他编码标准应该也有) int level:级(和profile差不太多)
在这里需要注意:AVCodecContext中很多的参数是编码的时候使用的,而不是解码的时候使用的。
其实这些参数都比较容易理解。就不多费篇幅了。在这里看一下以下几个参数:
codec_type 编解码器类型有以下几种:
1 2 3 4 5 6 7 8 9 enum AVMediaType { AVMEDIA_TYPE_UNKNOWN = -1, ///< Usually treated as AVMEDIA_TYPE_DATA AVMEDIA_TYPE_VIDEO, AVMEDIA_TYPE_AUDIO, AVMEDIA_TYPE_DATA, ///< Opaque data information usually continuous AVMEDIA_TYPE_SUBTITLE, AVMEDIA_TYPE_ATTACHMENT, ///< Opaque data information usually sparse AVMEDIA_TYPE_NB };
sample_fmt 在FFMPEG中音频采样格式有以下几种:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 enum AVSampleFormat { AV_SAMPLE_FMT_NONE = -1, AV_SAMPLE_FMT_U8, ///< unsigned 8 bits AV_SAMPLE_FMT_S16, ///< signed 16 bits AV_SAMPLE_FMT_S32, ///< signed 32 bits AV_SAMPLE_FMT_FLT, ///< float AV_SAMPLE_FMT_DBL, ///< double AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar AV_SAMPLE_FMT_FLTP, ///< float, planar AV_SAMPLE_FMT_DBLP, ///< double, planar AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically };
profile 在FFMPEG中型有以下几种,可以看出AAC,MPEG2,H.264,VC-1,MPEG4都有型的概念。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 ####define FF_PROFILE_UNKNOWN -99 ####define FF_PROFILE_RESERVED -100 ####define FF_PROFILE_AAC_MAIN 0 ####define FF_PROFILE_AAC_LOW 1 ####define FF_PROFILE_AAC_SSR 2 ####define FF_PROFILE_AAC_LTP 3 ####define FF_PROFILE_AAC_HE 4 ####define FF_PROFILE_AAC_HE_V2 28 ####define FF_PROFILE_AAC_LD 22 ####define FF_PROFILE_AAC_ELD 38 ####define FF_PROFILE_DTS 20 ####define FF_PROFILE_DTS_ES 30 ####define FF_PROFILE_DTS_96_24 40 ####define FF_PROFILE_DTS_HD_HRA 50 ####define FF_PROFILE_DTS_HD_MA 60 ####define FF_PROFILE_MPEG2_422 0 ####define FF_PROFILE_MPEG2_HIGH 1 ####define FF_PROFILE_MPEG2_SS 2 ####define FF_PROFILE_MPEG2_SNR_SCALABLE 3 ####define FF_PROFILE_MPEG2_MAIN 4 ####define FF_PROFILE_MPEG2_SIMPLE 5 ####define FF_PROFILE_H264_CONSTRAINED (1<<9) // 8+1; constraint_set1_flag ####define FF_PROFILE_H264_INTRA (1<<11) // 8+3; constraint_set3_flag ####define FF_PROFILE_H264_BASELINE 66 ####define FF_PROFILE_H264_CONSTRAINED_BASELINE (66|FF_PROFILE_H264_CONSTRAINED) ####define FF_PROFILE_H264_MAIN 77 ####define FF_PROFILE_H264_EXTENDED 88 ####define FF_PROFILE_H264_HIGH 100 ####define FF_PROFILE_H264_HIGH_10 110 ####define FF_PROFILE_H264_HIGH_10_INTRA (110|FF_PROFILE_H264_INTRA) ####define FF_PROFILE_H264_HIGH_422 122 ####define FF_PROFILE_H264_HIGH_422_INTRA (122|FF_PROFILE_H264_INTRA) ####define FF_PROFILE_H264_HIGH_444 144 ####define FF_PROFILE_H264_HIGH_444_PREDICTIVE 244 ####define FF_PROFILE_H264_HIGH_444_INTRA (244|FF_PROFILE_H264_INTRA) ####define FF_PROFILE_H264_CAVLC_444 44 ####define FF_PROFILE_VC1_SIMPLE 0 ####define FF_PROFILE_VC1_MAIN 1 ####define FF_PROFILE_VC1_COMPLEX 2 ####define FF_PROFILE_VC1_ADVANCED 3 ####define FF_PROFILE_MPEG4_SIMPLE 0 ####define FF_PROFILE_MPEG4_SIMPLE_SCALABLE 1 ####define FF_PROFILE_MPEG4_CORE 2 ####define FF_PROFILE_MPEG4_MAIN 3 ####define FF_PROFILE_MPEG4_N_BIT 4 ####define FF_PROFILE_MPEG4_SCALABLE_TEXTURE 5 ####define FF_PROFILE_MPEG4_SIMPLE_FACE_ANIMATION 6 ####define FF_PROFILE_MPEG4_BASIC_ANIMATED_TEXTURE 7 ####define FF_PROFILE_MPEG4_HYBRID 8 ####define FF_PROFILE_MPEG4_ADVANCED_REAL_TIME 9 ####define FF_PROFILE_MPEG4_CORE_SCALABLE 10 ####define FF_PROFILE_MPEG4_ADVANCED_CODING 11 ####define FF_PROFILE_MPEG4_ADVANCED_CORE 12 ####define FF_PROFILE_MPEG4_ADVANCED_SCALABLE_TEXTURE 13 ####define FF_PROFILE_MPEG4_SIMPLE_STUDIO 14 ####define FF_PROFILE_MPEG4_ADVANCED_SIMPLE 15
FFmpeg 结构体(七): AVIOContext 分析 在上文FFmpeg 结构体(六): AVCodecContext 分析 我们学习了AVCodec结构体的相关内容。本文,我们将讲述一下AVIOContext。
AVIOContext是FFMPEG管理输入输出数据的结构体。下面我们来分析一下该结构体里重要变量的含义和作用。
源码整理 首先我们先看一下结构体AVIOContext的定义的结构体源码(位于libavformat/avio.h):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 /** * Bytestream IO Context. * New fields can be added to the end with minor version bumps. * Removal, reordering and changes to existing fields require a major * version bump. * sizeof(AVIOContext) must not be used outside libav*. * * @note None of the function pointers in AVIOContext should be called * directly, they should only be set by the client application * when implementing custom I/O. Normally these are set to the * function pointers specified in avio_alloc_context() */ typedef struct { /** * A class for private options. * * If this AVIOContext is created by avio_open2(), av_class is set and * passes the options down to protocols. * * If this AVIOContext is manually allocated, then av_class may be set by * the caller. * * warning -- this field can be NULL, be sure to not pass this AVIOContext * to any av_opt_* functions in that case. */ AVClass *av_class; unsigned char *buffer; /**< Start of the buffer. */ int buffer_size; /**< Maximum buffer size */ unsigned char *buf_ptr; /**< Current position in the buffer */ unsigned char *buf_end; /**< End of the data, may be less than buffer+buffer_size if the read function returned less data than requested, e.g. for streams where no more data has been received yet. */ void *opaque; /**< A private pointer, passed to the read/write/seek/... functions. */ int (*read_packet)(void *opaque, uint8_t *buf, int buf_size); int (*write_packet)(void *opaque, uint8_t *buf, int buf_size); int64_t (*seek)(void *opaque, int64_t offset, int whence); int64_t pos; /**< position in the file of the current buffer */ int must_flush; /**< true if the next seek should flush */ int eof_reached; /**< true if eof reached */ int write_flag; /**< true if open for writing */ int max_packet_size; unsigned long checksum; unsigned char *checksum_ptr; unsigned long (*update_checksum)(unsigned long checksum, const uint8_t *buf, unsigned int size); int error; /**< contains the error code or 0 if no error happened */ /** * Pause or resume playback for network streaming protocols - e.g. MMS. */ int (*read_pause)(void *opaque, int pause); /** * Seek to a given timestamp in stream with the specified stream_index. * Needed for some network streaming protocols which don't support seeking * to byte position. */ int64_t (*read_seek)(void *opaque, int stream_index, int64_t timestamp, int flags); /** * A combination of AVIO_SEEKABLE_ flags or 0 when the stream is not seekable. */ int seekable; /** * max filesize, used to limit allocations * This field is internal to libavformat and access from outside is not allowed. */ int64_t maxsize; } AVIOContext;
AVIOContext 重点字段 AVIOContext中有以下几个变量比较重要:
1 2 3 4 5 6 7 8 9 unsigned char *buffer:缓存开始位置 int buffer_size:缓存大小(默认32768) unsigned char *buf_ptr:当前指针读取到的位置 unsigned char *buf_end:缓存结束的位置 void *opaque:URLContext结构体
在解码的情况下,buffer用于存储ffmpeg读入的数据。例如打开一个视频文件的时候,先把数据从硬盘读入buffer,然后在送给解码器用于解码。
其中opaque指向了URLContext。注意,这个结构体并不在FFMPEG提供的头文件中,而是在FFMPEG的源代码中。从FFMPEG源代码中翻出的定义如下所示:
1 2 3 4 5 6 7 8 9 10 11 typedef struct URLContext { const AVClass *av_class; ///< information for av_log(). Set by url_open(). struct URLProtocol *prot; int flags; int is_streamed; /**< true if streamed (no seek possible), default = false */ int max_packet_size; /**< if non zero, the stream is packetized with this max packet size */ void *priv_data; char *filename; /**< specified URL */ int is_connected; AVIOInterruptCB interrupt_callback; } URLContext;
URLContext结构体中还有一个结构体URLProtocol。注:每种协议(rtp,rtmp,file等)对应一个URLProtocol。这个结构体也不在FFMPEG提供的头文件中。从FFMPEG源代码中翻出其的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 typedef struct URLProtocol { const char *name; int (*url_open)(URLContext *h, const char *url, int flags); int (*url_read)(URLContext *h, unsigned char *buf, int size); int (*url_write)(URLContext *h, const unsigned char *buf, int size); int64_t (*url_seek)(URLContext *h, int64_t pos, int whence); int (*url_close)(URLContext *h); struct URLProtocol *next; int (*url_read_pause)(URLContext *h, int pause); int64_t (*url_read_seek)(URLContext *h, int stream_index, int64_t timestamp, int flags); int (*url_get_file_handle)(URLContext *h); int priv_data_size; const AVClass *priv_data_class; int flags; int (*url_check)(URLContext *h, int mask); } URLProtocol;
在这个结构体中,除了一些回调函数接口之外,有一个变量const char *name,该变量存储了协议的名称。每一种输入协议都对应这样一个结构体。
比如说,文件协议中代码如下(file.c):
1 2 3 4 5 6 7 8 9 10 URLProtocol ff_file_protocol = { .name = "file", .url_open = file_open, .url_read = file_read, .url_write = file_write, .url_seek = file_seek, .url_close = file_close, .url_get_file_handle = file_get_handle, .url_check = file_check, };
libRTMP中代码如下(libRTMP.c):
1 2 3 4 5 6 7 8 9 10 11 12 URLProtocol ff_rtmp_protocol = { .name = "rtmp", .url_open = rtmp_open, .url_read = rtmp_read, .url_write = rtmp_write, .url_close = rtmp_close, .url_read_pause = rtmp_read_pause, .url_read_seek = rtmp_read_seek, .url_get_file_handle = rtmp_get_file_handle, .priv_data_size = sizeof(RTMP), .flags = URL_PROTOCOL_FLAG_NETWORK, };
udp协议代码如下(udp.c):
1 2 3 4 5 6 7 8 9 10 URLProtocol ff_udp_protocol = { .name = "udp", .url_open = udp_open, .url_read = udp_read, .url_write = udp_write, .url_close = udp_close, .url_get_file_handle = udp_get_file_handle, .priv_data_size = sizeof(UDPContext), .flags = URL_PROTOCOL_FLAG_NETWORK, };
等号右边的函数是完成具体读写功能的函数。可以看一下file协议的几个函数(其实就是读文件,写文件这样的操作)(file.c):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 /* standard file protocol */ static int file_read(URLContext *h, unsigned char *buf, int size) { int fd = (intptr_t) h->priv_data; int r = read(fd, buf, size); return (-1 == r)?AVERROR(errno):r; } static int file_write(URLContext *h, const unsigned char *buf, int size) { int fd = (intptr_t) h->priv_data; int r = write(fd, buf, size); return (-1 == r)?AVERROR(errno):r; } static int file_get_handle(URLContext *h) { return (intptr_t) h->priv_data; } static int file_check(URLContext *h, int mask) { struct stat st; int ret = stat(h->filename, &st); if (ret < 0) return AVERROR(errno); ret |= st.st_mode&S_IRUSR ? mask&AVIO_FLAG_READ : 0; ret |= st.st_mode&S_IWUSR ? mask&AVIO_FLAG_WRITE : 0; return ret; } ####if CONFIG_FILE_PROTOCOL static int file_open(URLContext *h, const char *filename, int flags) { int access; int fd; av_strstart(filename, "file:", &filename); if (flags & AVIO_FLAG_WRITE && flags & AVIO_FLAG_READ) { access = O_CREAT | O_TRUNC | O_RDWR; } else if (flags & AVIO_FLAG_WRITE) { access = O_CREAT | O_TRUNC | O_WRONLY; } else { access = O_RDONLY; } ####ifdef O_BINARY access |= O_BINARY; ####endif fd = open(filename, access, 0666); if (fd == -1) return AVERROR(errno); h->priv_data = (void *) (intptr_t) fd; return 0; } /* XXX: use llseek */ static int64_t file_seek(URLContext *h, int64_t pos, int whence) { int fd = (intptr_t) h->priv_data; if (whence == AVSEEK_SIZE) { struct stat st; int ret = fstat(fd, &st); return ret < 0 ? AVERROR(errno) : st.st_size; } return lseek(fd, pos, whence); } static int file_close(URLContext *h) { int fd = (intptr_t) h->priv_data; return close(fd); }
FFmpeg 结构体(八):FFMPEG中重要结构体之间的关系 FFMPEG中结构体很多。最关键的结构体可以分成以下几类:
解协议(http,rtsp,rtmp,mms) AVIOContext,URLProtocol,URLContext主要存储视音频使用的协议的类型以及状态。URLProtocol存储输入视音频使用的封装格式。每种协议都对应一个URLProtocol结构。
解封装(flv,avi,rmvb,mp4) AVFormatContext主要存储视音频封装格式中包含的信息;AVInputFormat存储输入视音频使用的封装格式。每种视音频封装格式都对应一个AVInputFormat 结构。
解码(h264,mpeg2,aac,mp3) 每个AVStream存储一个视频/音频流的相关数据;每个AVStream对应一个AVCodecContext,存储该视频/音频流使用解码方式的相关数据;每个AVCodecContext中对应一个AVCodec,包含该视频/音频对应的解码器。每种解码器都对应一个AVCodec结构。
存数据 视频的话,每个结构一般是存一帧;音频可能有好几帧
解码前数据:AVPacket
解码后数据:AVFrame
他们之间的对应关系如下所示:
FFmpeg 开发之 AVFilter 使用流程总结 在使用FFmpeg开发时,使用AVFilter的流程较为复杂,涉及到的数据结构和函数也比较多,那么使用FFmpeg AVFilter的整体流程是什么样,在其执行过程中都有哪些步骤,需要注意哪些细节?这些都是需要我们整理和总结的。
首先,我们需要引入三个概念结构体:AVFilterGraph 、AVFilterContext、AVFilter。
AVFilterGraph 、AVFilterContext、AVFilter 在 FFmpeg 中有多种多样的滤镜,你可以把他们当成一个个小工具,专门用于处理视频和音频数据,以便实现一定的目的。如 overlay 这个滤镜,可以将一个图画覆盖到另一个图画上;transport 这个滤镜可以将图画做旋转等等。
一个 filter 的输出可以作为另一个 filter 的输入,因此多个 filter 可以组织成为一个网状的 filter graph,从而实现更加复杂或者综合的任务。
在 libavfilter 中,我们用类型 AVFilter 来表示一个 filter,每一个 filter 都是经过注册的,其特性是相对固定的。而 AVFilterContext 则表示一个真正的 filter 实例,这和 AVCodec 以及 AVCodecContext 的关系是类似的。
AVFilter 中最重要的特征就是其所需的输入和输出。
AVFilterContext 表示一个 AVFilter 的实例,我们在实际使用 filter 时,就是使用这个结构体。AVFilterContext 在被使用前,它必须是 被初始化的,就是需要对 filter 进行一些选项上的设置,通过初始化告诉 FFmpeg 我们已经做了相关的配置。
AVFilterGraph 表示一个 filter graph,当然它也包含了 filter chain的概念。graph 包含了诸多 filter context 实例,并负责它们之间的 link,graph 会负责创建,保存,释放 这些相关的 filter context 和 link,一般不需要用户进行管理。除此之外,它还有线程特性和最大线程数量的字段,和filter context类似。graph 的操作有:分配一个graph,往graph中添加一个filter context,添加一个 filter graph,对 filter 进行 link 操作,检查内部的link和format是否有效,释放graph等。
AVFilter 相关Api使用方法整理 AVFilterContext 初始化方法 AVFilterContext 的初始化方式有三种,avfilter_init_str() 和 avfilter_init_dict()、avfilter_graph_create_filter().
1 2 3 4 5 6 7 /* 使用提供的参数初始化 filter。 参数args:表示用于初始化 filter 的 options。该字符串必须使用 ":" 来分割各个键值对, 而键值对的形式为 'key=value'。如果不需要设置选项,args为空。 除了这种方式设置选项之外,还可以利用 AVOptions API 直接对 filter 设置选项。 返回值:成功返回0,失败返回一个负的错误值 */ int avfilter_init_str(AVFilterContext *ctx, const char *args);
1 2 3 4 5 6 7 /* 使用提供的参数初始化filter。 参数 options:以 dict 形式提供的 options。 返回值:成功返回0,失败返回一个负的错误值 注意:这个函数和 avfilter_init_str 函数的功能是一样的,只不过传递的参数形式不同。 但是当传入的 options 中有不被 filter 所支持的参数时,这两个函数的行为是不同: avfilter_init_str 调用会失败,而这个函数则不会失败,它会将不能应用于指定 filter 的 option 通过参数 options 返回,然后继续执行任务。 */ int avfilter_init_dict(AVFilterContext *ctx, AVDictionary **options);
1 2 3 4 5 6 /** * 创建一个Filter实例(根据args和opaque的参数),并添加到已存在的AVFilterGraph. * 如果创建成功*filt_ctx会指向一个创建好的Filter实例,否则会指向NULL. * @return 失败返回负数,否则返回大于等于0的数 */ int avfilter_graph_create_filter(AVFilterContext **filt_ctx, const AVFilter *filt, const char *name, const char *args, void *opaque, AVFilterGraph *graph_ctx);
AVFilterGraph 相关的Api AVFilterGraph 表示一个 filter graph,当然它也包含了 filter chain的概念。graph 包含了诸多 filter context 实例,并负责它们之间的 link,graph 会负责创建,保存,释放 这些相关的 filter context 和 link,一般不需要用户进行管理。
graph 的操作有:分配一个graph,往graph中添加一个filter context,添加一个 filter graph,对 filter 进行 link 操作,检查内部的link和format是否有效,释放graph等。
根据上述操作,可以列举的方法分别为:
分配空的filter graph:
1 2 3 4 5 /* 分配一个空的 filter graph. 成功返回一个 filter graph,失败返回 NULL */ AVFilterGraph *avfilter_graph_alloc(void);
创建一个新的filter实例:
1 2 3 4 5 6 7 /* 在 filter graph 中创建一个新的 filter 实例。这个创建的实例尚未初始化。 详细描述:在 graph 中创建一个名称为 name 的 filter类型的实例。 创建失败,返回NULL。创建成功,返回 filter context实例。创建成功后的实例会加入到graph中, 可以通过 AVFilterGraph.filters 或者 avfilter_graph_get_filter() 获取。 */ AVFilterContext *avfilter_graph_alloc_filter(AVFilterGraph *graph, const AVFilter *filter, const char *name);
返回名字为name的filter context:
1 2 3 4 5 /* 返回 graph 中的名为 name 的 filter context。 */ AVFilterContext *avfilter_graph_get_filter(AVFilterGraph *graph, const char *name);
在 filter graph 中创建一个新的 filter context 实例,并使用args和opaque初始化这个filter context:
1 2 3 4 5 6 7 8 /* 在 filter graph 中创建一个新的 filter context 实例,并使用 args 和 opaque 初始化这个实例。 参数 filt_ctx:返回成功创建的 filter context 返回值:成功返回正数,失败返回负的错误值。 */ int avfilter_graph_create_filter(AVFilterContext **filt_ctx, const AVFilter *filt, const char *name, const char *args, void *opaque, AVFilterGraph *graph_ctx);
配置 AVFilterGraph 的链接和格式:
1 2 3 4 5 /* 检查 graph 的有效性,并配置其中所有的连接和格式。 有效则返回 >= 0 的数,否则返回一个负值的 AVERROR. */ int avfilter_graph_config(AVFilterGraph *graphctx, void *log_ctx);
释放AVFilterGraph:
1 2 3 4 /* 释放graph,摧毁内部的连接,并将其置为NULL。 */ void avfilter_graph_free(AVFilterGraph **graph);
在一个已经存在的link中插入一个FilterContext:
1 2 3 4 5 6 /* 在一个已经存在的 link 中间插入一个 filter context。 参数filt_srcpad_idx和filt_dstpad_idx:指定filt要连接的输入和输出pad的index。 成功返回0. */ int avfilter_insert_filter(AVFilterLink *link, AVFilterContext *filt, unsigned filt_srcpad_idx, unsigned filt_dstpad_idx);
将字符串描述的filter graph 加入到一个已存在的graph中:
1 2 3 4 5 6 7 8 9 10 11 12 13 /* 将一个字符串描述的 filter graph 加入到一个已经存在的 graph 中。 注意:调用者必须提供 inputs 列表和 outputs 列表。它们在调用这个函数之前必须是已知的。 注意:inputs 参数用于描述已经存在的 graph 的输入 pad 列表,也就是说,从新的被创建的 graph 来讲,它们是 output。 outputs 参数用于已经存在的 graph 的输出 pad 列表,从新的被创建的 graph 来说,它们是 input。 成功返回 >= 0,失败返回负的错误值。 */ int avfilter_graph_parse(AVFilterGraph *graph, const char *filters, AVFilterInOut *inputs, AVFilterInOut *outputs, void *log_ctx);
1 2 3 4 5 6 7 8 9 10 11 12 /* 和 avfilter_graph_parse 类似。不同的是 inputs 和 outputs 参数,即做输入参数,也做输出参数。 在函数返回时,它们将会保存 graph 中所有的处于 open 状态的 pad。返回的 inout 应该使用 avfilter_inout_free() 释放掉。 注意:在字符串描述的 graph 中,第一个 filter 的输入如果没有被一个字符串标识,默认其标识为"in",最后一个 filter 的输出如果没有被标识,默认为"output"。 intpus:作为输入参数是,用于保存已经存在的graph的open inputs,可以为NULL。 作为输出参数,用于保存这个parse函数之后,仍然处于open的inputs,当然如果传入为NULL,则并不输出。 outputs:同上。 */ int avfilter_graph_parse_ptr(AVFilterGraph *graph, const char *filters, AVFilterInOut **inputs, AVFilterInOut **outputs, void *log_ctx);
1 2 3 4 5 6 7 8 9 /* 和 avfilter_graph_parse_ptr 函数类似,不同的是,inputs 和 outputs 函数不作为输入参数, 仅作为输出参数,返回字符串描述的新的被解析的graph在这个parse函数后,仍然处于open状态的inputs和outputs。 返回的 inout 应该使用 avfilter_inout_free() 释放掉。 成功返回0,失败返回负的错误值。 */ int avfilter_graph_parse2(AVFilterGraph *graph, const char *filters, AVFilterInOut **inputs, AVFilterInOut **outputs);
将graph转换为可读取的字符串描述:
1 2 3 4 5 /* 将 graph 转化为可读的字符串描述。 参数options:未使用,忽略它。 */ char *avfilter_graph_dump(AVFilterGraph *graph, const char *options);
FFmpeg Filter Buffer 和 BufferSink 相关APi的使用方法整理 Buffer 和 BufferSink 作为 graph 的输入点和输出点来和我们交互,我们仅需要和其进行数据交互即可。其API如下:
1 2 3 4 5 6 7 8 9 10 11 12 //buffersrc flag enum { //不去检测 format 的变化 AV_BUFFERSRC_FLAG_NO_CHECK_FORMAT = 1, //立刻将 frame 推送到 output AV_BUFFERSRC_FLAG_PUSH = 4, //对输入的frame新建一个引用,而非接管引用 //如果 frame 是引用计数的,那么对它创建一个新的引用;否则拷贝frame中的数据 AV_BUFFERSRC_FLAG_KEEP_REF = 8, };
向 buffer_src 添加一个Frame:
1 2 3 4 5 6 7 8 9 10 /* 向 buffer_src 添加一个 frame。 默认情况下,如果 frame 是引用计数的,那么这个函数将会接管其引用并重新设置 frame。 但这个行为可以由 flags 来控制。如果 frame 不是引用计数的,那么拷贝该 frame。 如果函数返回一个 error,那么 frame 并未被使用。frame为NULL时,表示 EOF。 成功返回 >= 0,失败返回负的AVERROR。 */ int av_buffersrc_add_frame_flags(AVFilterContext *buffer_src, AVFrame *frame, int flags);
添加一个frame到 src filter:
1 2 3 4 5 /* 添加一个 frame 到 src filter。 这个函数等同于没有 AV_BUFFERSRC_FLAG_KEEP_REF 的 av_buffersrc_add_frame_flags() 函数。 */ int av_buffersrc_add_frame(AVFilterContext *ctx, AVFrame *frame);
1 2 3 4 5 /* 添加一个 frame 到 src filter。 这个函数等同于设置了 AV_BUFFERSRC_FLAG_KEEP_REF 的av_buffersrc_add_frame_flags() 函数。 */ int av_buffersrc_write_frame(AVFilterContext *ctx, const AVFrame *frame);
从sink获取已filtered处理的帧,并放到参数frame中:
1 2 3 4 5 6 7 8 9 10 /* 从 sink 中获取已进行 filtered 处理的帧,并将其放到参数 frame 中。 参数ctx:指向 buffersink 或 abuffersink 类型的 filter context 参数frame:获取到的被处理后的frame,使用后必须使用av_frame_unref() / av_frame_free()释放掉它 成功返回非负数,失败返回负的错误值,如 EAGAIN(表示需要新的输入数据来产生filter后的数据), AVERROR_EOF(表示不会再有新的输入数据) */ int av_buffersink_get_frame_flags(AVFilterContext *ctx, AVFrame *frame, int flags);
1 2 3 4 /* 同 av_buffersink_get_frame_flags ,不过不能指定 flag。 */ int av_buffersink_get_frame(AVFilterContext *ctx, AVFrame *frame)
1 2 3 4 /* 和 av_buffersink_get_frame 相同,不过这个函数是针对音频的,而且可以指定读取的取样数。此时 ctx 只能指向 abuffersink 类型的 filter context。 */ int av_buffersink_get_samples(AVFilterContext *ctx, AVFrame *frame, int nb_samples);
FFmpeg AVFilter 使用整体流程 下图就是FFmpeg AVFilter在使用过程中的流程图:
我们对上图先做下说明,理解下图中每个步骤的关系,然后,才从代码的角度来给出其使用的步骤。
最顶端的AVFilterGraph,这个结构前面介绍过,主要管理加入的过滤器,其中加入的过滤器就是通过函数avfilter_graph_create_filter来创建并加入,这个函数返回是AVFilterContext(其封装了AVFilter的详细参数信息)。
buffer和buffersink这两个过滤器是FFMpeg为我们实现好的,buffer表示源,用来向后面的过滤器提供数据输入(其实就是原始的AVFrame);buffersink过滤器是最终输出的(经过过滤器链处理后的数据AVFrame),其它的诸如filter 1 等过滤器是由avfilter_graph_parse_ptr函数解析外部传入的过滤器描述字符串自动生成的,内部也是通过avfilter_graph_create_filter来创建过滤器的。
上面的buffer、filter 1、filter 2、filter n、buffersink之间是通过avfilter_link函数来进行关联的(通过AVFilterLink结构),这样子过滤器和过滤器之间就通过AVFilterLink进行关联上了,前一个过滤器的输出就是下一个过滤器的输入,注意,除了源和接收过滤器之外,其它的过滤器至少有一个输入和输出,这很好理解,中间的过滤器处理完AVFrame后,得到新的处理后的AVFrame数据,然后把新的AVFrame数据作为下一个过滤器的输入。
过滤器建立完成后,首先我们通过av_buffersrc_add_frame把最原始的AVFrame(没有经过任何过滤器处理的)加入到buffer过滤器的fifo队列。
然后调用buffersink过滤器的av_buffersink_get_frame_flags来获取处理完后的数据帧(这个最终放入buffersink过滤器的AVFrame是通过之前创建的一系列过滤器处理后的数据)。
使用流程图就介绍到这里,下面结合上面的使用流程图详细说下FFMpeg中使用过滤器的步骤,这个过程我们分为三个部分:过滤器构建、数据加工、资源释放。
过滤器构建: 1)分配AVFilterGraph
1 AVFilterGraph* graph = avfilter_graph_alloc();
2)创建过滤器源
1 2 3 4 char srcArgs[256] = {0}; AVFilterContext *srcFilterCtx; AVFilter* srcFilter = avfilter_get_by_name("buffer"); avfilter_graph_create_filter(&srcFilterCtx, srcFilter ,"out_buffer", srcArgs, NULL, graph);
3)创建接收过滤器
1 2 3 AVFilterContext *sinkFilterCtx; AVFilter* sinkFilter = avfilter_get_by_name("buffersink"); avfilter_graph_create_filter(&sinkFilterCtx, sinkFilter,"in_buffersink", NULL, NULL, graph);
4)生成源和接收过滤器的输入输出
这里主要是把源和接收过滤器封装给AVFilterInOut结构,使用这个中间结构来把过滤器字符串解析并链接进graph,主要代码如下:
1 2 3 4 5 6 7 8 9 10 AVFilterInOut *inputs = avfilter_inout_alloc(); AVFilterInOut *outputs = avfilter_inout_alloc(); outputs->name = av_strdup("in"); outputs->filter_ctx = srcFilterCtx; outputs->pad_idx = 0; outputs->next = NULL; inputs->name = av_strdup("out"); inputs->filter_ctx = sinkFilterCtx; inputs->pad_idx = 0; inputs->next = NULL;
这里源对应的AVFilterInOut的name最好定义为in,接收对应的name为out,因为FFMpeg源码里默认会通过这样个name来对默认的输出和输入进行查找。
5)通过解析过滤器字符串添加过滤器
1 2 const *char filtergraph = "[in1]过滤器名称=参数1:参数2[out1]"; int ret = avfilter_graph_parse_ptr(graph, filtergraph, &inputs, &outputs, NULL);
这里过滤器是以字符串形式描述的,其格式为:[in]过滤器名称=参数[out],过滤器之间用,或;分割,如果过滤器有多个参数,则参数之间用:分割,其中[in]和[out]分别为过滤器的输入和输出,可以有多个。
6)检查过滤器的完整性
1 avfilter_graph_config(graph, NULL);
数据加工 1)向源过滤器加入AVFrame
1 2 AVFrame* frame; // 这是解码后获取的数据帧 int ret = av_buffersrc_add_frame(srcFilterCtx, frame);
2)从buffersink接收处理后的AVFrame
1 int ret = av_buffersink_get_frame_flags(sinkFilterCtx, frame, 0);
现在我们就可以使用处理后的AVFrame,比如显示或播放出来。
资源释放 使用结束后,调用avfilter_graph_free(&graph);释放掉AVFilterGraph类型的graph。
FFmpeg 过时 Api 汇总整理 在学习和使用FFmpeg的时候,我们经常会去查找很多资料并加以实践,但是目前存在一个问题困扰着不少刚接触音视频的同学,那就是FFmpeg的弃用API如何调整。
下面是相关的API的汇总:
AVStream::codec: 被声明为已否决 旧版本:
1 2 3 if(pFormatCtx->streams[i]->codec->codec_type==AVMEDIA_TYPE_VIDEO){ ... pCodecCtx = pFormatCtx->streams[videoIndex]->codec;
新版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 if(pFormatCtx->streams[i]->codecpar->codec_type==AVMEDIA_TYPE_VIDEO){ ... pCodecCtx = avcodec_alloc_context3(NULL); if (pCodecCtx == NULL) { printf("Could not allocate AVCodecContext \n"); return -1; } if (pFormatCtx->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_VIDEO) { printf("Couldn't find audio stream information \n"); return -1; } avcodec_parameters_to_context(pCodecCtx, pFormatCtx->streams[videoIndex]->codecpar);
avcodec_encode_audio2:被声明为已否决 旧版本:
1 if (avcodec_encode_audio2(tmpAvCodecCtx, &pkt_out, frame, &got_picture) < 0)
新版本:
1 if(avcodec_send_frame(tmpAvCodecCtx, frame)<0 || (got_picture=avcodec_receive_packet(tmpAvCodecCtx, &pkt_out))<0)
‘avpicture_get_size’: 被声明为已否决 旧版本:
1 avpicture_get_size(AV_PIX_FMT_YUV420P, pCodecCtx->width, pCodecCtx->height)
新版本:
1 2 #include "libavutil/imgutils.h" av_image_get_buffer_size(AV_PIX_FMT_YUV420P, pCodecCtx->width, pCodecCtx->height, 1)
‘avpicture_fill’: 被声明为已否决 1 2 旧版本: avpicture_fill((AVPicture *)pFrameYUV, out_buffer, AV_PIX_FMT_YUV420P, pCodecCtx->width, pCodecCtx->height);
新版本:
1 av_image_fill_arrays(pFrameYUV->data, pFrameYUV->linesize, out_buffer, AV_PIX_FMT_YUV420P, pCodecCtx->width, pCodecCtx->height, 1);
‘avcodec_decode_video2’: 被声明为已否决 旧版本:
1 ret = avcodec_decode_video2(pCodecCtx, pFrame, &got_picture, packet);
新版本:
1 if(avcodec_send_packet(pCodecCtx, packet)<0 || (got_picture =avcodec_receive_frame(pCodecCtx, pFrame))<0) {return -1}
‘ avcodec_alloc_frame’: 被声明为已否决 旧版本:
1 pFrame = avcodec_alloc_frame();
新版本:
1 pFrame = av_frame_alloc();
‘av_free_packet’: 被声明为已否决 旧版本:
新版本:
1 av_packet_unref(packet);
avcodec_decode_audio4:被声明为已否决 旧版本:
1 int avcodec_decode_audio4(AVCodecContext *avctx, AVFrame *frame, int *got_frame, const AVPacket *avpkt);
新版本:
1 if(avcodec_send_packet(pCodecCtxOut_Video, &pkt)<0 || (got_frame=avcodec_receive_frame(pCodecCtxOut_Video,picture))<0) {return -1}
avcodec_encode_video2:被声明为已否决 旧版本:
1 if(avcodec_encode_video2(tmpAvCodecCtx, &pkt, picture, &got_picture)<0)
新版本:
1 if(avcodec_send_frame(tmpAvCodecCtx, picture)<0 || (got_picture=avcodec_receive_packet(tmpAvCodecCtx, &pkt))<0)
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 nathanwriting@126.com